

About Open Access – an Interview with Bora Zivkovic
BLOG: Fischblog

Among the many interesiting people I met at the Lindau Nobel Laureate Meeting was Bora Zivkovic, the online Community Manager of the Open Access Journal PLoS ONE. On one occasion Bora participated in a panel discussion on Open Access, together with Jason Wilde from Nature Publishing and Nobel Laureate Sir Harold Kroto.
Lather that day I had a lenghty interview with Bora, which resulted in this article at spektrum.de (in german, a translation can be found at Mad Scientist Junior). However, there is far more in that interview than one article can convey, so here is the interview in full length, slightly edited for clarity.

Lindau: v.l.: Paula Schramm, Bora Zivkovic, Jessica Riccò
About the relationship between PLoS and Nature Publishing
In a sense it’s a friendly relationship, because a lot of people in the two houses know each other well and have been Colleagues for years. Where the competition comes from is that PLoS is a new organisation that can move much faster, pushing the changes, leading the changes in the publishing business model. Probably a bit too fast for the taste of Nature, who has a big brand and can not afford to move as fast, because they have responsibilities to their company, their stockholders and their brand. So I think there is mutual respect, but there’s also a clash between two business models mainly the in way of forces that push changes toward open access and towards a new way of communicating science much much faster than Nature would like to see.
Fake articles and peer review quality in open access
As far as the faked paper [accepted for publication by The Open Information Science Journal] is concerned an Article in New Scientist that made the connection to open access. There are two ways to answer that.  First, that there is an organisation or association of publishers of open access, which does not accept Bentham. Bentham is like a persona non grata in the open access world. Just because they call themselves open access nobody really knows how they really operate. It doesn’t mean that they are in any way representative of, or even a member of the open access world. Second is that the paper that was submitted to Bentham, you know, it was presented as if it was as experiment testing the strength of open access. But this really hasn’t anything to do with open access, but with the strength of peer review at a particular journal. And they picked a particularly lousy journal to do that. If a real scientist did that ther would be some kind of control, you pick an open access or a full access journal of the same strength and do the same experiment to both of them. Even then it would not say anything about the strength of open access or full access, but about the strenghts and weaknesses of peer review of that particular manuscript in that particular journal.
First, that there is an organisation or association of publishers of open access, which does not accept Bentham. Bentham is like a persona non grata in the open access world. Just because they call themselves open access nobody really knows how they really operate. It doesn’t mean that they are in any way representative of, or even a member of the open access world. Second is that the paper that was submitted to Bentham, you know, it was presented as if it was as experiment testing the strength of open access. But this really hasn’t anything to do with open access, but with the strength of peer review at a particular journal. And they picked a particularly lousy journal to do that. If a real scientist did that ther would be some kind of control, you pick an open access or a full access journal of the same strength and do the same experiment to both of them. Even then it would not say anything about the strength of open access or full access, but about the strenghts and weaknesses of peer review of that particular manuscript in that particular journal.
The impact of open access on scientific publishing
I see it as a process that is going to have several stages or phases, and open access itself is one of those phases. It is a feedback system between open access changing science communication, and the science communication that is enabled by open access itself changing open access. The first stage of this process, which is coming to an end now, is that all those scientific journals are going to post their papers online, because if you’re not online you don’t exist. At the second stage economic reality will force many journals, and eventually all journals, to abandon printing on paper. Everything is to be only online, because the biggest expense in publishing of any kind is preparation for print, the printing itself, the paper, the ink, the trucks and truck drivers, then the distribution system. All that costs enormous amounts of money. So everything is to come online. Will that mean that there are no printed papers? No. The printing will move from the producer to the consumer. You download a paper, you click print on your browser and your printer prints it out. It’s like when you go to the grocery store, you’re picking up your stuff from the shelves and check out yourself. Fifty years ago you would go to the same store and there would be someone to pick up the stuff from the shelves for you, and doing all the calculating and checking out for you. In many industries the expense has shifted, and the physical effort have shifted from the producer to the consumer. Printing is going to shift asw well. You print your own papers at home, instead of having it delivered.

That is the second stage. So when everything is online, it is only natural that everything is going to get open access in some way because people are averse to paying for stuff online. No one is going to pay sixty dollar for a paper just because he finds the title and the abstract interesting. You don’t know if it’s what you’re looking for. If you’re a physician in Chad and you have a patient and need to look up the symptoms or the therapy, you can’t afford to use google scholar and see 20.000 hits and pay sixty dollars for each paper until you find the one that answers your question, which you have to do pretty fast, because you have a dying person there. It’s not going to work. There will be a lot of push from the consumer side for the journals to open. For some journals micro-payment will work, but some will be completely open access.
