

G like gravitational lenses or finding a needle in a haystack

“If we’re lucky, we might find one or two gravitational lenses in our current data set.” Says astrophysicist Erica Hopkins about her latest research project. She sits in her office under the roof of an old villa on the HITS campus, outside it’s raining cats and dogs. But neither the weather nor the almost impossible task seem to discourage the young American. She is currently working in the “Astroinformatics” (AIN) group at HITS, that deals with large amounts of astronomical data on the daily basis. After her bachelor in the United States and an exchange year in Edinburgh (Scotland), Hopkins decided to stay in Europe and accepted the invitation by Kai Polsterer to join his newly established AIN group in Heidelberg (Germany). It was not only the location that made her join the team: “Our group is very interdisciplinary. We are combining classical astrophysics with the advantages of computer science.” That this is more than necessary is shown by the increasing amount of data in astronomy that is collected every day. In order to use it for their research, some astronomers must first find the objects they are interested in – such as gravitational lenses.
But how do researchers such as Hopkins that are now active in the new science field of astroinformatics (a combination of astronomy and informatics) actually do that? Hopkins found her love for astrophysics at the age of 11 when reading a science magazine with an article about “how galaxies collide” on the cover. Now she finds herself not peeking through the ocular of a telescope, but in front of a computer with not even pictures, but plenty of data and code running over various screens.
Get a grid!
In her recently finished master thesis, Hopkins gave a good example on how to use computer science to manage huge amounts of data. For this project, she classified the morphology of around one million so-called radio galaxies with the help of the computer. Radio galaxies are a very common kind of galaxy, which emit strongly in radio wavelengths due to the activity of the super massive black hole in their center. There are quite a lot of those objects in the universe, however, they are randomly orientated in three-dimensional spaces, but the telescope only captures a two-dimensional view. Thus, their seemingly random orientations on the sky and their potentially complex morphologies make classification hard. Hopkins wanted to find a way to sort them to find the really interesting stuff in the data set. The radio data Hopkins analyzed is from the “Faint Images of the Radio Sky at Twenty-Centimeters” (FIRST) survey which was carried out by the “Very Large Array” (VLA) in New Mexico (USA). Before Hopkins put the computers to aid, around 100.000 volunteers were sorting the objects by hand in a crowd sourcing project called “Radio GalaxyZoo”. For this, the volunteers spent over four years looking at pictures of radio galaxies to manually classify them. With the help of the computer the whole process took only a few months. But how could this be achieved?
Hopkins used a method called self-organizing maps (SOM) which was invented by the Finnish scientist Teuvo Kohonen in the late 1990s. “It’s technically some kind of neural network, but I find it easier to not think of it in that sense because it tends make it more confusing”. Instead of a neural network, one can simply imagine a dimensionality reduction method where a highly complex image is reduced to a coordinate on a 2D grid. Each pixel in the picture essentially represents one dimension of data. The computer then determines which images have similar shapes, after accounting for rotation, and clusters similar shapes together.
The final grid, generated by the computer, represents all the general structures that can be seen in the data. However, Hopkins didn’t sort the radio galaxies for the sole purpose of sorting astronomical objects, but to see which radio sources are part of the same galaxy and to find objects that are described by astronomers as “outliers”, structures that do not match with anything in the grid. “The computer helped us to sort the objects that are easily sortable. Instead of going through the entire data set by hand, the astronomers can now focus on pre-selected objects such as outliers.” says Hopkins. In this case, this meant that instead of looking at one million images of radio galaxies, the data set was reduced to approximately 2% of the original data set, or a little more than 20,000 objects – including some new discoveries. “In the end, I helped a collaborator find 17 giant radio galaxies, of which 16 were previously unknown, using the SOM method on a similar data set.” So far, it’s unknown how the galaxies grew so large, but to solve this mystery will be the task for other astronomers that can now use Hopkins’ results for their own research.
