

Research Data Management

Im Zeitalter von Big Data ist das Problem immer mehr, die Verwaltung der großen Datenmengen. Satellitenteleskope messen auf allen Wellenlängen im All, Bibliotheken digitalisieren die riesigen Mengen von Literatur aus allen Zeitschichten und die Archäologie bringt immer neue Objekte dazu. Das Problem, das man vor ~3500 Jahren durch die Erfindung von Bibliotheken löste, deren Anspruch das Wissen der Welt zu sammeln in der historischen Bibliothek von Alexandria kulminierte, wird heutzutage auf ein ganz neues Level gehoben.
- Wir schreiben nicht mehr nur Bücher/ Fachartikel, sondern wir publizieren auch die Daten dazu (noch vor ~100 Jahren blieben diese in den handschriftlichen Laborbüchern unpubliziert und bestenfalls von Wissenschaftshistorikern angeschaut), auf dass alle, die wollen, die Forschungsergebnisse/ -thesen überprüfen können.
- Während man für Text-Bild-Gemische eben Bücher und Fachartikel hat, für Fachartikel vor ca. 200 Jahren sammelnde Fachzeitschriften erfand (um den akademischen Austausch nicht auf bilateralen Briefwechsel zu beschränken), Jahrgänge von Zeitschriften zu buchartigen Gebinden zusammenfasst und all diese gebundenen Schriften in Bibliotheken sammelt, gab es für die Datengrundlagen lange keinen einheitlichen Sammelort.
- Die Informatik erfand im 20. Jahrhundert Datenbanken, also Netzwerke von Tabellen, deren Verknüpfung das Durchsuchen erleichert und Hypertext, mit dem man Text sehr leicht auf andere Texte verknüpfen kann.
- Doch mit dem Wachsen der Vielfalt von Datenformaten, ist auch das Verknüpfen und Verschränken von Daten in verschiedenen Datenbanken als neues Problem definiert.
- Die Informatik erfand das Semantic Web, Wissensgraphen und Ontologien, um Netzwerke von Wissen und Netzwerke von Netzwerken mathematisch zu beschreiben. Die Abfragesprachen für all diese Datenlagerungsstrukturen (wie SQL, SPARQL u.a.) gehören heute zum akademischen Handwerkszeug wie der Bleistift. … und Nationale ForschungsDatenInfrastrukturen (NFDI) schießen wie Pilze aus dem Boden, denn man braucht sie für alle Fächer.
Interdisziplinärer Forschung wie der Astronomie (die ja schon seit 2.5 Jahrtausenden Natur- und Geisteswissenschaften verbindet) eröffnet dies ungeahnte Möglichkeiten. Was hätte wohl ein Universalgelehrter wie Aristoteles, Eratosthenes, oder Ptolemaios noch alles gefunden, wenn er schon die heutigen Möglichkeiten gehabt hätte?
