

B like beyond the human limit or astronomical challenges in the era of AI

I started falling in love with astronomy when I was a child, it was around the year 1994. In those days, the comet Shoemaker-Levy 9 collided with the planet Jupiter. I was fascinated by the images on TV and decided then and there that I wanted to work in astronomy. Back then, astronomy was a quite different science field in comparison to what it is nowadays. Computers were already common, but they were way less powerful than the smartphones we use today. Digital detectors had been adopted as a new standard for telescopes only few years ago, substituting photographic plates. The best instrument available during that time was probably the Hubble Space Telescope, which was launched in 1990.
Since that time when exciting news on TV sparked my love for astronomy, 26 years have passed. We now have computers that seem to come from a sci-fi movie compared to those from 1994. We have the internet, that significantly facilitated the exchange of data, information, and ideas. This seems trivial, but you will read later why this is in fact a great achievement for astronomy. We have telescopes which can collect enormous amounts of data, more detailed than ever before. And we have something called artificial intelligence (AI), or machine learning, which turns out to be another game changer for today’s astronomy.
However, not everything changed so fast. In the picture below, dating from 1987, you can see the arrival of the Palomar Sky Survey data at the Capodimonte Astronomical Observatory in Naples, Italy, which had been shipped from California, USA. There was no internet and no digital data back then, so the photographic plates had to be physically mailed to allow astronomers to work on them.

About one year ago, I was in a similar situation of needing lots of data from an archive owned by the European Southern Observatory (ESO). ESO manages the biggest telescopes in the world and therefore has a huge archive where the data produced by the observations are being stored. One day, I was in my office and received a big box via postal mail. Inside the box I found a black plastic case. Unfortunately, it did not contain a shining light like in the movie “Pulp Fiction”, but a hard drive with the data I asked my colleagues to send over. Why still sending it per mail you ask? Because the dataset I requested was so huge, it was simply not possible to download it from the archive. In fact, I tried to download a similar big data set just months before and after lots of tricks, tips, trial and error, it took me overall two months to get the data. So, the second time around, I thought it would be faster to just send a hard drive from ESO in Garching to HITS in Heidelberg. Spoiler alert: It was.
All in all, it seems that things haven’t changed so much since the ‘80s.
Escaping the problem: one tool to rule them all
The reason I needed those data was the ESCAPE (European Science Cluster of Astronomy & Particle physics ESFRI research infrastructures) project, a big collaboration of more than 30 European institutes founded by the European Commission in 2019. The aim of the project is to create a European infrastructure that helps researchers to deal with the challenges from the data explosion in astronomy. As a scientist in the Astroinformatics (AIN) group at HITS, I am in charge, together with my group leader Kai Polsterer, of developing and applying new AI techniques on data from the ESO archives. This is done by following the so-called principle of knowledge discovery in databases (KDD): We do not use data anymore to validate a certain hypothesis, but instead we dig into big archives to find the unknown, inverting the traditional scientific method. It is like cleaning up your bookshelf and finding a cool book you did not know you owned, but you are glad to have found it.
Nowadays, this approach is necessary due to the ever-growing size of data archives, and AI is a big support in this case. Just to make it clear: AI is far from what we see in movies. It simply is a class of computer programs used to teach a machine to solve some specific kinds of tasks. Using AI, we can have the computer solve problems which are beyond human capabilities. AI is transforming the way in which astronomical research is conducted, because it allows us to explore huge amounts of data and to make new discoveries, in a way that was simply impossible 30 years ago.
To work properly, AI requires a lot of data from which it learns to solve a particular problem. Therefore, I prefer speaking about machine learning instead of AI, as we truly teach a machine and it better describes what we can practically do. The more data you have, the more accurate your results will typically be.
For the ESCAPE project, my task was to use machine learning on spectra from two different spectrographs managed by ESO. A spectrograph is the instrument, mounted on a telescope, which is used to obtain so-called spectra from celestial sources. Spectra are very important in astronomy. Even if it seems a bit complicated, a spectrum is nothing more than the energy emission from a certain source with respect to the wavelength. From their analysis, astronomers can understand several physical and chemical properties of the emitting source. ESO manages huge archives of spectra and we selected two of them as a first use case. Up to now, there are not many attempts in the astronomical community to analyze huge archives of spectra via machine learning and by using the KDD approach. This means that I was entering uncharted territory with lots of possibilities for interesting discoveries.
