

Die seltsamen Fehlleistungen neuronaler Netze
BLOG: Heidelberg Laureate Forum

Die Großtat, für die Adi Shamir berühmt wurde, ist schon eine ganze Weile her. Im Jahr 1977 erfand er, gerade mal 25 Jahre alt, gemeinsam mit Ron Rivest und Leonard Adleman das asymmetrische Kryptosystem, das nach den Anfangsbuchstaben seiner Erfinder RSA-Chiffre heißt und bis heute, wenn auch mit Modifikationen, beim Verschlüsseln von Nachrichten eine – jawohl – Schlüsselrolle spielt.
Aber Adi Shamir hat sich auf seinen frühen Meisterleistungen nicht ausgeruht. Auf dem diesjährigen Heidelberg Laureate Forum überrascht er sein Publikum mit Neuigkeiten aus einem Gebiet, das mit Kryptografie – bis auf die Zugehörigkeit zum großen Fach Informatik – nichts zu tun hat: neuronale Netze.

Das sind diese Schichten aus lauter einfachen Elementen, die Neuronen nachempfunden sind. Information fließt von den Neuronen einer Schicht zu denen der nächsthöheren Schicht, wird von diesen in relativ einfacher Weise verarbeitet und an die übernächste Schicht weitergereicht. Die Einzelheiten dieser Verarbeitung legt sich das Netz auf eine sehr spezielle Weise zu: durch Lernen an Beispielen. Neuronale Netze haben in den letzten Jahren sensationelle Erfolge erzielt, zum Beispiel den Weltmeister im Go-Spiel entthront. Sie stecken auch hinter den „large language models“ wie ChatGPT, die zumindest den Anschein eines Denk- oder gar Einfühlungsvermögens erwecken.
Angesichts dieser Erfolge ist es umso beunruhigender, dass neuronale Netze auf ihrem ursprünglichen Spielfeld, dem Erkennen von Bildern, unerklärliche Schwächen aufweisen. Ein Netz hat sehr viele Bilder von Katzen präsentiert bekommen und dabei gelernt, eine Katze zuverlässig von jedem anderen abgebildeten Gegenstand zu unterscheiden. Dann stört man ein Bild, das eindeutig eine Katze zeigt, mit einer minimalen Menge zufälliger Abweichungen, so klein, dass ein menschlicher Betrachter überhaupt keinen Unterschied sieht – und schon glaubt das Netz, das Bild zeige einen Weißstorch, eine Schüssel mit Guacamole oder was weiß ich.
Na ja – wenn ein solches neuronales Netz in einem autonomen Auto steckt und die Bilder seiner Kamera analysiert, legt man irgendwie schon Wert darauf, dass es nicht eine freie Strecke mit einer roten Ampel verwechselt oder umgekehrt. Entsprechend eifrig haben sich die Fachleute um eine Erklärung des Phänomens bemüht, bisher ohne nennenswerten Erfolg. An dieser Stelle bietet Adi Shamir gemeinsam mit Odelia Melamed und Oriel BenShmuel vom Weizmann Institute of Science in Rehovot (Israel) eine neue Idee an. Die entscheidenden Gedanken kommen dabei bemerkenswerterweise aus der Geometrie.
In ihrer Arbeit nehmen Shamir, Melamed und BenShmuel der Klarheit der Darstellung zuliebe einige heftige Vereinfachungen vor. So unterstellen sie, ihr neuronales Netz habe nur gelernt, zwischen zwei Sorten von Bildern zu unterscheiden: „Katze“ und „Pampe“ (im Original Guacamole). Und während echte neuronale Netze in ihrer untersten Schicht die Farbwerte der Pixel entgegennehmen, aus denen das Bild besteht, ist es in der Vereinfachung nur eine einzige reelle Zahl pro Pixel.
Ein ausgelerntes neuronales Netz tut dasselbe wie ein Computerprogramm, das zu einem x das f(x) berechnet: eine Funktion auswerten. Das x ist ein Bild und das f(x) eine reelle Zahl, die angibt, wie stark dieses Bild das Merkmal „Katze“ aufweist. Wie die Funktion f definiert ist und wie das Netz sie berechnet: Das wissen wir nicht so genau. Die Einzelheiten der Berechnung hat es ja nicht einprogrammiert bekommen, sondern gelernt: indem ein „Lehrer“ ihm viele Beispielbilder vorlegte und dazusagte, ob es sich um Katze oder Pampe handelt. Immerhin wissen wir, dass unsere Funktion bei jedem der gelernten Katzenbilder einen hohen positiven Wert annimmt und bei jedem Pampenbild einen sehr negativen.