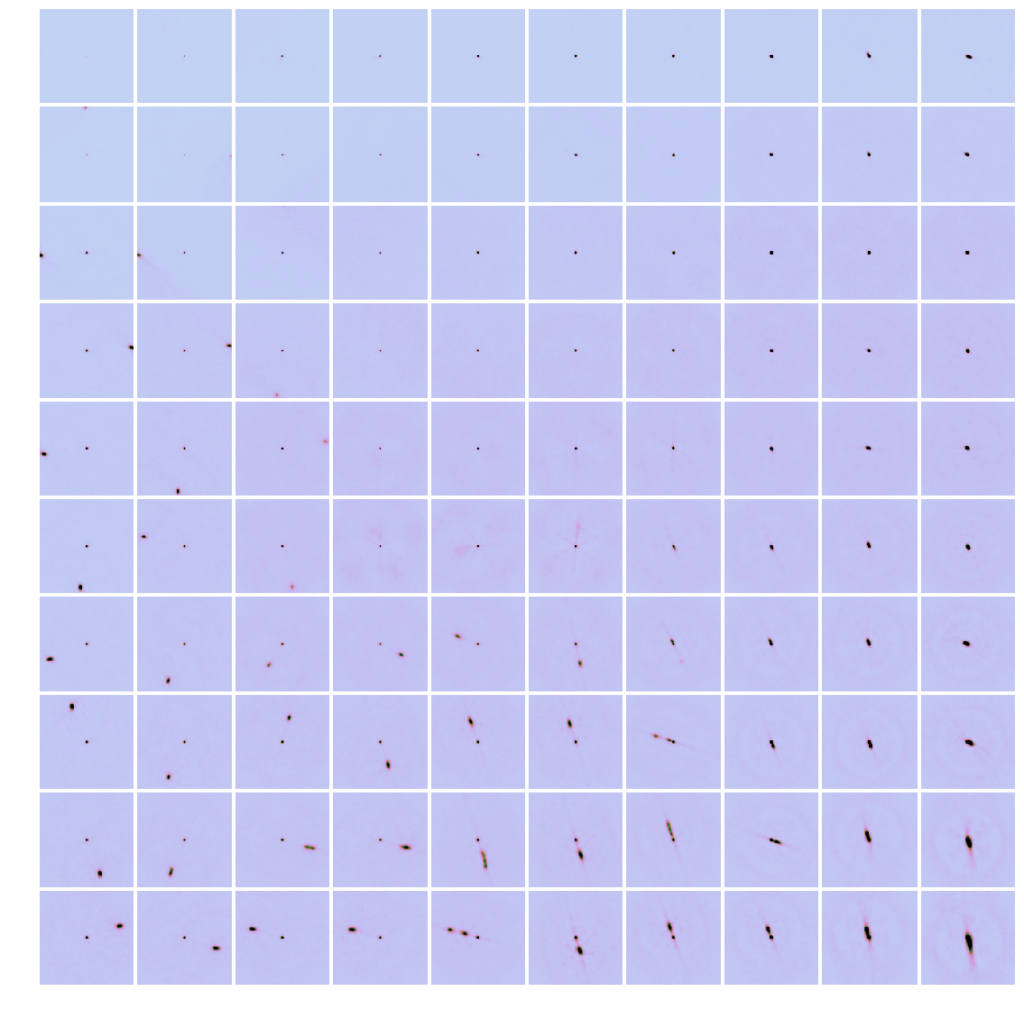
The data she used in this project was collected in the 1990s, which represents only a fraction of the astronomical data available today. So how does using “old” data help on a grand scale? “We basically trained our algorithm with it, since it’s a rather small and simple data set. In the future, we can use the same method for whichever new and complex data sets are collected by the telescopes.” says Hopkins.
The needle and the haystack
But unfortunately, not everything is as “easy” as sorting radio galaxies, where the objects and their location are known. For her PhD thesis, Hopkins decided to take her computer science ambitions a step farther and is now focusing on finding gravitational lenses. Lensing is one of the most intriguing and striking proofs of general relativity and a powerful tool to determine the distribution of mass and the effects of gravity in the universe. It is given when two massive objects, like galaxies, are aligned along our line of view. The galaxy in front would, in principle, obscure the one in back, but due to the distortion in the space-time structure caused by its huge mass, it acts as a lens. Therefore, the light coming from the galaxy on the back is deflected along its path and can reach us, creating multiple distorted images around the lens or, in the ideal case, a whole ring (the so-called Einstein ring).
“If we could find more of those lenses, we could learn a lot about how gravity works.” Hopkins explains when asked about her motivation for this project. In order to find those rare objects, colleagues from the “Strasbourg astronomical Data Center” (CDS) in France provided Hopkins with the optical data of the Pan STARRS (“Panoramic Survey Telescope And Rapid Response System”), which has collected over two billion objects so far. Hopkins’ colleagues gave her a pre-selection of the data set with possible locations. However, even this data set still contains around six million objects – of which one or two are potential gravitational lenses. This task, which is very much a search for a needle in a haystack, can only be achieved with the help of computer science.