Not only free but open
I have to make a distinction between free and open here, free is online, you download it and you don’t have to pay for it. But Open Access has another dimension to it, it’s not just that you can read it for free, you can do all sorts of stuff to it. Which means that you can copy it and put it on your website, you can translate it and republish it. You can take an image out and put it on your blog to discuss the paper. You can re-analyze the data, using a different software or a different model or whatever, and then you can re-analyze the data again, or take the data and do something more with it. So you are also able to re-use the paper, as long as you are properly attributing where the information is coming from. If it’s online, you link directly to the paper, if it’s offline, you reference where that information comes from, where you translated it from, where the image is from. When that happens, when all the raw data are part of the paper, then it’s not just humans that take the data, machines can go and scan the entire scientific literature of history of the universe and find patterns, find data, find similarities, find connections and really speed up the purpose of science.
How scientific papers will evolve
In the next step the online papers are going to change, because the format of the scientific paper is in itself an anachronism. It is the optimal format for paper, for print. It is not optimal for the web. Once you don’t have the printed version of the journal any more, and all the papers are online you can start playing with the format. Which means you don’t need an traditional introduction and materials and methods and supplementary data, it’s going to slowly evolve into somthing different. There will be movies and audiofiles and software embedded right in the paper.
As more and more people adopt this kind of openness  the paper will stop being a discrete entity in the sense of something that has a publication date, where all of it is published at one moment in one journal. Rather different parts of a study will show up at different times. Somebody somewhere online will come up with the idea. Then another one is going to rephrase that idea and form a hypothesis, and finally someone will come up with an experiment and everyone is going to comment on that. There’s massive peer review at every step, in form of comments that refine the experimental protocol. In the end a person is going to say, “Hey, I got that equipment in my lab to do this experiment and I’m gonna do it.” And he then directly screens the raw data from his machine to the web, another person is trying to analyze the data, and others interpret it, with many many people commenting on it and constantly refining the result and correct and criticise, until after some time, that can be a week or years, you have a unit where you say, OK, that’s what we’ve got, that was the idea. But it’s not a paper that was published in one day, or over a period of time. There are pieces connected together in the same place, or linked together, so you don’t have to shop around to collect the different pieces. It’s easier from one entry point where you can see everything about it. And there’s going to be people who have the talent of synthesis, to monitor all that ongoing research and write review papers.
the paper will stop being a discrete entity in the sense of something that has a publication date, where all of it is published at one moment in one journal. Rather different parts of a study will show up at different times. Somebody somewhere online will come up with the idea. Then another one is going to rephrase that idea and form a hypothesis, and finally someone will come up with an experiment and everyone is going to comment on that. There’s massive peer review at every step, in form of comments that refine the experimental protocol. In the end a person is going to say, “Hey, I got that equipment in my lab to do this experiment and I’m gonna do it.” And he then directly screens the raw data from his machine to the web, another person is trying to analyze the data, and others interpret it, with many many people commenting on it and constantly refining the result and correct and criticise, until after some time, that can be a week or years, you have a unit where you say, OK, that’s what we’ve got, that was the idea. But it’s not a paper that was published in one day, or over a period of time. There are pieces connected together in the same place, or linked together, so you don’t have to shop around to collect the different pieces. It’s easier from one entry point where you can see everything about it. And there’s going to be people who have the talent of synthesis, to monitor all that ongoing research and write review papers.
Will Open access change the way science is done?
I think that’s going to happen. It’s not a proposal, it’s a prognosis. I think it is inevitable that we get there, the only thing I do not say is how fast, because there will be a lot of resistance, because scientist are reall very conservative and risk-averse in changing the system. But there are pioneers that are going to lead the way. They are going to get us to that point where research is put directly online in real time. There will be no such things as journals any more, only platforms for self-publishing, where massive peer-review is going on in real time. What’s going to happen is the evolution of a system that assigns reputation to individuals depending on their contribution to the process. That is the key, I think. Once you can gain scientific reputation by your online contribution, theoretical work, commenting, or peer-reviewing others, then people will participate
About reader contribution at PLoS
Commenting at PLoS is actually better than I expected. I think about 15 percent of our papers have comments or notes on them, which is actually pretty good, considering that PLoS ONE is just two years old. Which means that the oldest papers are just two years old. I don’t expect too much commenting right now, because you need more research to be done before you can really evaluate where the paper fits in, what’s really important or not important. Right now commenting is very impressionistic: Oh, I like the paper or I don’t. But it takes work, it takes more data before you can come back to a paper and say something specific about it.