In dem abstrakten Raum aller denkbaren Bilder – ja, jedes Bild ist genau ein Punkt in diesem Raum! – wandern wir jetzt in Gedanken von einem Punkt mit sehr positivem f-Wert (sprich Katzenbild) zu einem mit sehr negativem f-Wert (Pampenbild). Die Punkte unterwegs sind dann Bilder, die einen sehr allmählichen Übergang vom einen zum anderen Bild darstellen. Dann ist irgendwo auf dem Weg f(x) = 0. (Ja, f ist stetig, und es gilt der Zwischenwertsatz.) Das gilt für alle Wege von der einen zur anderen Bildersorte.
Wenn der Raum aller Bilder jetzt zweidimensional wäre, so dass wir ihn uns richtig leicht vorstellen könnten, dann gäbe es in diesem Raum Katzenbezirke und Pampenbezirke. Möglicherweise gibt es von jeder Sorte mehrere Bezirke, die nicht miteinander zusammenhängen. Auf jeden Fall sind die Bezirke säuberlich getrennt, und zwar durch eine Kurve: die Menge aller Punkte, auf denen f(x) = 0 ist.
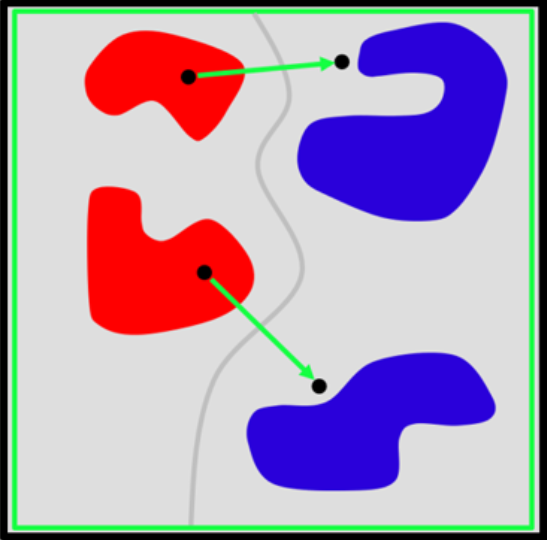
Leider hat der Raum aller Bilder nicht nur zwei Dimensionen, sondern so viele, wie ein Bild Pixel hat: Größenordnung eine Million. Die Funktion f gibt es immer noch, und deren Nullstellenmenge ebenfalls. In drei Dimensionen wäre es eine Fläche, und standardmäßig hat sie eine Dimension weniger als der Raum, in dem sie lebt. Die Fachleute sagen an dieser Stelle „Mannigfaltigkeit“ statt „Fläche“; denn zweidimensonal ist sie beim besten Willen nicht. Eine 999999-dimensionale Teilmenge eines millionendimensionalen Raums ist eine erhebliche Herausforderung für das Vorstellungsvermögen; aber man kann abstrakte Aussagen über sie machen.
Zum Beispiel kann die Trennfläche nicht beliebig verknittert sein. Denn sie ist das Ergebnis einer Berechnung durch – zugegeben: zahlreiche – Neuronen, die jedes für sich sehr einfach gebaut sind. Da können so exotische Dinge wie fraktale Verknitterungen gar nicht vorkommen. Und das oben genannte Verwechslungsproblem dürfte eigentlich auch nicht auftreten.
Unsere Funktion f ist stetig: erstens, weil die Neuronen konstruktionsbedingt nicht anders können, zweitens weil sich das beim Lernprozess ohnehin ergeben sollte. Das Netz soll ja ein Katzenbild mit geringen Abweichungen, also einen Punkt in unmittelbarer Nähe des Katzenbilds, noch als Katzenbild erkennen. Anders ausgedrückt: Die Funktion f soll von einem positiven Wert nicht plötzlich steil auf null und gar darunter abfallen. Genau das passiert aber.
