

Warum sammelt Meta Daten?
BLOG: Con Text
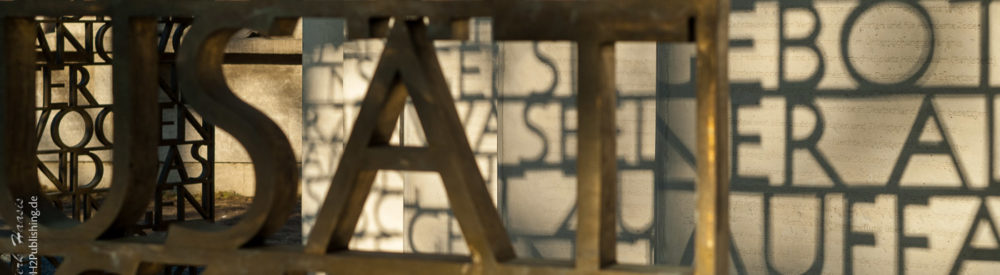
In der gegenwärtigen Debatte um das Aushorchen aller Menschen – ich schrieb dazu bereits an anderer Stelle – wird von einigen Apologeten gerne das Argument verwendet, es ginge ja nur um Metadaten, die eigentlichen Inhalte würden gar nicht abgehört.
Das ist möglicherweise richtig, schon weil es selbst den Riesenapparat der britischen und US-amerikanischen Geheimdienste überfordern würde jede E-Mail zu lesen, jedes Telefongespräch anzuhören, jedes Instagram-Foto anzuschauen. Allerdings ist das auch gar nicht nötig, denn die Datenaufbereitung kann ohne Schwierigkeiten von Computern erledigt werden. Mit allen Konsequenzen.
Das erste, was für eine vernünftige Indizierung nötig ist, sind die Metadaten, also Daten über die Daten. Wo kommen Nachrichten her? Wo gehen sie hin? Wer kommuniziert mit wem? Welche technischen Mittel wurden verwendet? Welchen Weg nahm eine Nachricht?
Schauen Sie sich dieses Bild an:

Der Inhalt des Fotos ist zu sehen. Es handelt sich um ein Kunstobjekt, Stahlbögen, die in einem Umfeld moderner Stadtarchitektur stehen. Je nach Kenntnisstand des Betrachters, kann dieser noch mehr sehen, z.B. den Standort, mglw. erkennt er den Künstler, der das Objekt geschaffen hat. Außerdem sieht er selbstverständlich Techniken des Fotografen sowie Interpretationen.
Zu diesem Foto gibt es Metadaten, die beispielsweise über Bordmittel des Betriebssystems – in diesem Fall Windows 7 über Dateieigenschaften – sichtbar gemacht werden können.

Windows Explorer zeigt nicht alle Metadaten an, andere Programme allerdings schon – und keines davon ist ein besonderes Geheimnis. So sieht es aus, wenn Phil Harveys EXIFTool unter der Oberfläche von Geosetter so richtig in die Metadaten einsteigt:

Ich habe in beiden Screenshots einige Daten unkenntlich gemacht.[1]
Der größte Teil der Metadaten für Fotos ist technischer Natur und hilfreich, um zu erkennen, wie ein Fotograf seine Fotos macht. Sie werden automatisch von Kamera und Bearbeitungssoftware hinzugefügt. Die Daten, die über EXIFTool ausgelesen wurden zeigen z.B., dass ich ein Nikon Fisheye für DX-Kameras verwendete, danach mit IDimager und Lightroom am Bild arbeitete.
Interessant sind aber auch Daten, die in die Irre führen – wer genau hinschaut, sieht Apple erwähnt, obwohl das Foto nie mit einem Apple in Kontakt kam[2] – oder fehlen. Das Bild wurde von mir nämlich nur durch IDiamger und Lightroom durchgereicht, bearbeitet wurde es in Nikon Capture NX 2.[3] Wer oberflächlich in die Liste schaut, wird ein wenig verwirrt, da oben eine D200 als Kamera angegeben wird, beim Objektivprofil aber die D90 genannt wird.
Aus den automatisch erstellten Metadaten alleine dieses einen Fotos lässt sich schon einiges über mich und meine Arbeitsweise erfahren. Stehen einem mehrere Hundert oder gar Tausende Dateien zur Verfügung …
Konkordanz
Neben den automatischen finden sich aber auch manuell erstellte Metadaten, die für die tägliche Arbeit wichtiger sind, die Schlüsselwörter [keywords], Titel, bestimmte hierarchische Beschreibungen aus Nachrichtenagentur- und Zeitschriftenarbeit. Bei Fotos werden die immer noch per Hand eingegeben, obwohl es absehbar ist, dass weiter fortgeschrittene Algorithmen zur Motiverkennung das bald auch können. Es ist nicht so weit, von der Erkennung von Gesichtern zur Benennung.
Texte automatisch komplett zu erfassen, ist erheblich einfacher, und wir machen es täglich. Ein nettes Spielzeug ist die Wortwolke, die es statisch und dynamisch gibt. Ein kleines Programm sortiert alle Wörter eines oder auch ganz vieler Texte, gewichtet sie nach Anzahl und zeigt sie dann mehr oder weniger hilfreich und schön an.

