

Abzock-Zeitschriften, Datenauswertung Teil 1: Methoden, Ländervergleich, Gesamtzahl
BLOG: RELATIV EINFACH

In den letzten Tagen hat eine mehrmonatige Recherche von NDR, WDR und SZ-Magazin in Zusammenarbeit mit ausländischen Partnern das Thema wissenschaftliche Abzock-Zeitschriften und Abzock-Konferenzen in Deutschland auf die Tagesordnung gebracht. Links zu den verschiedenen Berichten finden sich in diesem NDR-Dossier. Zur Erinnerung: Abzock-Fachzeitschriften, auch “predatory journals” genannt, sind selbsternannte wissenschaftliche Fachzeitschriften, die zwar vorgeben, den üblichen Qualitätsstandards des “Peer review” zu folgen, aber die in Wirklichkeit gegen Gebühr jeden Mist veröffentlichen. Parallel dazu geht es um Abzock-Konferenzen: vorgeblich wissenschaftliche Konferenzen ohne nennenswerte Qualitätsstandards, deren Geschäftsmodell entsprechend darin besteht, die Teilnahmegebühren einzustreichen.
In der Berichterstattung der letzten Tage macht insbesondere eine Zahl die Runde: 5000 deutsche Wissenschaftler, an anderer Stelle 5000-6000, sollen in solchen Abzock-Journalen veröffentlicht und/oder solche Abzock-Konferenzen besucht haben. Problematisch nicht zuletzt, weil dafür Steuergelder eingesetzt wurden – und auch ob der Frage, inwieweit das der Glaubwürdigkeit der Wissenschaft schadet.
Fragen über Fragen
Wie diese Zahl zustandekommt, habe ich noch nicht herausgefunden. In der Hinsicht war die Berichterstattung leider bislang eher nicht sehr transparent. Gestern hatte ich in Abzock-Fachzeitschriften – wie groß ist das Problem? versucht, per Hand eine Stichprobe bei dem im Zusammenhang mit den Recherchen genannten Verlag Scientific Research Publishing (SCIRP) auszuwerten. In der Wissenschaft wäre das so etwas wie eine Vorstudie: Ein eher unsystematisches Durchforsten der Daten, mit dem Ziel, einen Überblick zu gewinnen und sich überhaupt erst einmal klar zu werden, was die interessanten Forschungsfragen sind.
In meinem Fall kamen mehrere Fragen heraus, die ich für interessant halte: Wie ist es im Ländervergleich? Ein Teil der Berichterstattung bescheinigt Deutschland schließlich sogar eine “Schlüsselrolle” in diesem “zwielichtigen Geschäft” – kann man das anhand der Daten nachvollziehen? Aus welchen Institutionen kommen die Artikel? Welche Rolle spielt die Interdisziplinarität? Hypothese zu letzterer Fragen: Sitzen Wissenschaftler insbesondere in anderen als ihren eigenen Fachgebieten Fake-Zeitschriften auf?
In meiner 1%-Stichprobe war außerdem auffällig, dass so gut wie nur angewandte Wissenschaften betroffen waren. Die Artikel kamen vor allem aus der Tierforschung, der Ökologie, Agrarwissenschaft, Medizin. Auch das ist natürlich wichtig. Denn in denjenigen Teilen der Berichterstattung, die ich bislang gesehen habe, ist jeweils pauschal von “der Wissenschaft” die Rede. Wenn ganz systematisch nur bestimmte Teilgebiete betroffen sind, dann ist das erstens für das Verständnis der Hintergründe wichtig – offenbar spielt da etwas eine Rolle, in dem sich jene Wissenschaften von den anderen unterscheiden. Zweitens verzerrt es natürlich das Bild ganz gehörig, wenn von einem Teilbereich auf die Wissenschaft als Ganzes verallgemeinert wird.