Shamir und Kollegen bieten dafür folgende Erklärung an: Alle von einer Digitalkamera aufgenommenen und nicht raffiniert manipulierten Bilder sind in einem speziellen Sinne „ordentlich“. Sie enthalten eben nicht die zufälligen kleinen Abweichungen von der „richtigen“ Bildgestalt, die ein neuronales Netz so spektakulär in die Irre führen können. Insbesondere sind alle Bilder, Katze wie Pampe, an denen das Netz trainiert wird, ordentlich. In dem abstrakten Raum aller Bilder sind die ordentlichen eine sehr kleine und vor allem dünne Teilmenge. Je nachdem, wie man den Begriff „ordentlich“ definiert, was nicht einfach ist, liegt ihre Dimension um das Zehn- bis Hundertfache unter der des ganzen Raums.
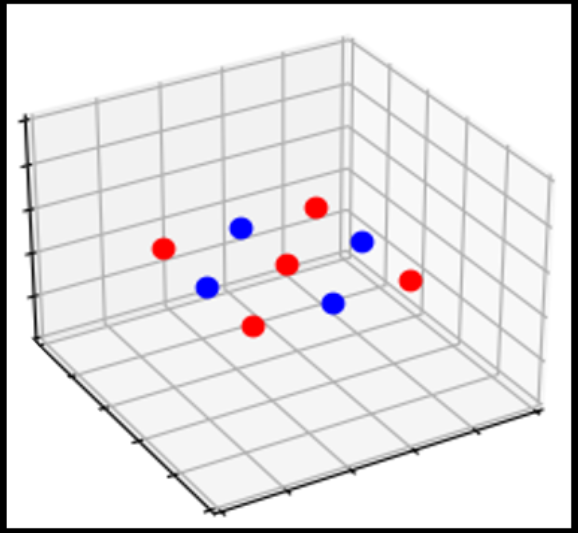
Wie dem auch sei: Im Verlauf des Lernprozesses merkt das Netz gewissermaßen sehr schnell, dass es überhaupt nur um ordentliche Bilder geht, und legt seine Trennfläche zwischen Katze und Pampe in einer ersten Phase so, dass sie im Wesentlichen der Teilmenge der ordentlichen Bilder folgt. Erst in der zweiten Phase kommt die Feinabstimmung: Wenn sich herausstellt, dass ein Katzenbild noch auf der falschen Seite der Trennfläche liegt, kommen die Zwerge mit kleinen Hämmerchen und schlagen eine Delle in die Trennfläche, bis die auf der richtigen Seite am Katzenbild vorbei verläuft. Dasselbe geschieht in umgekehrter Richtung, falls ein Pampenbild sich als fehlplatziert herausstellen sollte.
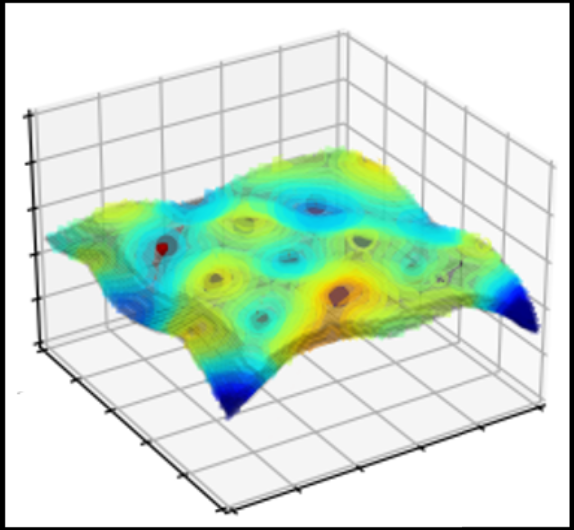
Was wollen uns die Autoren mit der seltsamen Metapher von den Zwergen und den Hämmerchen sagen? Mehrere Dinge. Erstens ist es eine gute Idee, sich die Trennfläche aus dünnem Blech vorzustellen. Klopft man es an einer Stelle zurecht, dann geht die unmittelbare Umgebung mit. Das ist eine andere Ausdrucksweise dafür, dass die Funktion f stetig und die Trennfläche nicht zu heftig gekrümmt sein sollte.