It will take a couple of years, depends on the area of science until you can see where the paper fits in. And only then people will be commenting, because they have something to say.
Commenting on papers is still in its very early stage.  When you consider my vision about dynamic papers and all that stuff. That’s probably in a fifty years from now, when the leaders of science are going to be the kids of today’s generation, for whom putting content online will be second nature, you don’t think about it, you just do it. The second is the platform, If you have a scientific paper it looks very formal. If you have that dynamic system that doesn’t look as formal, it’s much easier for people to cross the threshold of actually posting a comment.
When you consider my vision about dynamic papers and all that stuff. That’s probably in a fifty years from now, when the leaders of science are going to be the kids of today’s generation, for whom putting content online will be second nature, you don’t think about it, you just do it. The second is the platform, If you have a scientific paper it looks very formal. If you have that dynamic system that doesn’t look as formal, it’s much easier for people to cross the threshold of actually posting a comment.
About the quality of comments at newspaper websites
Newspapers are a very special case – I don’t know how to put it diplomatically – they don’t know to run comments. They have this absolutely idiotic idea that people posting comments have the right of free speech.  It’s your site, you moderate the comments, and if they say something stupid, you delete. There is no freedom of speech in comments on your article, that’s an absolutely ridiculous idea. People have traced this to a particular court case in the U.S., where the newspaper’s newsroom politic is interpreted. For them it was either – or: Either you don’t have comments or you let everything pass. And when you let everything pass you have all sorts of idiots writing idiotic comments, which then poisons the well for everyone else. Intelligent people won’t want to comment, because they don’t want to add to the cacophony, so you only have only the most extreme an unpleasant people commenting on your article. When a journalist sees that he’ll think ”That’s the online discourse?” They have a very skewed view of what online discourse is and can be. In comparison, go to some smart scienceblogs and see, there is intelligent discussion, no one is calling anyone a name and they are discussing various mathematical models in the comments of my blog post. Newspapers could have done that if they had any brains. That was not very diplomatic.
It’s your site, you moderate the comments, and if they say something stupid, you delete. There is no freedom of speech in comments on your article, that’s an absolutely ridiculous idea. People have traced this to a particular court case in the U.S., where the newspaper’s newsroom politic is interpreted. For them it was either – or: Either you don’t have comments or you let everything pass. And when you let everything pass you have all sorts of idiots writing idiotic comments, which then poisons the well for everyone else. Intelligent people won’t want to comment, because they don’t want to add to the cacophony, so you only have only the most extreme an unpleasant people commenting on your article. When a journalist sees that he’ll think ”That’s the online discourse?” They have a very skewed view of what online discourse is and can be. In comparison, go to some smart scienceblogs and see, there is intelligent discussion, no one is calling anyone a name and they are discussing various mathematical models in the comments of my blog post. Newspapers could have done that if they had any brains. That was not very diplomatic.
About cranks and spammer at PLoS ONE
At this point in history commenting on papers is only available on PLoS papers, BMC papers and at BMJ. It is not very widespread. I wish it was on every journal because then the process of becoming comfortable with commenting would go faster. I’m drawn in two ways. On one hand I want to encourage more people to comment, on the other hand I want our comments to be intelligent and to add something of value to the paper – which means I have to create barriers. We at PLoS created some barriers in the form of registration. Even if you post under a pseudonym we know who you are and we know your real e-mail-adress, so we’re creating an artificial barrier for creationists and vaccine denialists and spammers.
So far I didn’t have too much work in the sense of validating coments or delete them. In the first two years there was almost nothing, only in the last six months I deleted several comments. There are a few spammers that come through, but they are quickly deleted. With others there is a gray area, should I delete it or not? Then I consult with the editor of PloS ONE or contact the author of that comment and tell that person what my complaint is. Sometimes we reach an agreement, that I delete and he or she comes back to repost, reword it, say the same thing but politely. And sometimes I have to made the decision to delete. So far we had only one person that posted a large number of comments that were trollish, and he was a very well-known online science troll, and I had the backup of the scientific community that he is a well-known crank and a special case of denialist, and it was almost expected from me to delete that person’s comments.