Transparente Wissenschaft: mehr als nur Peer Review
Ein Einschub: Aus meiner Sicht macht es sich die Berichterstattung bei der Beschreibung von wissenschaftlichen Arbeiten, die in Fachzeitschriften mit Gutachter-Verfahren (Peer Review) veröffentlicht werden, zu einfach. Viel wichtiger wäre in heutiger Zeit, dass wissenschaftliche Arbeiten so veröffentlicht werden, dass sie transparent und nachvollziehbar sind. Dazu reicht ein üblicher Fachartikel mit Text, Bildern, und Daten in gesetzten Tabellen nicht aus. Viel wichtiger wäre, bei der Veröffentlichung wissenschaftlicher Ergebnisse Strukturen zu schaffen, die die Möglichkeiten digitaler Arbeitsweise voll ausnutzen. Im Idealfall könnte jeder zu jeder wissenschaftlichen Veröffentlichung eine große komprimierte Datei herunterladen, die sich auf dem heimischen Rechner (oder einem geeigneten Online-Portal) entpacken lässt und dann alle in die Veröffentlichung eingeflossenen Daten, alle Auswertungsschritte, alle verwendete Software zugänglich macht. So wäre Wissenschaft wirklich transparent.
Ganz den Idealfall kann ich hier nicht bieten, aber zumindest wer die gängigen Programmiersprachen Python (Version 3.x) und Perl auf seinem Computer installiert hat, sollte alles selbst nachvollziehen können, was ich hier tue. Meine Auswertungsschritte habe ich hier als komprimierte Datei zusammengefasst:
Materialpaket: ZIP-Datei mit Skripten (2.7 MB, via Dropbox)
Die Daten selbst sind zu groß, als dass ich sie direkt zum Download bereitstellen kann; wer die Skripte laufen lässt, kann aber genau reproduzieren was ich wo und wie heruntergeladen und analysiert habe. Die Skripte sind zumindest einigermaßen dokumentiert; wer die beiden Programmiersprachen kennt, sollte daran einigermaßen sehen, was ich da gemacht habe und warum.
Daten schürfen
Um die eingangs gestellten Fragen beantworten zu können, benötige ich Daten – und zwar mehr, als ich per Hand heraussuchen kann. Glücklicherweise sind die Artikel der SCIRP-Webseite einfach automatisch herunterzuladen – wie es aussieht hat jede Seite das Format http://www.scirp.org/journal/PaperInformation.aspx?PaperID=86018 mit jeweils anderer Nummer für die PaperID. Ein Python-Skript (download-scirp.py) lädt mir die letzten 17500 SCIRP-Artikel herunter, von PaperID=68589 bis 86066. Der erste Artikel der Stichprobe erschien am 1. September 2015, der letzte am 19. Juli 2018. Das entspricht einem Zeitraum von 1052 Tagen bzw. 2.88 Jahren.
Mein Skript lädt jeden dieser Artikel als Textdatei in das Verzeichnis SCIRPArticles, Gesamtgröße 2.54 GB. Das sind im Vergleich zu den “mehr als 175 000” Artikeln, die für die Recherche von NDR et al. ausgewertet wurden, rund 10 Prozent; damit sollte meine Auswertung schon einigermaßen belastbar sein.
Über diese Artikel lasse ich ein Perl-Skript laufen um Autoren und Affiliationen herauszubekommen. Auch diesen Teil hätte ich vermutlich mit Python machen können, aber da es da viel darum geht, Muster zu erkennen, um aus jeder Artikelseite die Autoren und ihre Affiliationen herauszuziehen, und da die Programmiersprache Perl (Stichwort “Regular Expressions”) sehr gut in genau solcher Arbeit ist, habe ich meine Perl-Kenntnisse abgestaubt, mich wieder an Semikolons hinter jeder Zeile gewöhnt und die Auswertung als Perl-Skript (im Materialpaket getSCIRPinfo.pl) geschrieben. Die beim Durchlauf automatisch erzeugte Testdatei, an der ich beim Programmieren immer wieder geprüft habe, ob das Programm tut, was es soll, ist ebenfalls Teil des Pakets (articleInfos.html) und kann mit einem normalen Browser geöffnet werden. Das Perl-Skript schreibt außerdem noch weitere Daten in Textdateien, die dann zum Erzeugen der Diagramme in diesem Blogbeitrag genutzt wurden; das Python-Skript, das die Diagramme erzeugt, ist ebenfalls Teil des Materialpakets (pp-diagramme.py).