Zweitens: Wenn man auf das Blech klopft, beult es sich in einer Richtung aus, die senkrecht zur Ausbreitungsrichtung des Blechs ist. Jawohl, auch in hochdimensionalen Räumen kann man sinnvoll von rechten Winkeln reden. Allerdings gibt es hier sehr viele verschiedene Richtungen, die alle senkrecht auf dem Blech stehen. Da nun die Trennfläche im Wesentlichen der Menge der ordentlichen Bilder folgt, treibt jeder Hammerschlag sie von dieser Menge weg, in die wüsten Gefilde der unordentlichen Bilder. Einmal dort hingeraten, wird sie in der Tendenz dort bleiben. Denn da das Netz nie ein unordentliches Bild zu sehen bekommt, hat es auch keine Gelegenheit, die Position der Trennfläche im Reich des Unordentlichen zu korrigieren.
Drittens: Es sind sehr viele sehr kleine Hammerschläge. So ist das übliche Fehlerkorrekturverfahren („backpropagation“) gebaut. Das heißt, die Dellen im Blech sind ziemlich flach, gerade so tief, wie es sein muss, damit das Netz ein ordentliches Bild richtig erkennt. Das wiederum hat zur Folge, dass man von einem ordentlichen Bild nur ein kurzes Stück in die falsche Richtung wandern muss, um auf die Trennfläche zu treffen, und noch ein kleines Stück darüber hinaus, um auf die falsche Seite zu geraten.
So weit die stark vereinfacht dargestellte Idee. Wenn man die oben genannten Einschränkungen aufhebt – Farb- statt Schwarzweißwerte, mehr als zwei Klassen von Bildern –, wird die Sache unübersichtlicher, aber nicht prinzipiell schwieriger. Andere Einzelheiten, über die ich hinweggegangen bin, wollen ausgearbeitet werden, was die Autoren erhebliche Mühe gekostet hat.
Und nachdem das Problem erkannt ist, liegt eine Abhilfe nicht unmittelbar auf der Hand. Natürlich kann man eine große Menge unordentlicher Bilder erzeugen und dem Netz als Lernstoff vorlegen. Aber dabei steigt der Trainingsaufwand leicht auf das Tausendfache oder mehr, was die Sache unpraktikabel macht. Für eine wirksame Abhilfe braucht es wohl noch neue Ideen.
Sehr, sehr interessant.
Bei der Gesichtserkennung weiß man, dass wenn ganz bestimmte Bereiche des Gesichtes durch winzige Veränderungen verändert werden, dann kann die Gesichtserkennung die Person nicht mehr identifizieren.
Und wir gehen bei der Betrachtung eines Bildausschnittes auch so vor. Wir nehmen an, der Bildausschnitt zeigt eine Katze. Dann suchen wir auf einer zweiten Erkenntnisstufe nach Merkmalen die die Annnahme bestätigen. Es reicht eine falsche Stelle und die Annahme, das Bild sein eine Katze ist widerlegt.
Mir scheint es gibt eine Lösung für dieses Problem bei dem irrelevante Änderungen in einigen Pixeln zu einer anderen Klassifikation führen: man darf nicht alle Pixel eines Bildes oder Objekts gleich behandeln und gleich gewichten wie es scheinbar die künstlichen neuronalen Netze machen. Ich würde dagegen folgendes Vorgehen vorschlagen:
1) Suche im Bild nach Objektkandidaten, wobei eine Stelle im Bild mehreren verschiedenen Objektkandidaten zugeordnet werde kann, was sich in Wahrscheinlichkeiten ausdrücken lässt.
2) Für jedes potenzielle Objekt sucht man nun nach einer vom Training bekannten charakteristischen Merkmalsverteilung. Das ergibt wiederum Zuordnungswahrscheinlichkeiten
3) Untersuche in welchem Kontext das potenzielle Objekt erscheint und verwende wiederum das aus dem Training bekannte Muster der typischerweise benachbarten Objekte.
Warum dieses mehrstufige Vorgehen? Weil ich bei mir selbst mehrmals festgestellt habe, dass ich bei schwierigen Fällen der Objektidentifizierung diese Art mehrstufige Identifizierung anwende.
der übergang von k -> b ist aufgrund der diskreten struktur der ausgabewerte der neuronen nicht stetig. wenn es möglich wäre, die jacobi-matrix der hochdimensionalen funktion als 0 zu beweisen, könnte man die prinzipielle stabilität der ausgabe nachweisen.