Until today, there are less than 500 known gravitational lenses, which were in fact found by accident. “It’s been only around fifteen years, that we finally have the methods to deal with the large amount of data, so that there was not always a way to actually search for them.” Hopkins’ new project is going to change that. In order to find new gravitational lenses, she uses the work previously conducted by humans. In another crowd sourcing task, volunteers annotated the few known gravitational lenses and rated the lenses on how easily they were recognizable. Hopkins now uses those annotations to label the lenses for the neural network. According to Hopkins this approach seems to be the best solution since not all available images contain a noticeable lens because the lens was found at different wavelengths, such as radio. “Some pictures are just noise and there is no point in having the computer figure out whether this is an actual lens or just a blur”. She further describes this method as a help for the computer to help focus on the important details in an image rather than trying to make sense of something that can’t even be described by humans. The data is then fed to the neural network. “We basically tell the system ‘we are not trying to find every gravitational lens, we just want to find some more’ and even if they might be simple ones that are easy to find, we are happy with it.”

The model Hopkins is using for her new research project was originally created by Fabian Gieseke from the University of Münster (Germany), which she then modified for her needs. It is based on a so-called convolutional neural network (CNN), which is mostly used to analyze images. The CNN can roughly be described as a model that automatically extracts important features from one data set in order to give out results (in this case objects) the scientists were searching for. It’s a so-called supervised system, which means that the scientists trained it beforehand with known data and known output to make sure everything in the network adds up.
Hopkins already ran the 6 million pre-selected pictures through her neural network and scanned them for new optical lenses. So did she find them? The answer is a simple “maybe”. “The current results show potential candidates, but also some clear non-lenses the network wasn’t exposed to previously”, says Hopkins, “Therefore, the next step will be to further train the network to improve the output.”
The essence of astroinformatics
As fascinating as the previously described research might be, one might be wondering how reliable are the research results? “We have a saying in data science which goes ‘garbage in, garbage out’. You need to be sure that the data you are using is trustworthy and you also need to be capable of understanding what happens with it in the process to be able to judge if the results add up. A lot of mistakes made in this field are due to scientists not understanding the machine learning aspects so that they are easily misapplied.” Which also answers the valid question if humans might become useless in the future if the computer can do their work for them. “Not at all!”, laughs Hopkins, “The computer can help humans with time consuming tasks. Instead of wasting their time to search for things manually, scientists can now focus on the important parts which require a more complex way of thinking. Also, data annotation which is conducted by humans will still be a part of machine learning in the future to ensure the computer is focusing on what we’re most interested in.” Further, the scientists have to not only decide which data they are searching for, but also which method to apply. As the previously described research shows, there is not one solution to all problems, but the researchers must use different techniques from different fields and modify it for their needs in order to make it work. Something a computer cannot do on its own.
Erica Hopkins work gives a glimpse at the challenges that are already a big part of the work of astronomers and data scientists alike. However, the performance of telescopes is still improving. It is expected that we will be able to collect over 70 million new radio objects with the help of the “Square Kilometre Array” (SKA) telescope. Even if scientists just focus on a small amount of it, this still leaves several million objects that need to be analyzed afterwards. According to Hopkins, one of the biggest issues astronomy has nowadays is that we are having all that huge amount of data, but having all this data doesn’t mean anything if we don’t have the techniques to actually find what’s useful. “The question we will need to ask ourselves is ‘how will we be able to sort that in order to find what we want?’” Hopkins sums up.
Creating meaning: Identifying and locating creatures in the wild
Past and future events and constellations hide in today’s star catalogs. Things like:
– Strong and weak gravitational lenses
– Current and future microlensing constellations (yes: Gaias data contain information about future microlensing events)
– Black holes which are really black and only show up by their influence on the motion of nearby stars
– Stars which do not fit entirely in an existing category
These are only the first entries in a catalogue of nearly unlimited size.
Yes: Erica Hopkins can easily spend her hole career on finding interesting creatures in the already existing and rapidly growing data zoo.
And perhaps the strategies to find interesting stellar constellations can even be applied to particles in the data stream of particle accelerators like the large hadron collider. Or to the pictures showing people on the streets anywhere in the world.
Who knows? (perhaps future data scientists will know)
The Sun as Gravitational Lens
And yes, in a day in the future an astronomer and data scientist will enumerate and rank all earth-like exoplanets in the milky way and for the most promising exoplanet a space telescope will be placed at a distance of 550 astronomical units away from the Sun using the sun as gravitational lens.
In this way the sun gave birth to Life on earth and gives insight into Life on other planets!
This is a possible scenario from a theoretical point of view and it is based on what is usually referred to as microlensing. However, there are a variety of physical and technological challenges which make such a method for direct imaging of exoplanets extremely difficult. Let’s see what the future brings.