Nationalitäten
Fangen wir mit einer einfachen Frage an: Wie häufig sind verschiedene Länder unter den 17500 Artikeln vertreten? (“vertreten sein” heißt: mindestens ein Autor des Artikels gibt ein Institut oder eine andere Affiliation des betreffenden Landes an). Ich habe das zumindest für eine Auswahl von Ländern überprüft. Die entsprechenden Daten (auf dem Umweg über die automatisch erzeugte Datei nationalitaeten.csv) sind hier als Balkendiagramm dargestellt:
 Einen besonders großen Anteil hat Deutschland mit seinen 2.5% da nicht, liegt aber immerhin z.B. noch vor meinen anderen europäischen Beispielen. Auf der Suche nach einer vernünftigen relativen Größe komme ich auf diese Seite der OECD, die angibt, wieviele Forscher/innen es in verschiedenen Ländern gibt. Das ergibt ein weiteres Balkendiagramm, “Anzahl von Artikeln des Landes in der Stichprobe, geteilt durch Forscher-Gesamtzahl”, das einen Hinweis darauf geben sollte, in welchen Ländern Publizieren in Predatory Journals häufiger ist als in anderen.
Einen besonders großen Anteil hat Deutschland mit seinen 2.5% da nicht, liegt aber immerhin z.B. noch vor meinen anderen europäischen Beispielen. Auf der Suche nach einer vernünftigen relativen Größe komme ich auf diese Seite der OECD, die angibt, wieviele Forscher/innen es in verschiedenen Ländern gibt. Das ergibt ein weiteres Balkendiagramm, “Anzahl von Artikeln des Landes in der Stichprobe, geteilt durch Forscher-Gesamtzahl”, das einen Hinweis darauf geben sollte, in welchen Ländern Publizieren in Predatory Journals häufiger ist als in anderen.
Die Zahlen nehme ich von der OECD; Details (und eine für die USA und Kanada nötige Extrapolation) stehen in der Datei pp-diagramme.py. Da die Kennzahlen unübersichtlich klein sind, habe ich noch einen Faktor 1000 eingeführt – für den Vergleich der Zahlen untereinander macht der keinen Unterschied. So sieht das Ergebnis aus:
 Deutschland liegt in etwa gleichauf mit dem Vereinigten Königreich, Frankreich, Russland und den Niederlanden. Die Schweden scheinen im Vergleich zu den anderen Nationen ein größeres Problem zu haben. Schweden, Kanada, China und Japan liegen vorne. In der Schweiz scheint die Veröffentlichungsrate ebenfalls etwas höher zu liegen; dem dortigen Predatory-Publishing-Problem hatte sich Anfang des Jahre übrigens ein sehr schöner Artikel in der NZZ am Sonntag gewidmet.
Deutschland liegt in etwa gleichauf mit dem Vereinigten Königreich, Frankreich, Russland und den Niederlanden. Die Schweden scheinen im Vergleich zu den anderen Nationen ein größeres Problem zu haben. Schweden, Kanada, China und Japan liegen vorne. In der Schweiz scheint die Veröffentlichungsrate ebenfalls etwas höher zu liegen; dem dortigen Predatory-Publishing-Problem hatte sich Anfang des Jahre übrigens ein sehr schöner Artikel in der NZZ am Sonntag gewidmet.
Für die Aussage, “Deutschland [nehme] in diesem zwielichtigen Geschäft offenbar eine Schlüsselrolle ein” (so die Sueddeutsche in einem Bericht zu dem Rechercheprojekt) finde ich in meiner Stichprobe keine Belege. Deutschland liegt im europäischen Durchschnitt, sticht damit nicht besonders heraus und trägt zur Gesamtzahl der hier ausgewerteten Artikel wie gesagt nur 2.5% bei.
Das heißt natürlich nicht, dass es unwichtig wäre, das Problem auch hier in Deutschland anzupacken. Aber es ist für die Einordnung wichtig. Wenn das in Kanada erscheinende Magazin “The Scientist” die Rechercheergebnisse von NDR & Co. berichtet mit “German Scientists publish in predatory journals”, dann ist das wörtlich genommen nicht falsch. Aber es lässt unter den Tisch fallen, dass z.B. Kanada dem obigen Kennzahl-Diagramm nach noch ein deutlich größeres Problem zu haben scheint.