Beunruhigend wäre der Umgang mit derartiger Erkenntnis, die “trainiert” worden ist, auf Grund menschlich (oder bärisch! [1]) erzeugter Texte, die also eine Übung darstellt, die bei “ChatGPT” die Einrichtung von ca. 170 Milliarden sogenannter Parameter führten, die einem menschlichen (oder bärischen!) Hirn-System in seiner Fähigkeit, Bewerkstelligung und seinem so “Leuchten der Neuronen” in puncto Zufälligkeit nicht unähnlich sind.
Wie genannte Schwächen entstehen, wenn unzureichend “trainiert” worden ist oder wenn unzureicheind Trainingsmaterial, das menschlich (und bärisch) bereit gestellte Texte meint. [2] [3]
Außerdem “blufft” zeitgenössische AI sozusagen, sie gibt auch dann Antwort, wenn sie unzureichend informiert, “trainiert” ist, hier lag eine Design-Entscheidung vor, die auch den Markt meinte.
Mit freundlichen Grüßen
Dr. W (der hier, für die Verständigkeit, einen sozusagen normalen, auch fehlbaren Zusammenhang erkennt, gerade auch bei zeitgenössischer AI)
[1]
Dr. W und “ChatGPT” haben insofern auch, zusammen, ein wenig über Inhalte der “Scilgs.de” gegrunzt, gequiekt, aber nie gewiehert.
[2]
Es gibt eine klar erkennbare Abhängigkeit zwischen all dem, was Menschen je gesagt und insbes. schriftlich niedergelegt haben und aktueller “maschineller Intelligenz”, diese Maschine ist von erkennenden Subjekten anhängig, besondere Eigeninitiative liegt nicht vor, sie ist ein “Inhalte-Sammler”, sie leidet (noch) sozusagen an der Kreativität.
Wobei Dr. W nicht weiß, woher sie für diese Maschine kommen wird.
[3]
Freund “ChatGPT” geht zudem probabilistisch vor, er rät.
Denkbarerweise hat eine an sich dulle Musikgruppe mit dem Namen ‘Kraftwerk’ irgendwie recht bekommen :
-> https://de.wikipedia.org/wiki/Die_Mensch-Maschine
Not that bad, Dr. W mag auch die Chickies :
-> https://www.youtube.com/watch?v=QxIWDmmqZzY
Ich möchte an dieser Stelle einfach darauf hinweisen, dass das menschliche Gehirn unter gewissen Umständen ebenso “Fehlleistungen” hervorbringt, indem beispielsweise irgendwelche zufälligen Merkmale zu vollständigen ( aber unzutreffenden ) Bildern ergänzt werden.
Auf der anderen Seite sollten wir nicht allzusehr erschreckt sein über die “KI”, sondern vielmehr über unsere häufig sehr simple Annahme der menschlichen “Intelligenz”, wir sollten nicht jeden Gedanken als “intelligent” vermarkten wollen.
Wir dürfen aber auch nicht vergessen, dass der “Sinn+Zweck” unseres Gehirns nicht das Hervorbringen von philosophischen Gedanken und Spökenkiekerei ist, sondern dass es bestmöglich unser Überleben und das unserer Nachkommen unter reichlich “natürlichen” Umgebungszuständen gewährleisten soll, allein mit der Bewertung der Informationen, die es über unsere “5” Sinne erhält.
Karl Maier,
es gibt viele Bücher über Sinnestäuschungen. Das fängt an bei den Farben, die sich bei wechselndem Kontrast zu ändern scheinen.
Das geht über Formen, wo Kinder etwas anderes sehen als Erwachsene, bis hin zu “erschreckenden” Fehlleistungen, wenn die Fotokamera etwas anderes erkennt als unser Auge.
Salvador Dali hat es zur Perfektion gebracht, Bilder zu malen, die aus unterschiedlicher Entfernung etwas vollkommen anderes zeigen.
Ich meine, das in Ihrem Beispiel auftretende Problem hängt auch damit zusammen, dass nur ein „Einzelbild“, z.B. einer Katze, ausgewertet wird, sowohl beim Training als auch in der Anwendung.
