

Architecture Innovation Accelerates Artificial Intelligence
BLOG: Heidelberg Laureate Forum

As part of the first day of the Virtual Heidelberg Laureate Forum (HLF) David A. Patterson, who won the 2017 ACM A.M Turing Award “for pioneering a systematic, quantitative approach to the design and evaluation of computer architectures with enduring impact on the microprocessor industry,” shared a presentation titled Architecture Innovation Accelerates Artificial Intelligence.
To begin, Patterson gave a brief overview of the history of AI: it started with top-down approaches where a programmer would attempt to describe all the rules with the proper logic for the machine, but other researchers argued that was impossible and instead advocated for a bottom up approach where you feed the machine data and it learns for itself, i.e. machine learning, which has proven very successful. One type of machine learning is deep neural networks (DNN), which has generated a lot of the recent advances in AI.
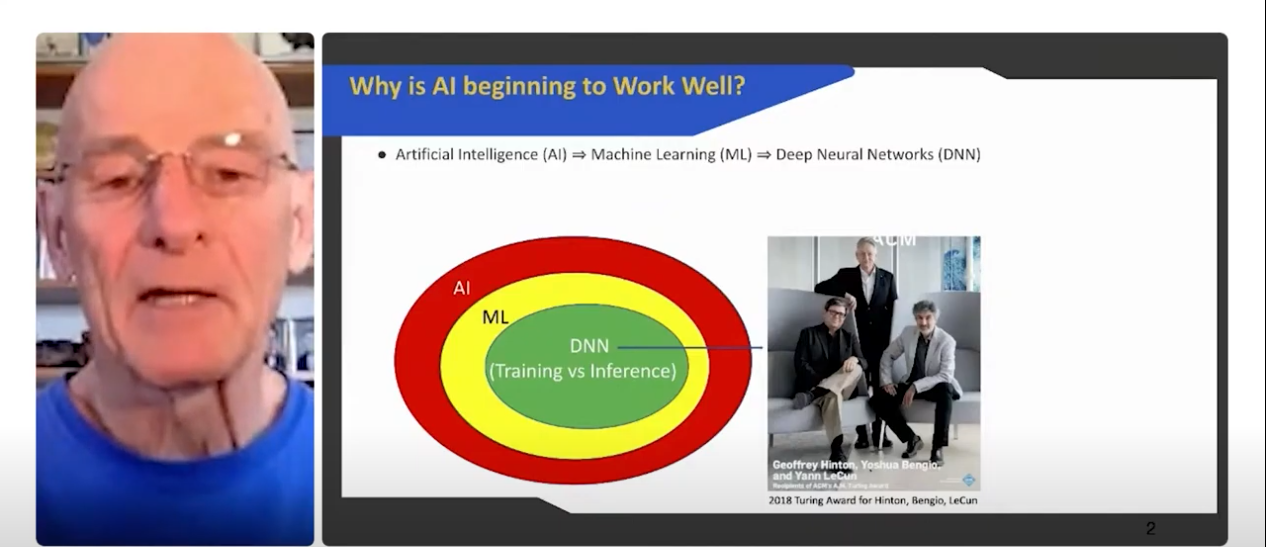
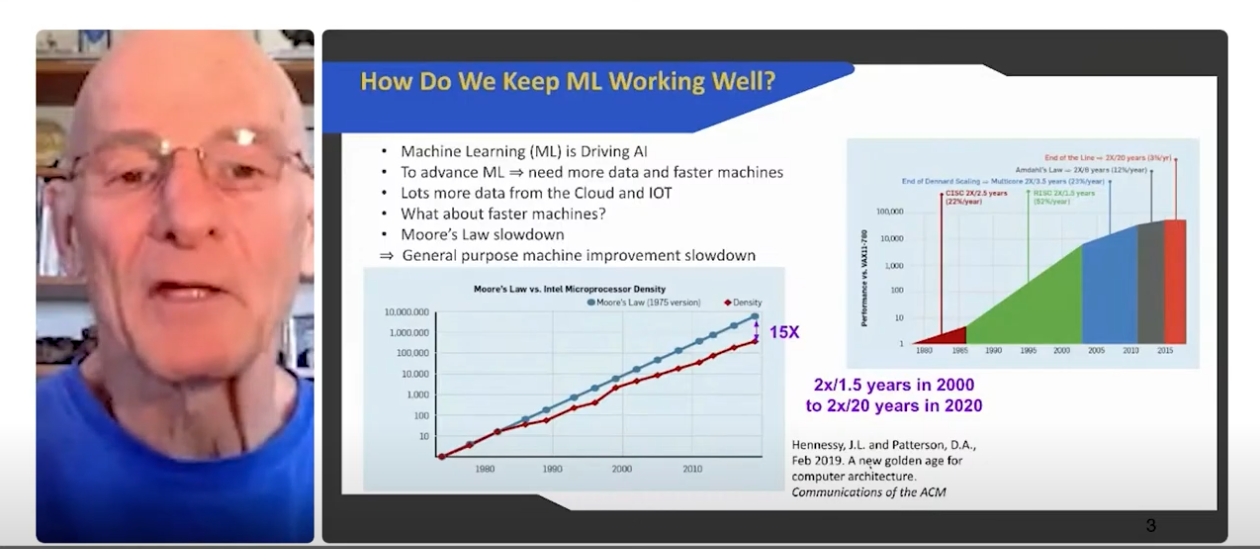
The algorithms that power DNN aren’t new, so what has changed to make these systems viable currently? These days we have access to a lot more data and much faster machines, allowing DNNs to train themselves efficiently. Unfortunately, Moore’s Law — the observation, made by Intel co-founder Gordon Moore in the 1970s, that if $1 gets you 1,000 transistors today then in approximately two years $1 will get you 2,000 transistors — has slowed down. The number of transistors used to track one to one with computer speed so that every two years or so you could double the speed of the computer, but that relationship no longer holds. Patterson said we are currently off by a factor of 15 between predicted transistors per chip and reality. Thus we will need to come up with new ways to improve computing speed and power machine learning systems.