I have contacted the person – he is a crank, so I didn’t get avery positive response, but I copied all the comments, so if at some point some arbitration is needed I have the exact wording of everything I deleted. So you see I’m drawn between encouraging people to comment and gettng the right people to comment on the right things. It is not easy, for a cultural reason, because a lot of scientist are not very active online and also use the very formalised language they are using in their papers. People who have been much more active online, often scientists themselves, they are more chatting, more informal. If they don’t like something they are going to say it in one sentence, not with seventeen paragraphs and eight references. So those two kinds of people, those two communities are eyeing each other with suspicion, there’s a clash of cultures. The first group sees the second group as rude. The second group views the first group as dishonest. I think it will evolve into something in the middle, but it will take years to get there.
About the appeal Open Access holds for scientists
I think it’s the internet culture seeping into science. A lot of scientists, especially young ones, and with young I don’t mean necessilarily age but a mind set – there are sixty-five year old youngsters and eighteen year old oldsters as far as internet goes – and the internet ethic demands that something charged for online is absolutely unique, absolutely fantastic and absolutely necessary. But what you’re offering is not all three of those, so nobody is going to pay for it. Information wants to be free, people want it to be free. If it’s online it doesn’t cost you very much to put it out there, you don’t put a pay barrier in front of it.

Another big push is from people who do computational biology and physical chemistry who are very unhappy that their machines cannot mine the data from around the web. People who want to build the semantic web. You can’t have a semantic web with all information that is necessary for designing drugs if the search bots and spiders can not go behind the pay wall to find all information. So there are several pushes from different directions, from the scientists themselves and different types of scientists whose work requires open access, and on the other hand and on the other hand the people who grew up with and grew into the internet. For them the paywall is an anathema, an anachronism that reeks of 19th-century monopolism, it’s a very political and ideological thing not making anyone to pay for anything online.
About subscription fees
This is one of the reasons why some of the biggest proponents of open access are academic libraries because they are paying all those subscriptions. They have to choose them and they can’t afford them, because universities are giving them less and less money for subscriptions while journals are charging them more and more. They have to make cuts in journal subscriptions, which in turn hurts the researchers and institutions because they have fewer and fever journals they can access for free. Even journals in which they themselves publish. They got the grants, they pay the overhead to the libraries and they have to pay again to access their own papers.
So a big push is coming from the libraries and from the universities backing up their own libraries, because it is utterly ridiculous, it has nothing to do with market forces driving the prices, it is price-gouging for the profits of the publishers. There are different kinds of publishers, the bad boys are Elsevier, and on the other end of the spectrum of full access is something like Nature who are quite forward-looking. They aren’t that expensive and they are preparing themselves for the new world. Everybody is trying to position themselves for the new world, realizing that there will be changes. Those who fear the worst are digging in their heels and trying to reverse history. But it’s them who will be least prepared when history catches up with them.
Open Access business models
First, there is “Green” and “gold” open access. Green open access means the author retains the copyright, which can be negotiated with many journals, not only open access journals. The author has the copyright and usually deposits a copy of the paper in some repository or on his own website. Or there are laws now in place that every publication funded by the NIH has to be made public within 12 months after publication. So that would be green open access, and it’s pretty much free. Gold open access, as in open access journals, has different ways of funding. A relatively small proportion of open access journals, but for various historical contingencies the best known and probably most popular open acces journals, are charging authors. Other ways of funding are from scientific societies, through advertising, through donations and sponsorships, and many journals use more than one means of funding.
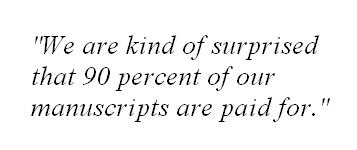
The small minority of journals that charge authors waive charges for authors that ate at the moment incapable of paying. All seven PLoS journals waive fees no questions asked. There’s actually a checkbox when you submit: “Well, I can’t pay.” The important part of that is, nobody on the editorial side knows which manuscript was paid for, reviewers, editors, nobody knows. Only the bookkeeper knows. Which means that there is no way to taint the editorial or the review process by knowing who paid and who didn’t. I think that’s very important to keep those things separate. You don’t want to be influenced subconsciously by knowing this was paid for or this was not, or even the assumption that unpaid ones are of lesser value, perhaps because they come from the developed world. That’s exactly what we are trying to counter. One of the visions of PLoS is encouraging research and publication in the developing world. We are kind of surprised that 90 percent of our manuscripts are paid for, and we have examples of publications being paid for two years later.
Great article. Just a small correction. Commenting on articles is also available on some Royal Society journals.
Redalyc
Under Open Access philosophy, Redalyc aims to contribute to the editorial scientific activity produced in and about Ibero-America making available for public consultation the contents of 550 scientific journals of different knowledge areas: http://redalyc.uaemex.mx