Ein natürliches neuronales Netz wertet sozusagen mehrere „Bewegtbilder“, also auch die „Dynamik“ der Muster aus. Derartige Videos sind schwerer zu verfälschen.
Zum Scherz wurde im TV einmal, ich glaube es war ein Hund, mit künstlichen Teilen „bekleidet“, so dass er, zumindest bei Dunkelheit, wie ein riesiges, auf der Straße Menschen erschreckendes „Spinnentier“ aussah.
Ein autonomes Auto soll in ein die Straße querendes, sehr langes Lastauto hineingefahren sein, weil es die aufgemalten Landschaftsbilder (Werbung) für eine echte Landschaft und nicht für ein Hindernis gehalten hat.
Vermutlich kann derartiges nur so wie auch Martin Holzherr meint, verhindert werden, wenn automatisch nach denkbaren Alternativen gesucht wird, wie es auch ein Mensch tun würde. Die KI meldet, z.B. ein nicht typisches „Katzenbild“ zu sehen….
Die KI muss eben immer weiter entwickelt werden um Fehler zu vermeiden die auf falsche Interpretationen, z.B. der „Bildmuster“ beruhen.
Vermutlich entstehen sogar Kriege, weil „Muster“ (z.B. der „Schwäche“) problematisch interpretiert werden.
Die menschliche Aufmerksamkeit und Interpretation ist stark durch Erwartungen bestimmt, etwas, was sich etwa im Experiment mit einer Gruppe von Ballwerfern zeigt unter denen plötzlich ein Gorilla auftaucht. Man liest dazu:
Siehe dazu dieses Video
Wie bei der Intelligenz unterscheiden sich die Menschen.
Frauen achten auf andere Einzelheiten, die Männer nicht mal ahnen.
Vor Ihnen läuft ein Mann mit Sportschuhen und einem gestrickten Pullover.
Der Mann schaut auf den Sportschuh, ob das ein Asics ist oder ein Puma.
Der Frau fällt auf , dass der Pullover einen Strickfehler hat.
Und das Kind bemerkt, dass der Mann eine Glatze hat.
Die KI muss das alles bemerken, und wenn sie das kann, dann ist sie dem Menschen überlegen.
Aber die KI merkt dann vielleicht nicht, dass da ein Gorilla vor ihr läuft.
Es geht wohl darum, dass AI an sich klare Zusammenhänge “auf einmal” nicht erkennt:
Also gerade nicht um die Entsprechung von Erwartung.
Wobei Dr. W davon ausgeht, dass wie gemeinte AI noch besser lernen könnte und auch wird, kein besonderer Punkt zur Aufregung vorliegt.
MFG
WB
Elektroniker
Die Potemkinschen Dörfer sind ein Beipiel für die Täuschung.
Das Beipiel mit der aufgemalten Landschaft an einem LKW, das sind Anfängerfehler. Und es zeigt, dass die Bilderkennung noch zweidimensional programmiert war. Und……die Bilderkennung sollte auch mit der Lauterkennung gekoppelt sein. Ein LKW fährt ja nicht geräuschlos.
Und….es sollten auch Sensoren tätig sein, die überprüfen, ob man überhaupt auf einer Straße fährt und nicht in einem Flugzeughangar.
Genau hier :
…gerne belegend werden!
Quellenangaben nicht scheuend.
An sich ist es auch für den hier gemeinten Nasentrockenprimaten oder Trockennasenprimaten so, dass er so sieht, oder “sieht”, wie er erwartet, sog könnte auch jedem bärischen oder menschlichen Beobachter klar sein, sein Hirn sich annähernd und übersetzend.
Der grundsätzlich näherungsweise, ausschnittsartig und an Interessen (!) gebunden erfasst, um in der Folge näherungsweise, ausschnittsartig und an Interessen (!) gebunden theoretisieren, Sicht zu bilden, versucht.
Diese ‘minimale Menge zufälliger Abweichungen’ bleibt erklärungsbedürfig,
bereits der hiesige werte Inhaltegeber mit einem sozusagen Sägezahn im Mau könnte ga-anz anders verstanden werden, von einigen.
Simplifizierung hier das Fachwort.
MFG
WB