Artikel und Autoren
In meiner Stichprobe mit 17500 Artikeln sind 443 Artikel, bei denen mindestens ein Koautor eine deutsche Affiliation (Institut etc.) besitzt. Insgesamt sind 906 Autor/innen mit deutscher Affiliation beteiligt – einige durchaus mehrmals, wie das folgende Diagramm zeigt:
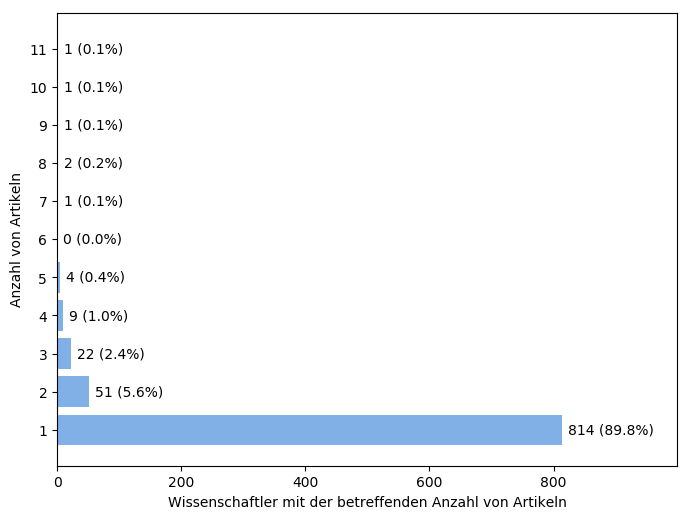 Da sieht man bereits: die allermeisten Autoren tauchen in meiner Artikelstichprobe nur ein einziges Mal auf. Zumindest im Auswertungszeitraum von knapp 3 Jahren sind die allermeisten Autoren keine Serienveröffentlicher in den hier ausgewählten Zeitschriften. Interessant ist allerdings die Spitzengruppe: ganze 6 Autoren mit je sieben Artikeln oder mehr in der Stichprobe waren bei insgesamt 53 Artikeln mit dabei. Sofern sich da keine Autorenschaft überschneidet, wären das stolze 12% der Artikel mit deutscher Beteiligung alleine aufgrund dieser “Spitzengruppe”.
Da sieht man bereits: die allermeisten Autoren tauchen in meiner Artikelstichprobe nur ein einziges Mal auf. Zumindest im Auswertungszeitraum von knapp 3 Jahren sind die allermeisten Autoren keine Serienveröffentlicher in den hier ausgewählten Zeitschriften. Interessant ist allerdings die Spitzengruppe: ganze 6 Autoren mit je sieben Artikeln oder mehr in der Stichprobe waren bei insgesamt 53 Artikeln mit dabei. Sofern sich da keine Autorenschaft überschneidet, wären das stolze 12% der Artikel mit deutscher Beteiligung alleine aufgrund dieser “Spitzengruppe”.
[Update 23.7.2018: Raphael Wimmer kommt mit einer Schnell-Analyse von WASET zu ähnlichen Ergebnissen: Viele Einmal-Veröffentlicher, wenige Vielschreiber.]
Skaliere ich die Stichprobe mit dem Faktor 10, um von meiner Stichprobengröße von 17500 auf die zehn Mal größere Stichprobe von NDR et al. zu kommen, dann erhalte ich also sogar noch die größere Zahl von schätzungsweise rund 9000 betroffenen deutschen Wissenschaftlern.
Relative Größen
Einem wie großen Anteil am gesamten Publikationsaufkommen entsprechen diese Artikel? Diese Frage ist nicht ganz einfach zu beantworten. Laut der Datenbank Scimago Journal and Country Rank (die auf SCOPUS basiert; ich kenne die Datenbank aber nicht näher) sind mit deutscher Beteiligung in den Jahren 2017, 2016 und 2015 insgesamt 170114 + 174262 +171792 = 516168 Artikel in dort indizierten (und damit, so hofft man, ernstzunehmenden) Fachzeitschriften veröffentlicht worden. Umgerechnet auf den etwas kürzeren Zeitraum meiner Stichprobe wären das 495521 Artikel.
Meine Stichprobe entspricht 0.09 Prozent dieser Gesamtanzahl. Wenn NDR & Co. den Predatory-Publisher-Markt mit ihrer Recherche einigermaßen vollständig erfasst hätten, dann läge der tatsächliche Anteil solcher Artikel an der Gesamtzahl zehn Mal höher, nämlich bei rund 0.9 Prozent.
Bereits bei meiner Kennzahlberechnung hatte ich die OECD-Daten für die Anzahl der Forscher/innen in Deutschland benutzt. Für das Jahr 2015 (letzter abrufbarer Wert) waren das 586030. Die Autoren in meiner Stichprobe entsprechen 0.15 Prozent davon. Skalieren wir wieder von 17500 auf 175000 Artikeln hoch, lägen wir bei 1.5 Prozent – auf einen ganz ähnlichen Wert kommt auch das Science Media Center in seiner Fact Sheet zu Pseudo-Journalen.