Unfortunately, as we have already seen, getting lots of data is still quite complicated. There are also different kinds of astronomical data: images, spectra, catalogs and so on. But in general, the more complex they are, the harder it is to find and download lots of them. So, the problems I had with getting the data are just the tip of the iceberg. If you look at astronomical archives and databases, you will soon understand that there are so many things that you simply cannot do, but that would be really useful for astronomers.
Let me give you some examples. You need a spectrum? This is easy, there are many platforms and different ways of searching what you need. You can also very quickly download it. Same if you need ten or a hundred spectra. But what if you need a million? Sorry, no way. There is no interface which allows you to download directly such a huge number of spectra. Usually this is due to the complex way in which spectra are collected and archived. Another example: Let us say that I would like to search all the images of a specific class of sources, quasars maybe, that are part of a certain data archive. This is already something more complicated, but with some limitations you can do it. But if my question would be: I want to upload an image of a quasar into the archive, please give me all other images that are similar? Well, impossible.
In other words, most of the platforms that astronomers currently use for accessing and inspecting data work via explicit search systems, based on predefined criteria or parameters. There is currently no other way for us to “freely” inspect the data sets.
However, science and scientific research, in many fields, is nowadays dominated by data. But the limitations in the way data access is carried out are a constant obstacle to many research projects. I want to change this situation and overcome these boundaries caused by explicit search parameters. I want to build a platform that allows to explore data in a completely new way, using an implicit similarity definition. To be specific, I want to get data from an archive based on how similar they look like and I want to teach the machine what similar means.
Machine learning is powerful and a necessity for today’s astronomy. Yet, with the current state-of-the-art methods, we cannot use it efficiently. How to solve this problem? Using machine learning, of course!
How AI makes the invisible visible: one tool to find them
To explore and interact with thousands or millions of complex data, the only feasible strategy is to simplify them. And that is where machine learning comes into play. There is a specific type of machine learning model called autoencoder. This architecture takes data as input, spectra in this case, and performs a so-called dimensionality reduction. The autoencoder basically converts the dimensions of the spectrum to a simple 2D space, that can then be visualized and inspected in a graph. In other words, every spectrum becomes a single point given by two coordinates and thousands of them can be easily visualized at a single glance, as points on a screen.
After creating this low dimensional representation, the autoencoder takes the coordinates back and uses them to build a plausible reconstruction of the spectra, as close as possible to the original ones. Then it compares original and reconstructed spectra and adjusts its internal parameters to minimize the difference between them. This operation is iterated until it reaches a satisfying result. If input and reconstruction are very close, we can be confident that the 2D representation will be trustable too and represents the input data well. Astronomers can use the new 2D data space to inspect and visualize even large datasets. In this way, they can see if there are similarities and relations between some points and/or regions. Up to this point this is nothing new. Astronomers have used autoencoders, and in general dimensionality reduction, extensively in the last years, as tools for data analysis and knowledge discovery.
Where is the novelty then? Up to now it has been only used to work locally on limited data sets, but never in a way that allows researchers to interact with an entire archive remotely. The possibility to visualize and analyze an entire archive is a lot more difficult but also offers many new insights. A global view gives a different perspective on the data, eventually allowing new discoveries which would be otherwise impossible. To help you put it into perspective: This basically means you can now review a book after you read the entire book, instead of just being able to read the first ten pages.
Therefore, I had two main goals. First, I wanted to apply the autoencoder which already helped astronomers to dig through data sets – but this time on an even larger scale. This way, astronomers would be able to visualize an entire archive compressed by an autoencoder (or a similar model). Second, I wanted to create an interface which, using the same autoencoder, allows the user to remotely interact with the data, select, import and export catalogs, access metadata, and much more. Like a modern Archimedes lever, it is meant to break the boundaries set by the current data access methods and sustain “the weight” of the astronomical data avalanche, giving freedom to explore data in a completely new and interactive way.