Je größer das Wort, desto häufiger wurde es verwendet.
Mit derselben Methode plus ein paar kleinen Erweiterungen, erstellen Sie automatisch eine komplette Konkordanz sämtlicher Wörter auch umfangreicherer Texte, inkl. Ort des Vorkommens [in gedruckten Werken die Seiten- und Zeilenzahl, in eBooks die absolute Location] und Kontext.
Und genau das machen NSA, GCHQ, BND und viele, viele andere Sicherheitsbehörden.
Auswertung
Da die Menge der gesammelten Daten viel zu groß ist, um in ihrer Totalität per Hand ausgewertet zu werden, lassen wir nun diverse Algorithmen zur statistischen Vereinfachung[4] auf sie los. Das Ergebnis sind Tabellen und Grafiken, die wiederum anderen Algorithmen zugefüttert werden, um mögliche Muster zu erkennen.
Schlägt eine Rechenprozedur an, geht ein rotes Licht an, die Sirene heult – und ich schaue zu viele Action- und Politthriller aus Hollywood. Aber im Prinzip passiert genau das, die Computer melden den menschlichen Controllern Auffälligkeiten. Auch hier wird langfristig der menschliche Faktor am Ende der Kette rausgenommen werden. Wozu menschliches Versagen riskieren, wenn man sich auf unbestechliche und nie irrende Maschinen verlassen kann. Wie in Terminator zum Beispiel.
Am Anfang der Kette wird immer der Mensch stehen, denn irgendwer muss die Algorithmen entwickeln. Irgendwer muss Bedeutung schaffen. Irgendwer muss der Maschine sagen, welches Verhaltensmuster verdächtig ist und welches normal ist. Maschinen können Bedeutung nicht erkennen, vielleicht, weil dazu Kreativität nötig ist – exakt das, was wir bisher durch Maschinen ausschließen wollen. Sie sollen langweilige Routine abarbeiten.[5]
Gesammelt
Metadaten sind nicht nur problematisch, weil sie helfen Bewegungsprofile von Individuen zu erstellen oder soziale Netzwerke[6], sie erzählen eine ganze Menge mehr über einzelne Personen. Und Metadaten sind nicht irgendwelche abstrakten Entitäten, die harmlos sind, solange ‘man nichts zu verbergen hat’. Auch die Inhalte selbst sind Metadaten und werden entsprechend aufgehoben und ausgewertet.
[1] Möglicherweise sicherheitsrelevante Daten über mein Computersystem, außerdem private Daten.
[2] Vermutlich benutzte IDimager eine Quicktime-Bibliothek.
[3] Wer auch mit Geosetter/EXIFTool und Nikon CNX2 arbeitet, kann das an der Warnung ganz oben erkennen.
[4] Der Sinn statistischer Methoden ist eben gerade die Verringerung der Datenmenge auf wieder einfach zu handhabende Koeffizienten.
[5] Maschinen können deswegen auch keine Ironie erkennen. Allerdings schaffen das auch viele Menschen nicht, die dann wiederum besonders geeignet sind, eben jene Arbeit zu machen, die in Sicherheitsbehörden gefordert ist.
[6] Hier sind nicht Dienste wie Facebook gemeint, sondern jene von Soziologen untersuchten Vernetzungen von Menschen zu Gruppen auf verschiedenen Ebenen und mit verschiedenen technischen Möglichkeiten.
man kann damit Geld verdienen
Der wichtigste Grund Daten zu sammeln, ist der, dass man damit seinen Lebensunterhalt verdienen kann. Das Einkommen eines Datensammlers wird höher sein, als das eines normalen Arbeiters oder Angestellten. Der Datensammler hat kaum Stress, seine Arbeit muss nicht mal funktionieren. Die hoch bezahlten Chefs der Datensammler werden sich im wesentlichen damit beschäftigen, Managementstories zu erfinden, die die Geldgeber davon überzeugen, dass das Datensammeln mehr Nutzen bringt, als es kostet.
@ adenosine
-> Wie naiv… wieder mal erster Gedanke nur an Geld. Zeigt, wie dissonant die Menschen denken.
Analog zum Exif-Datensatz wird es das auch für jede Textdatei geben. Ein Datensatz, der Auskunft darüber gibt, woher sie stammt, auf welchem Betriebssystem mit welchen Identifikationsmerkmalen und welcher Hardware die Datei erstellt wurde und womöglich auch, Speicherorte (Plural) also alle Speicherorte, die gerade diese eine Datei(Version) jemals hatte. Zeitstempel sind obligatorisch.
Da sind dann lückenlose Überwachungsszenarien auch nur noch halb so dramatisch relevant, weil sowieso jeder Textinhalt und Datei jederzeit zurückverfolgt werden kann und somit der Urheber relativ treffsicher ermittelt werden kann.