Fazit der ersten Sichtung
Ein kurzes Fazit der ersten Sichtung: Ich komme auf eine höhere Anzahl beteiligter deutscher Wissenschaftler, allerdings durchaus auf die gleiche Größenordnung. Insgesamt handelt es sich sowohl nach Zahl der Beteiligten als auch nach Zahl der Artikel offenbar um ein Randphänomen im niedrigen einstelligen Prozentbereich. Das heißt nicht, dass man sich nicht damit beschäftigen sollte. Es heißt aber, dass man mit Verallgemeinerungen auf “die Wissenschaft” oder “den Wissenschaftsbetrieb” vorsichtig sein sollte. Meine Stichprobe ergibt keinen Hinweis darauf, dass Deutschland in punkto Predatory-Journal-Artikel besonders heraustechen oder gar eine Schlüsselrolle spielen würde, wie zum Teil in der Berichterstattung behauptet wurde.
Für alles weitere muss ich die betreffenden 443 Artikel per Hand näher anschauen – die bequeme Massenauswertung per Skript stößt da an ihre Grenzen. Darum wird es dann im zweiten Teil dieses Blogbeitrags gehen.
Alle meine Blogbeiträge zum Thema:
- Abzock-Zeitschriften: Wie groß ist das Problem? (“Vorstudie”)
- Teil 1: Methoden, Ländervergleich, Gesamtzahl
- Teil 2: Die Vielveröffentlicher
- Teil 3: Die Institutionen
- Teil 4: Themengebiete, Erstautoren
- Teil 5: Fazit
Bei mir ist der Bericht über die Nutzung von Abzock-Journalen gleichzeitig mit der Nachricht, dass sich deutsche und schwedische Bibliotheks-Bünde gegen die Abzocke der “seriösen” Firma Elsevier wehren, angekommen. Und gleich tauchte der Gedanke auf, ob da nicht eine Ablenk-PR Kampagne erfolgreich war.
Prima Beitrag, und Danke für den Aufwand!
Ein weiterer Datenpunkt (aus meinem Gebiet, Planetary Science): Auch hier spielen Veröffentlichungen in den gewissen Journalen nur eine sehr, sehr untergeordnete Rolle.
Hier ist wohl der Grund, dass das Gebiet eher klein und daher übersichtlich ist, so dass sich die Publikationstätigkeit (gerade je nach Unterdisziplin) nur auf eine Handvoll Journals beschränkt. Und da ist man schnell nicht nur als Autor, sondern auch als Gutachter involviert. Die Kollegen haben daher eine gute Idee, wo der Begutachtungsprozess ‘was taugt’ – Papers in einem der Predatory Journals würden da schnell auffallen und wären der Reputation der Involvierten eher abträglich.
@Andreas Morlok: Danke für die positive Rückmeldung! Ich würde denken, dass es in weiten Teilen der Wissenschaft ähnlich läuft wie du es beschreibst. Für die, die in der Forschung Karriere machen wollen, dürften predatory journals aus genau dem Grund unattraktiv sein. Ich bin noch bei der systematischen Auswertung, aber es deutet sich an, dass ein großer Anteil der Veröffentlichungen aus Bereichen stammt, wo es den Autoren gerade nicht um wissenschaftliche Karriere geht. Dazu zählen z.B. auch medizinische Doktorarbeiten, von denen mir schon eine Reihe bei SCIRP untergekommen sind; für diese Autoren ist das dann ja meist die letzte eigene Forschung.
Hallo Markus,
Danke für diesen wunderbar recherchierten Artikel!
Ich habe aber eine Anmerkung: es ist immer von “Wissenschaftlern” die Rede, die in diesen Journalen publizieren und daraus wird abgeleitet, dass das Wissenschaftssytem ein intrinsisches Problem hätte. Wie sicher ist es nun aber, dass die Autoren der Studien tatsächlich Wissenschaftler sind? In diesen predatory journals, kann ja, wenn ich das richtig verstanden habe, jeder publizieren, ohne jegliche Qualitätskontrolle. Also auch Scharlatane die niemals ein Studium absolviert haben und auch nie an einer Uni gearbeitet haben. Ebenso unsicher sind die Echtheit der Namen und Affiliations der angeblichen Autoren. Im Rahmen der Recherche durch das internationale Journalistennetzwerk haben ja zum Beispiel österreichische Journalisten zu Testzwecken unter einem polnischen Namen und mit der Affiliation der Uni Krakau publiziert. Jetzt wäre interessant, wie viele Artikel die unter deutscher Fahne publiziert wurden, wirklich aus Deutschland stammen?