This is what brought me to create MEGAVIS.
MEGAVIS: one tool to bind them!
The word MEGAVIS is an acronym, which contains my main focuses, or requirements, when developing the tool. MEGAVIS is based on the autoencoder, which is its main engine. But there are many other dimensionality reduction models, and I did not want to focus only on this particular one. Therefore, I included the possibility for the user to switch between Multiple dimensionality reduction models, from which the letter M derives. MEGAVIS is an Explorative tool and built on a very General concept, as what I did with the spectra is meant just as a first use case. It is Agile, easily running on a common laptop. It allows to Visualize and Interact with the data and, finally, it Supports and is interconnected with the Virtual Observatory.
It is worth spending a few words on the latter element. The Virtual Observatory (VO) is a vision for which astronomical data, software, tools, and protocols should be interoperable, standardized, and accessible from the web, working all together as a whole. This vision is mainly managed by the International Virtual Observatory Alliance (IVOA), whose goal is to implement software, archives, and standards to eventually realize the VO. The advantage of the Virtual Observatory is that it is now possible to obtain astronomical data through the web, cross match them with other data taken from another telescope placed on the other side of the world, download any kind of software needed to analyze them and work with them all together, thanks to their interconnectivity. I therefore developed MEGAVIS to align to the VO principles to be used globally.
But what is MEGAVIS? It is a bridge between you and the data, based on machine learning. It uses the autoencoder I just mentioned above as the main engine and furnishes the user with all the instruments that are necessary to explore the data space. Using MEGAVIS makes it possible to see and inspect an entire data set in a single snapshot. The user can explore the dataset looking at the 2D representation, comparing it in real time to the original data and their reconstruction. It is possible to make data selections within the archive and create own catalogs by similarities which can then be exported and downloaded. Data and catalogs can also be imported to make comparisons with the archived ones. The connection with the VO grants access to additional data and information. By using MEGAVIS, I am now doing what I previously said: “cannot be done, but it would be so cool to have”. To come back to our book metaphor from before: You now have a platform which shows you every book, translation, and format available, from your favorite book shop across the street or even from another part of the world.
This way of approaching data access and visualization in astronomy is completely new. At the moment, MEGAVIS is still in a prototypal stage, so I am currently running it on my laptop with data stored locally. In the future, I plan to implement it as a web-service, to act as a direct bridge between the users and archives. This would solve the problems I had to deal with when trying to get my spectra, for example. In fact, astronomers will not need to download entire datasets locally anymore, instead it will be possible to inspect the entire archive online, perform analyses via machine learning, and just select and store what you are interested in. Also, it could open the way to new discoveries.
Exploring the data space interactively and searching data by similarities can bring forward new classifications, new trends and relationships, or interesting outliers (sources which deviate from the common behavior), otherwise impossible to spot. It also moves the needle from a single source-based astronomy to a multi-source approach.
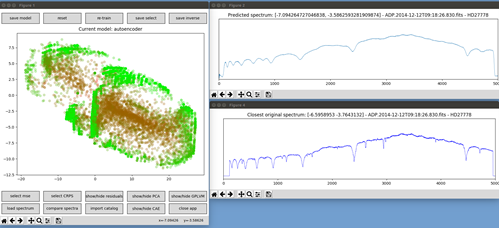
So far, the tests done with the two spectral datasets obtained from ESO are showing promising results. The plan is to extend the use of the tool beyond spectra, to different types of astronomical data and even to different fields of scientific research, for example biology, chemistry, and many more.
Creating MEGAVIS required a lot of work, it was challenging and sometimes hard, both from a scientific and a technical point of view. But in the end, this is what science is about and it was definitely worth it. My younger self who watched a comet falling on Jupiter on TV would have never believed that one day I would create a tool that lets me explore hundreds of thousands of stars and galaxies all together in only a few seconds – and that one day perhaps other astronomers all around the world will do the same. That is the wonder of science…