

W wie Wetter – oder Künstliche Intelligenz am Himmel

„Ich sage immer, dass ich statistische Modellentwicklung mache – dann fragt normalerweise keiner mehr nach.“ Was wirklich schade ist, obwohl es Sebastian Lerch in Gesellschaft natürlich so manchen unbehelligten Abend garantiert. Denn hinter den statistischen Modellen des Wissenschaftlers verbirgt sich ein Thema, das uns alle unmittelbar betrifft und das als das unverfänglichste Konversationsthema überhaupt gilt: das Wetter und wie man es möglichst genau vorhersagen kann.
Wir alle haben uns schon so manches Mal gefragt, ob wir besser einen Schirm mitnehmen sollten, das Fest ernsthaft draußen stattfindet oder ob wir die Winterkleidung wirklich schon einmotten können. Normalerweise genügt für die Beantwortung dieser Fragen ein Blick auf unsere Wetter-App, wobei inzwischen auch Vorhersagen von zwei Tagen im Voraus heute in etwa so präzise sind wie vor 10 Jahren die Vorhersage für den nächsten Tag.
Doch wie kommen diese eigentlich zustande? Zur Beantwortung dieser Frage muss man sich zunächst einmal genauer anschauen, welche Faktoren bei der Erstellung von Wettervorhersagen eine Rolle spielen.
Da wären zum einen die Luftmassen um uns herum, die ständig in Bewegung sind, gemeinhin als Wind bekannt. Und dann natürlich die Temperaturen, die z.B. im Zusammenspiel mit Niederschlägen und Wind innerhalb kürzester Zeit erheblich schwanken können, was wohl jeder bestätigen kann, der mitten im Sommer schon einmal zähneklappernd und viel zu dünn angezogen auf einem verregneten Gartenfest herumgestanden hat. Als dritter Faktor gesellt sich dann noch der Luftdruck hinzu, der bei manchen Menschen je nach Veranlagung Hochgefühle oder allgemeines Unwohlsein auslösen kann.
Informationen zu diesen drei Faktoren (und noch zu vielen weiteren) sammeln die Wetterstationen des Deutschen Wetterdienstes, die über das gesamte Bundesgebiet verteilt sind. Auf Grundlage der gemessenen Werte berechnen Wissenschaftler/-innen dann den Ist-Zustand der Atmosphäre – so nennt man die gasförmige Hülle, von der die Erde umgeben ist – und damit unser Wetter. Für die Erstellung von Vorhersagen werden im nächsten Schritt dann einzelne Faktoren dieser Gleichung, z.B. die Temperatur oder der Luftdruck, gezielt verändert und die möglichen Auswirkungen auf das Wetter berechnet. Bei der Modifikation dieser einzelnen Faktoren entstehen auf diese Weise um die fünfzig mögliche Szenarien, die dann miteinander verglichen werden. Unterscheiden sie sich nur wenig voneinander, bedeutet das, die Wetterlage ist in diesem Bereich relativ stabil und entsprechend gut vorhersagbar.
Es wird also ein ziemlicher Aufwand rund um unser Wetter betrieben. Warum ist es dann jedoch so, dass es immer wieder zu Fehlern bei der Vorhersage kommt? Dass mancherorts Temperaturen als stets zu mild oder Niederschlagsmengen als zu niedrig angegeben werden?
„Zum einen gibt es Unsicherheiten in den Anfangsbedingungen aufgrund fehlender Beobachtungen, zum Beispiel über Ozeanen oder in den oberen Schichten der Atmosphäre“, so Lerch. „Zum anderen gibt es Unsicherheiten bei den physikalischen Modellen. Viele Prozesse finden unterhalb der im Modell beschreibbaren Skalen statt und können daher nur approximiert werden.“
Doch dieser Blogbeitrag wäre nicht geschrieben worden, wenn es das schon gewesen wäre. Denn im Rahmen eines Forschungsprojekts im Sonderforschungsbereich 165 „Waves to Weather“ (W2W), der am Karlsruher Institut für Technologie (KIT) angesiedelt ist, begegneten sich im Juni 2016 Lerch und sein Kollege Stephan Rasp. Dieser interessierte sich seit einiger Zeit sehr für den Bereich „Künstliche Intelligenz“ und dort besonders für künstliche neuronale Netzwerke, was jedoch nicht unbedingt offizieller Teil seiner Forschung, sondern eher sein persönliches Steckenpferd war.