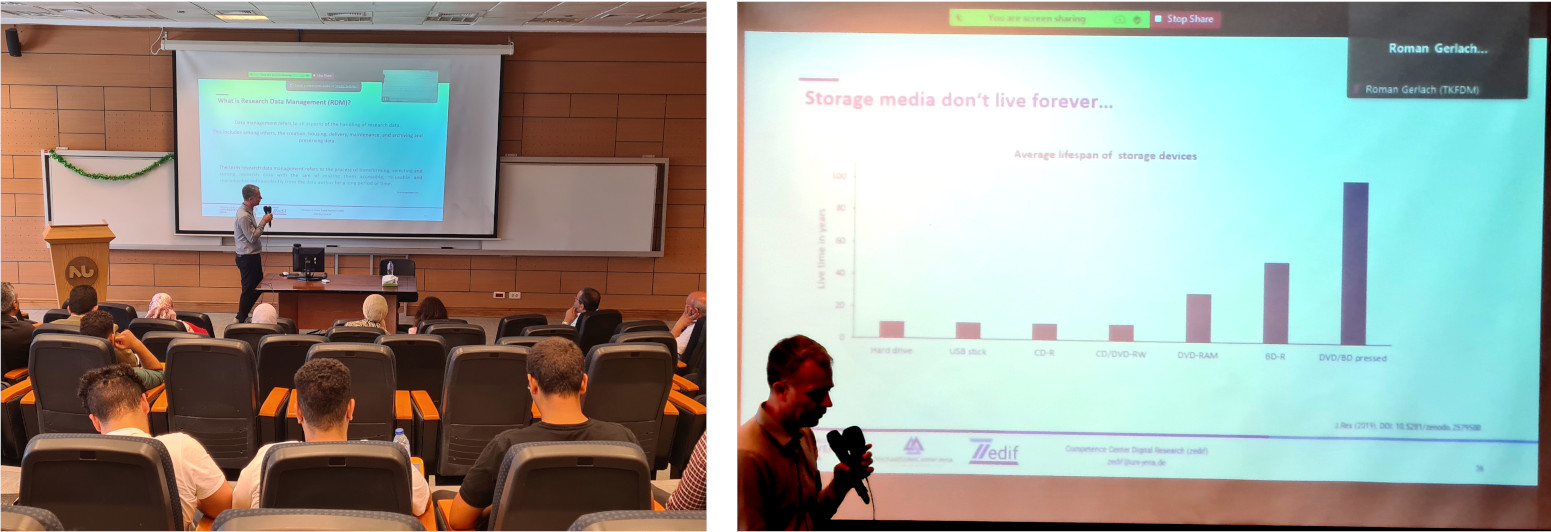
Weniger philosophisch-kontemplativ, sondern direkt in die Probleme der Gegenwart thematisierend war unser deutsch-ägyptischer Datenmanagement-Workshop in Madinat as-Sadis min Uktubar, der “Stadt des 6. Oktober”, nahe Kairo. Zwei Tage lang wurden Vorlesungen gehalten zu den Themen von Datenspeicherung, Datenmanagement, Datenmanagement-Planung und vielem mehr. Das ist natürlich keine Entwicklungshilfe: An ägyptischen Universitäten gibt es bereits Konzepte dafür, in Deutschland gibt es landesweite Richtlinien und die EU hat wiederum eigene Richtlinien. Bei DAAD-Projekten geht es Austausch zwischen Akademikern. Die Aufgabe war also, zusammenzutragen, was es an einzelnen Datenmanagement-Konzepten, -Anforderungen etc. gibt und wie man damit umgeht. Ein Datenmanagement-Berater, Roman Gerlach, der Friedrich-Schiller-Universität Jena stand hier Rede und Antwort für allgemeine Fragen, obwohl das gemeinsame deutsch-ägyptische Forschungsprojekt eigentlich auf eine sehr konkrete Anwendung (Bio- und Geo-Daten) gemünzt war.
Die hierbei strukturierten naturwissenschaftlichen Daten sind allerdings derart wichtig für zahlreiche Forschungsfragen, dass man sie auch fachfremd erreichen können sollte. Sie sollten also idealerweise auch ohne fachlichen Hintergrund lesbar sein, so dass sich die naturwissenschaftliche Forschung (in allen MINT Fächern) hierüber verstärkt Gedanken macht. In den Geschichtswissenschaften übrigens auch, denn nirgends ist der natürliche Datenverlust durch den Zahn der Zeit so offensichtlich wie hier. Umso großartiger, an einem so historischen Ort (Ägypten) über Datenmanagement zu reden!


Diese Universitäten in Ägypten sind super modern ausgestattet: der Testpatient, den wir hier bestaunen, ist ein sprechender Kunststoff-Roboter, der so tut als würde er atmen und krank sein. Hieran können Studierende üben, bevor sie auf echte Menschen als Patienten losgelassen werden.