@Elisabeth: Danke für das positive Feedback. Beim nächsten Teil (Stichprobe der “Vielveröffentlicher”) deutet sich an, dass tatsächlich auch da die “Randgruppen” überproportional vertreten sind, die eigentlich nicht repräsentativ für das Wissenschaftssystem sind: Emeriti und andere Ehemalige, Privatgelehrte, durchaus auch Klinik-Ärzte an normalen (nicht-Uni) Kliniken und niedergelassene Ärzte. Zumindest die Herkunftsangabe scheint aber in der Regel zu stimmen. Mehr dazu dann im dritten Teil, der allerdings noch Arbeit erfordert, wo ich mir die angegebenen Institutionen mal näher anschaue.
Besten Dank, sehr interessant. Anlass für die Recherche und Berichterstattung von NDR/WDR/SZ sowie der ARD waren gar nicht so sehr die absoluten Zahlen, die in der Tat im niedrigen Prozentbereich liegen. Anlass war vor allem der ziemlich deutliche Anstieg in den vergangenen Jahren: Waren es z.B. für OMICS 2010 und 2011 noch deutlich weniger als 100 Autoren pro Jahr, stieg das danach stark an und erreichte jährliche Zahlen zwischen 700 und 900 für die Jahre 2014 – 2017. Für andere Raubverleger wie WASET sieht die Tendenz ähnlich aus. Bis ca. 2013 dürfte die Gesamtzahl unter 1000 gelegen haben, erst jüngst ist bis sie auf über 5000 gestiegen.
Die Zahlen kamen übrigens auf recht einfache Weise zustande: Über eine Google-Site-Suche lässt sich auf den Webseiten der entsprechenden Verlage nach Autoren aus Germany (oder auch mit deutschen Email-Adressen) suchen. Bei verfeinerten Suchen wurde dann nach deutschen Städtenamen gefahndet.
Vielleicht noch ein interessanter Seitenaspekt: Aus folgendem Grund dürfte es eine Dunkelziffer geben: Man hat als Wissenschaftler durchaus die Möglichkeit, ein bei einem Predatory Publisher veröffentlichtes Paper zurückzuziehen – allerdings will der dafür Geld sehen, meist einige hundert $. Die Wissenschaftler, die sich darauf eingelassen haben, sind kaum noch zu finden, schließlich ist ihre Publikation aus dem Archiv der Scheinverlage verschwunden. Viele Grüße, FG
Danke für die Rückmeldung und die weiteren Angaben! Eine Frage wäre: ist der Anstieg auch direkt bei den deutschen Autoren zu finden, oder ist das eher ein Boom in China, Indien etc.?
Zweite Rückfrage: In welche Kategorien wurden die Google-Site-Suche-Ergebnisse denn dann noch sortiert? Da bekommt man ja sicherlich Doppeltreffer, und auch Treffer, die weder Artikel noch Konferenzbeitrag sind. Wurde das entsprechend alles noch einmal durchgegangen / nachsortiert?
Hallo Markus,
ich finde auch: Ein sehr informativer, durchdachter Artikel zu diesem Thema! Zwei Dinge kann ich evtl. noch zur Diskussion beitragen:
1.) Die Werbung solcher “predatory journals” hat zuletzt deutlich zugenommen und erscheint zumindest teilweise auch professioneller geworden zu sein, so dass man evtl. manchmal zweimal hinschauen und nicht nur auf den Journal-Webseiten, sondern zusätzlich auf einschlägigen Webseiten recherchieren muss (jedenfalls wenn man sicherzugehen will, dass man keinen Falschverdacht streut, wenn man in der eigenen commmunity vor solchen Journals warnen will).