Er überzeugte den Statistiker Lerch – getreu dem Motto „Think beyond the limits“ – sein bereits bestehendes Projekt um diesen neuen Forschungsansatz zu erweitern, was in der ursprünglichen Planung eigentlich gar nicht vorgesehen war, sich im Nachhinein laut Lerch jedoch als ziemlich clevere Idee erwies:
„In klassischen statistischen Verfahren müssen die Zusammenhänge zwischen Eingabedaten und Zielgrößen explizit festgelegt werden. Moderne Methoden des maschinellen Lernens, wie z.B. neuronale Netze, erlauben ein flexibleres Lernen dieser komplexen Zusammenhänge, basierend auf den verfügbaren Daten.“
Doch was sind eigentlich neuronale Netze und was unterscheidet sie von den eingangs erwähnten herkömmlichen Modellen? Ihre wahrscheinlich wichtigste Eigenschaft ist die Flexibilität, d.h. sie lassen sich trainieren, indem man sie mit möglichst vielen Daten füttert, mit Hilfe derer sie sich weiter entwickeln können. Normalerweise wird an diesem Punkt stets die Analogie zum menschlichen Gehirn hergestellt – was bei dem Begriff „Neuron“ ja auch gar nicht so abwegig erscheint – aber dieser Vergleich stößt sehr schnell an seine Grenzen. Denn anders als das menschliche Gehirn, das basierend auf der Summe seiner bisher gemachten Erfahrungen Verbindungen zwischen den einzelnen Nervenzellen je nach Bedarf stärkt oder wieder abbaut und selbstständig bestimmte Schlüsse zieht, sind neuronale Netze bei jedem Entwicklungsschritt auf möglichst viele Informationen von außen angewiesen und immer nur so gut wie der Mensch, der sie programmiert. Bekommen sie diese Informationen jedoch in ausreichendem Maße, sind sie aufgrund der dem menschlichen Gehirn überlegenen Rechnerleistung fähig, komplexe Vorhersagen und Entscheidungen zu treffen.
Und tatsächlich geht dieses Kalkül auch beim Wetter auf: Die Genauigkeit der Vorhersagen verbesserte sich mit dem neuen Modell signifikant, wie auch die folgende Abbildung zeigt:
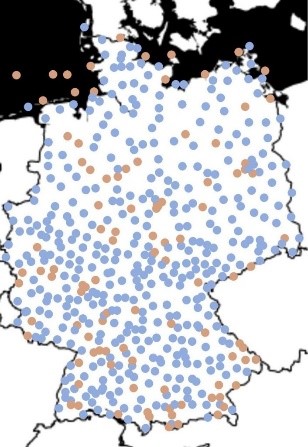
Um die 500 Wetterstationen gibt es in Deutschland: Die blauen Punkte zeigen die Stationen, an denen ein KI-Modell die besten Vorhersagen traf, orange diejenigen, an denen ein Standardverfahren genauer war (Quelle: Sebastian Lerch, KIT)
Und welche Rolle spielte die Arbeitsumgebung am HITS für das Projekt? Für Sebastian Lerch, der inzwischen am Institut für Stochastik des KIT arbeitet, waren es vor allem der unbürokratische Zugang zu Rechnerleistung – das tägliche Brot eines Datenwissenschaftlers – und die Nähe zu anderen Disziplinen, die methodisch ähnlich arbeiten. So kam ein Teil des Codes, der für die Erstellung der neuronalen Netzwerke benötigt wurde, von der Astroinformatik-Gruppe am HITS und deren Leiter Kai Polsterer – diese Überschneidungen bei anderen Forschungsbereichen ausfindig zu machen und für die eigenen Zwecke zu nutzen, gehört übrigens nach wie vor zum Kerngeschäft menschlicher neuronaler Netzwerke.
Genau wie der Smalltalk bei gesellschaftlichen Anlässen. Wenn dort also das nächste Mal das Stichwort „statistische Modellentwicklung“ fällt, fragen Sie ruhig mal nach – es könnte durchaus interessant sein.
Weitere Informationen zum Thema finden Sie unter:
https://www.kit.edu/kit/pi_2019_082_lokal-und-prazise-neuronale-netze-in-der-wettervorhersage.php
Dieser Versuch zeigt also die Überlegenheit von Deep Learning -Ansätzen über rein physikalische Verfahren bei der Wettervorhersage.
Das ist für mich aber erst der Anfang. Sollte sich auch das Schadenspotenzial von speziellen Wetterlagen durch künstliche neuronale Netze besser vorhersagen als durch die bisherigen physikalischen Modelle, dann sollten solche mit künstlichen neuronalen Netzen arbeitende Verfahren standardmässig eingesetzt werden. Die Frage ist also ob sich beispielsweise mit Deep Learning auch voraussagen lässt wie stark Flüsse in Folge von Niederschlägen anschwellen und wo mit Überschwemmungen zu rechnen ist. Wären die Resultate besser als mit konventionellen Verfahren, dann sollte man diese neuen Verfahren einsetzen.