Am Nationalen Forschungsinstitut für Geowissenschaften und Astronomie (in Helwan bei Kairo) fiel unser Besuch mit einer kleinen (eintägigen) Tagung zum Thema “Klima ist zwischen Erde und Himmel” zusammen, so dass ich dort einen Vortrag zum Thema Citizen Science-Sternbeobachtungen in Abhängigkeit von Wetter, Licht- und Luftverschmutzung halten durfte. Das ist jetzt erstmal nicht direkt Forschungsdaten-Management, sondern Forschungsdaten-Genese, aber die so generierten Daten wollen ja irgendwann ausgewertet werden, so dass man sich auch über die Lagerung Gedanken machen muss.

Auch diese kleine Konferenz durfte ich als ausländische Gästin miteröffnen: Es war mir eine Ehre.
Danke, Thank you and شكرا an Dr. Alsayed Algergawy und Prof Dr. Passent ElKafrawy für die Organisation dieses großartigen Austauschprogramms!
Datentresoren, die Katastrophen überstehen
Vielleicht braucht ja die Welt für wissenschaftliche Daten etwas Analoges zum Svalbard Global Seed Vault, dem weltweiten Saatgut-Tresor. Die Fragen wären nur noch wo man den weltweiten Wissenschaftsdaten-Tresor einrichten soll, in welcher Form man die Daten speichern soll und wie man auf die Daten zugreift.
Um alle Daten aus wissenschaftlichen Studien Jahrhunderte, ja Jahrtausende überstehen zu lassen, also Zeiträume in denen Katastrophen auch ganze Länder zerstören können, sollte man vielleicht mehr als einen Speicherort in Betracht ziehen und die Daten in identischer Form an mehreren Orten gleichzeitig speichern. Um die Sicherheit der Daten gegenüber Schreibzugriffen zu gewährleisten, sollten Daten immer nur hinzugefügt, nicht aber gelöscht werden können. Ferner sollten die Daten ohne Stromversorgung ihre Integrität über Jahrtausende bewahren. Da käme etwa die Speicherung in Form von DNA oder in Form von Eingravierungen in Siliziumkarbid in Frage, denn beide können viele Jahrhunderte überstehen und bei beiden lassen sich sehr hohe Datendichten erreichen, bei Siliziumkarbid beispielsweise mehr als ein Terabit pro Square Inch, wie man dem Artikel Nanoscale Optical Patterning of Amorphous Silicon Carbide for High-Density Data Archiving entnehmen kann.
Ganz genau, der Erfindung der Sprache folgte die der Schrift, die des dann Buches und der Bibliothek :
Diese Bibliothek ging dann hopp :
-> https://en.wikipedia.org/wiki/Library_of_Alexandria
—
Räumlichkeiten der Schrift, die Schrift ist bekanntlich der dritte Zivilisationssprung , zuvor gab es die Erfindung [1] der Sprache und die der Schrift, sind sozusagen entzündlich, wenn andere, politische Gegner auch, so wollen.
Heutzutage gibt es zum Glück passende Digitalisierungen und passende Vorratsdatenhaltung, lokal und oft verknüpft, die resielienter ist.
Mit freundlichen Grüßen
Dr. Webbaer
[1]
Es geht so : Erfindung der Sprache, Erfindung der Schrift, gerne auch der Lautschrift (die ist flexibler), des Buches, die des Buchdrucks, die des Webs, die
u.a. die globale Datenhaltung und somit auch Bücher meint.
Ei sog. semantisches Web wirbt in seiner Entwicklung angestrebt, wird abär, diesseitiger Einschätzung, leider nicht möglich sein.
PS:
Antizivilisatorische Bewegung gibt es, sie wird alsbald auch europäisch breit aufscheinen.
Among other things, global data management and thus also books.
A so-called semantic web is aimed at in its development, but unfortunately it will not be possible, according to our assessment.