2.) Evtl. könnte in der Diskussion noch (stärker) darauf eingegangen werden, was tieferliegende Ursachen dafür sind, dass manche Autoren nicht so genau hinschauen, wo sie etwas veröffentlichen. So veränderten sich im Zusammenhang mit der veränderten Governance der Wissenschaft in der letzten Dekade stärker auch die Rahmenbedingungen der Forschung. Hierzu zitiert beispielsweise der Wissenschaftsrat (2015, S. 10) die DFG-Denkschrift (2013): „Dabei wird der Wandel des Wissenschaftssystems hin zu ´großbetrieblicher´ Wissensproduktion und die damit einhergehende Produktivitäts- und Quantitätsideologie in der wettbewerblichen Wissenschaft als wichtiger Einflussfaktor für die Motivation gesehen, durch regelwidriges Verhalten zum Erfolg zu kommen.“ Dies gilt m.E. auch für wissenschaftliches Fehlverhalten generell (ausführlicher dazu siehe https://scilogs.spektrum.de/wissenschaftssystem/fehlverhaltendrittmittel/).
Beste Grüße
René
Die von mir genannten Zahlen und der Anstieg beziehen sich auf Autoren deutscher Einrichtungen. Weltweit liegen die Zahlen bei ca. 400.000 Namen.
Die genaue Sortierung kenne ich nicht, aber die Ergebnislisten enthielten – soweit ich das beurteilen kann – keinerlei Doppelungen.
@Frank Grotelüschen: OK, danke für die weiteren Informationen! Was ich nach wie vor nicht nachvollziehen kann ist die “Schlüsselposition”, die das SZ-Magazin Deutschland in der Sache zuschreibt. Da scheinen andere Länder, siehe meine Auswertung oben, viel tiefer drin zu stecken.
Auf dieser Webseite gibt es noch weitere Details, wie die Daten erhoben wurden:
https://www.ndr.de/nachrichten/FakeScience-Fragen-und-Antworten,fakescience198.html
Und das mit der “Schlüsselposition” ist vorsichtig formuliert eine Auslegung mancher Kollegen. Für meinen Teil kann ich das auch nicht aus den Daten herauslesen…
@Frank Grotelüschen: Danke für den Link, da stehen in der Tat interessante nähere Details drin. “Schlüsselposition” können wir dann wohl vergessen; meine Daten sprechen wie gesagt auch dagegen.
Ich denke, das Ergebnis der Recherche von SZ/ARD/internationale Verlage lässt sich auf einer qualitativen und einer quantitativen Ebene diskutieren.
Mich interessiert die qualitative Seite.
Wenn ich das Statement der Leibniz-Uni Hannover lese zur Nutzung von Raubverlagen im PZH der Uni, dann kann ich nicht erkennen, dass den Forschern Verantwortung zugewiesen wird für die Wahl ihrer Zeitschriften. Ebensowenig nennt das Statement eine Verantwortung der Unileitung. Konsequenzen werden auch nicht angekündigt. Das Rechercheergebnis wird kleingeredet und sogar darauf hingewiesen, dass nicht alle in Raubverlagen erschienenen Artikel falsch sein müssen.
Ja mei, so wird der Graben zwischen Innenansicht und Außernansicht der Wissenschaft nicht kleiner.
Ich fand ein blog gut, das eine einfache google Suche nach Raubverlagen ermöglicht.
“uni * de” filetype:pdf site:omicsonline.org OR site:sciencedomain.org OR site:omicsgrouponline.org OR site:waset.us OR site:waset.org OR site:waet.org OR site:imed.pub OR site:thescipub.com OR site:iosrjournals.org OR site:conferenceseries.com OR site:journalrepository.org
“uni * de” filetype:pdf site:omicsonline.org OR site:sciencedomain.org OR site:omicsgrouponline.org OR site:waset.us OR site:waset.org OR site:waet.org OR site:imed.pub OR site:thescipub.com OR site:iosrjournals.org OR site:conferenceseries.com OR site:journalrepository.org
@Laubeiter: Dass nicht alle in Raubverlagen erschienenen Artikel falsch oder schlecht sein müssen, ist ja leider in der ursprünglichen Berichterstattung in den Hintergrund gerückt; insofern finde ich richtig, darauf hinzuweisen (und habe das hier ja auch selbst getan).
Wichtige Konsequenzen wären aus meiner Sicht, dass man die Wissenschaftler selbst auf das Problem hinweist – sowohl als potenzielle Autoren als auch potenzielle Gutachter z.B. von Publikationslisten bei Bewerbungen.
Qualitative Analysen sind natürlich sehr viel schwieriger als quantitative; die Google-Suchschemata sind jedenfalls gut (so haben das ja NDR et al. auch gemacht), und da sollte dann jeder Wissenschaftler einfach mal selbst sehen, was da so aus dem eigenen Fachgebiet herauskommt.