

How an algorithm became superhuman at Go — but not StarCraft — and then moved on to modeling proteins
BLOG: Heidelberg Laureate Forum

In a talk at the #vHLF20, DeepMind’s David Silver (recipient of the 2019 ACM Prize in Computing) showcased how AIs have become so powerful at playing games — and how this could be used to solve real-life problems.
A complex system based on a simple assumption
Cracking Go was a gigantic task which many AI researchers see as an inflexion point in the field. In essence, it’s a simple game: you place black and white pieces (called stones) on a board and attempt to surround your opponent. Winning at Go, however, is anything but easy — the number of legal board positions has been calculated to be approximately 2 × 10170; for comparison, the number of atoms in the universe is estimated to be 1080.
Because of this complexity, many people thought that algorithms are incapable of defeating humans at the game of Go. Turns out, those people were wrong.
Spearheaded by Silver, the neural network AlphaGo easily defeated world champion Lee Sedol (4-1) in 2016, stunning the entire world. But that was just the beginning. The subsequent AlphaZero defeated AlphaGo 100 to 0 after only 8 hours of training. To make matters even more impressive, AlphaZero was only being fed the rules of the game, with no additional knowledge and no human babysitting.
“The agent is born into the game,” says Silver. “It just knows the rules.”
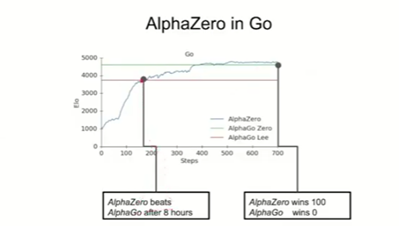
Hearing Silver casually explain the process, you could be tricked into thinking it’s a trivial achievement, yet this is anything but trivial — it’s achieving what was once thought impossible in only 8 hours. All this, explains Silver, is based on a simple concept: reward.
All that AlphaZero knows is that it gets a reward if it defeats its opponent. It has no understanding of context, no general overview, just an innate ‘desire’ to maximize its reward by winning. Perhaps, notes Silver, this is sufficient to produce true intelligence.
From start to Starcraft
There’s a reason why DeepMind and other AI projects focus on games. First of all, they have a tangible objective, and they’re popular. Aside from real-life board games like Go, chess, or Shogi, DeepMind also worked on 57 popular Atari games. In all of them, the AI achieved superhuman performance, in some cases developing strategies that the designers themselves weren’t aware.

But one game proved particularly challenging: Starcraft.
Starcraft is a real-time strategy game where the player chooses one of three playable races, builds a base, soldiers, and attempts to eliminate its opponent.
“Starcraft is widely considered the peak of human ability when it comes to computer games, requires the greatest human skill among all of the different games. It’s also canonical, it’s played by millions, 20 years of active human play, very complex,” explains Silver.
But unlike Go or chess, Starcraft is a game of incomplete information: you only see the part of the map that you’ve explored, and you don’t really know what your opponent is up to. AlphaStar — the Starcraft version of the ‘Alpha’ AIs — achieved remarkable prowess at the game but was unable to equal the performance of the very best players (so if you’re looking for human superiority, there’s still a sliver of it in Starcraft).
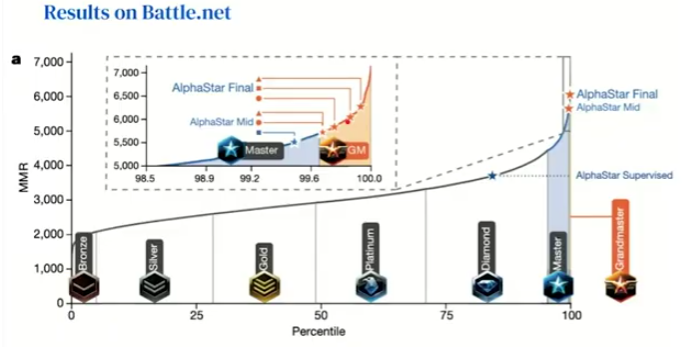
But as impressive as this performance may be, there’s still something that bothered Silver: the AI knew the rules. Go and chess have simple rules. Starcraft is a bit more complex, but it too has well-defined boundaries. The real world is nothing like that: it is chaotic and unpredictable, and if we want true, adaptable intelligence, we need to let go of the rules.
So they did. This is where things start to get really interesting.
From games to real-life problems
“We achieved reward maximization,” says Silver, “but we have had to start with a significant piece of knowledge: the rules themselves. In many real-world problems, we don’t know how the ‘world’ works, it’s a messy place and there aren’t any rules. So we developed a new variant called MuZero, which learns by playing and learning the environment. In brief, the model learns in such a way that’s actually focusing only on what is helpful to maximize reward.”
MuZero attempts to master games without even knowing the rules, and it does so with remarkable ability. It was trained via self-play and play against the ‘Alpha’ generation and achieved comparable performance.
This is particularly encouraging because it suggests that the approach can be used to generate model-based behavior in virtually any field. As remarkable as winning at Go is, the big prize here is solving real-world problems.
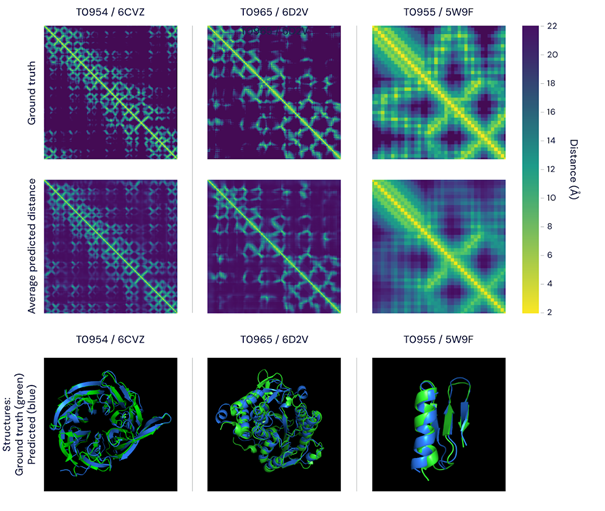
Already, DeepMind’s AI (the Alpha version, AlphaFold) is making valuable contributions in the field of protein folding. Proteins are large, complex molecules that direct nearly every function in our bodies. Their function depends on their unique 3D structure, and modeling protein folds is one of the most exciting fields of modern biomedical research; once a protein’s structure is understood, its function can also be assessed. Conversely, if you want to design specific proteins, they need to have a specific shape.
“The 3D models of proteins that AlphaFold generates are far more accurate than any that have come before—marking significant progress on one of the core challenges in biology,” a DeepMind press release notes. Another area where the approach is already becoming useful is predicting traffic.
We’re still far from achieving true artificial intelligence, but we’re already entering the stage where AI can leave the game room and start solving real-life problems. It’s an exciting time, and we’re only now getting glimpses of its potential.
The combination of Monte Carlo Tree Search and deep neural networks based on machine learning which is used in Alpha Zero has already 1) Applications in Chemistry and 2) Quantum Dynamics.
1) Retrosynthesis (Wikipedia: Retrosynthetic analysis is a technique for solving problems in the planning of organic syntheses. This is achieved by transforming a target molecule into simpler precursor structures regardless of any potential reactivity/interaction with reagents. Each precursor material is examined using the same method. This procedure is repeated until simple or commercially available structures are reached. )
is an application of a modified Alpha Zero. See: Chemical synthesis with artificial intelligence: Researchers develop new computer method
2) Quantum Dynamics problem of finding suitable initial values can be can be solved by Alpha Zero. See: Global optimization of quantum dynamics with AlphaZero deep exploration