Bei einer e-Mail ist das ja nicht anders. Ursprung und Verlauf sind immer nachvollziehbar. Und selbst, wenn eben keine Echtzeitverfolgung stattfindet, ist sie dennoch verfolgbar, weil die e-Mail auf einem Betriebssystem erstellt worden sein muß, dessen Identität sich in der versendeten e-Mail in Metadaten versteckt findet und so faktisch irgend Anonymität nicht besteht.
Automatische Auswahl verdächtiger Muster
Natürlich muss der Maschine deren Verhalten-Ansatz vorgegeben werden – allerdings kann das mittlerweile sehr allgemein erfolgen. Theoretisch kann die Maschine dann anhand der Daten selbst gewichten, was häufiger vorkommt, was seltener – wie selten und deshalb wie auffällig oder verdächtig. Ja sie kann das sogar nach einzelner Person, Zeit, Ort etc. gewichten und das ziemlich automatisch.
Darum sind die Metadaten ja so wichtig (wichtiger als Einzeldaten über irgendwelche zu vereitelnden Vorkommen), denn umso mehr davon der Maschine vorliegen, umso autonomer kann sie entscheiden – und umso autonomer wird sie zuverlässiger entscheiden als jeder Mensch…
Könnte man also davon ausgehen, dass die Datensammler wirklich in unserem Interesse sammeln – dann sollten wir ihnen sogar nahezu alle Daten überlassen, ihre Irrtumswahrscheinlichkeit würde dann geringer. Fehler würden nahezu sicher ausgeschlossen. Allerdings könnte man damit auch perfekt alle oder einzelne Menschen manipulieren.
Im Datenstrom scheinbar mischwimmen
Zukünftige Terroristen, Systemunterwanderer und Menschheitsauslöscher werden das Wissen über die allgegenwärtige Datenauswertung in ihre Aktivitäten miteinbeziehen. Doch nicht kommunizieren oder wenig kommunizieren macht dann schnell ebenso verdächtig wie es das mit den falschen Leuten kommunizieren heute macht. Um der Entdeckung zu entgehen empfiehlt sich vielleicht der Identitätsdiebstahl oder die Identitätssimulation. Vielleicht kommt man ja als Dierk Haasis besser durch die Welt.
Etwas Humanes scheint mir wirklich neu in der Welt der elektronischen Kommunikation und der unbegrenzten Datenspeicher: die meisten akzeptieren, dass sie von nun an nur (?) ein Partikel in einem Vielpartikelsystem sind. Und je voraussehbarer dieses Partikel sich verhält, desto besser kommt diese Partikel durchs Leben.
Wenn die Überwachungssysteme, welche ihre Netze aufspannen und niemand durchschlüpfen lassen wollen, tatsächlich der Prävention von Straf- und Terrortaten dienen sollen, dann kann das nur bedeuten, dass immer mehr Aufwand getrieben werden muss. Das letzte Ziel eines “Terroristenfilters” muss es sein die Bedeutung der Daten zu entschlüsseln. Und wirklich effektiv und zuverlässig ist das System nur, wenn ihm fast nichts entgeht. Der Traum der Futurologen unter den NSA-Cracks wird deshalb das obligatorische Brain-Computer-Interface (BCI) sein. Vielleicht ist der Tag nicht mehr so fern, wo nur der eine Einreisebewilligung in die USA erhält, der über ein BCI (Brain-Computer-Interface) verfügt und der es für die NSA freischaltet.
Natürlich wird die NSA unter strengen gesetzlichen Vorlagen arbeiten- das jedenfalls wird sie dann genau so wie heute behaupten.
Für Chinesen könnte eine Einreise in die USA in dieser höchstens noch eine Generation entfernten Zukunft möglicherweise einfacher werden als für den Durchschnittseuropäer. Vor allem dann, wenn Chinesen in Zukunft gleich schon nach der Geburt ein BCI implantiert bekommen und die Einreise in die USA dann nur einen Datenabgleich zwischen NSA-China und NSA-USA erfordert.
Meta Auswertung
Es ist interessant Anhand gewählter Sprachmittel eines Beitrags zu beurteilen, ob ein Autor zur Versachlichung eines Themas beitragen will oder auch nicht.
“Aushorchen” –>Orwell et al.?
“Terminator” –>Hollywood !!
Schade, scheint sich nicht zu lohnen hier tiefer einzusteigen, obgleich es interessante Ansatzpunkte im Artikel gibt. Aber das Wetter ist einfach zu gut um mal wieder gegen höchstkompetente Voreingenommenheit anzukommentieren.
Unterschätzt
Martin Holzherr:
“Zukünftige Terroristen, Systemunterwanderer und Menschheitsauslöscher werden das Wissen über die allgegenwärtige Datenauswertung in ihre Aktivitäten miteinbeziehen. “
So ist es . Bei der ganzen Debatte wird völlig vergessen , daß sich Straftäter und Terroristen schon immer angepaßt haben an neue Entwicklungen , was die Sinnhaftigkeit der Datenwut schneller als erwartet ins Reich der Absurdität verbannen könnte.