The current approach to overcome these limitations are Domain Specific Architectures (DSA), which do a few things well but are not good at arbitrary programs. Patterson said that “five decades of experience in designing general purpose architectures may not apply.” If you are a company in this space what do you do?
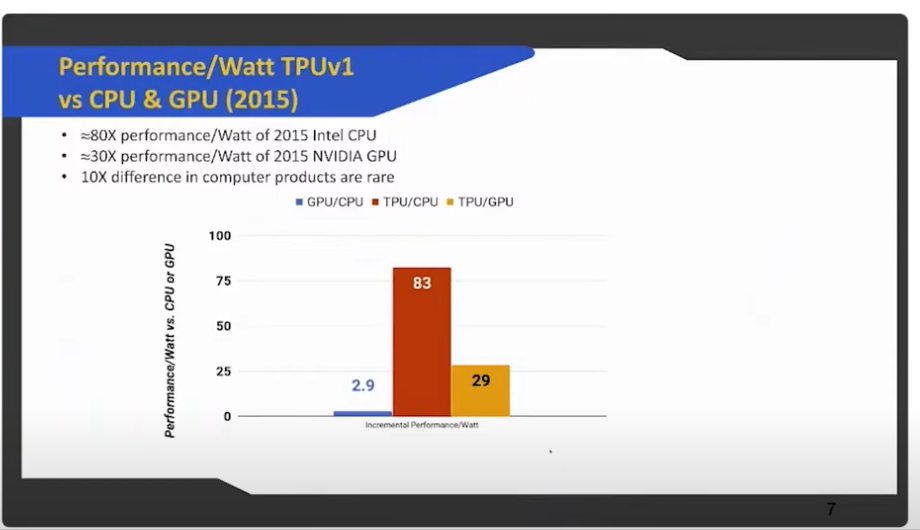
Patterson shared an example from recent history: In 2013 Google calculated that if 100 million users started doing DNN three minutes per day on CPUs they would need to double the size of their data centers, so they started an emergency project whose goal was to make a factor of ten improvement over existing CPUs and GPUs. Within 15 months they went from ideas to working hardware and software. The TPUv1 that Google designed had around a 80X performance per Watt of the 2015 Intel CPU and a 30X performance per Watt of the NVIDIA CPU because they were using 8-bit integer data rather than 32-bit floating point data and they dropped general purpose CPU/GPU features, which saves area and energy.
TPUv1 was used for ML inference, next Google created the TPUv2 that was designed to do ML training, which requires more computation, more memory, and bigger data. Google decided to build into the TPUv2 chips four Inter-Core Interconnect (ICI) links that each runs at 500 gigabits per second. Thus the links are approximately five times faster than those in a classic data center network at only one tenth of the costs. Eventually they created TPUv3 which further improved the system performance.
This is all to say that making domain specific architectures works and if we want to continue to improve ML systems we will need to continue developing new and improved DSAs. The recently released GPT-3 (Generative Pre-trained Transformer) neural network model has gained a lot of buzz for being able to successfully mimic human language. The big breakthrough, as Patterson put it, is simply being 100 times bigger than GPT-2. GPT-2 had only 1.5 billion parameters in comparison to GPT-3’s 175 billion. In machine learning the size of your data set and speed of your computer matter; thus computer architects will play a vital role in the future of AI.
Watch the full recording of David Patterson’s talk on Youtube here.
GPT-3’s 175 billion parameters also mean, that Deep Learning Architectures can be memory constrained. Potential users ofGPT-3 indeed reported, that they coudn‘t run it because of lack of memory.
Furthermore loading such massive amounts of data from the memory into the cpu imposes a large runtime overhead.
The solution could be memresistor architectures, which combine memory and computation.