

Sometimes the Noise is Signals, Too
Early in his talk, computer scientist John Hopcroft noted a funny fact about clustering algorithms: they work better on synthetic data than real data. But this is more than an odd tidbit about software.
It’s an insight into the nature of our world.
When we invent our own synthetic data, we try to mimic real data by mixing true information with random distraction–combining “signal” with “noise.” But in real data, the divide isn’t so clear. What often looks like noise turns out to be the deep structure we haven’t grasped yet.
The noise is just signals you can’t yet hear.

Hopcroft’s insight: data doesn’t just have one structure. It has many. If I scanned notebooks from a hundred people, and made a database of all the individual letters, I could sort them lots of ways. Alphabetically. Capital/lowercase. Size. Darkness. Handwriting. Each of these is a different layer of structure.
And to understand data, you’ve got to reckon with all those layers.
Hopcroft’s approach? First, cluster your data according to its primary, surface-level structure. Then, wipe the slate—scramble this structure—and run your algorithm again, to find the hidden structure.
Uncover the signal you thought was noise.
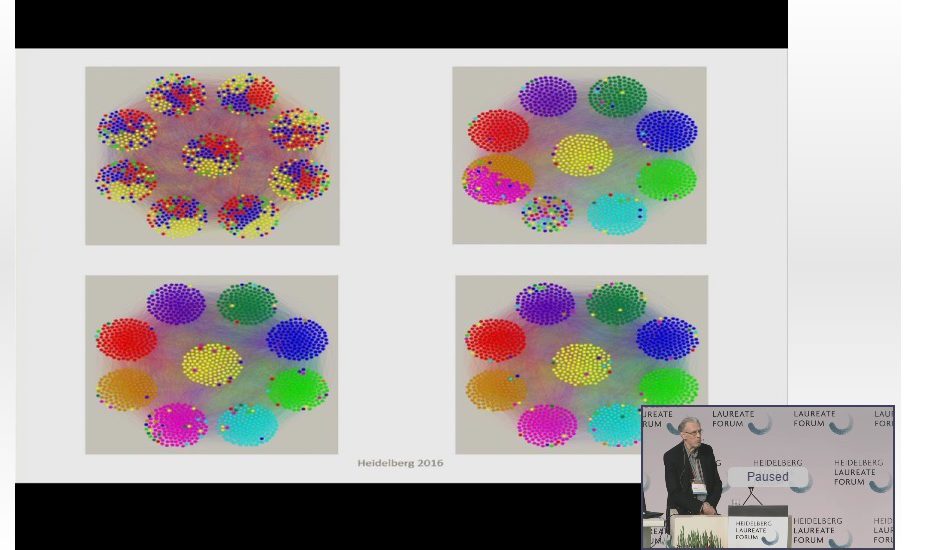
For example, Hopcroft and his colleagues ran their algorithm on Facebook data from Rice University. They had sparse information: no names, no profiles, just who was friends with whom—a skeleton network of connections. Based on this, their algorithm quickly sorted the students into nine clusters.
But was it merely random, algorithmic gibberish? After all, the computer knew nothing about the students, other than the friendship connections. Did the nine clusters have any actual meaning?
Sure. They corresponded precisely to the nine student dorms.

Then they weakened that structure, and ran the algorithm again. This time it produced only four clusters. The computer, of course, had no idea what these clusters meant—it only knew that friendships at Rice reflected a hidden four-group structure. Those groups?
Freshman, sophomore, junior, and senior.

The most tantalizing fact: there were two more layers of structure revealed by the algorithm, but it remains a mystery what they are. In the lives of those undergraduates, among everything we call “noise,” there are still hidden signals.
You can see the entire talk here.
I think what John Hopcroft said was that if you test an algorithm on real data and on synthetic data, it is going to perform better on synthetic data.
This does not mean you shouldn’t use real data for testing. Quite the opposite, it means that if you test on synthetic data only, you will overestimate your algorithm’s performance on real data—and this is what you are usually interested in.
Thanks for the correction; I tweaked the language. My takeaway was that he really was advocating for synthetic data as part of your algorithm-testing regime, rather than just remarking on the fact that synthetic data provides an easier task than real data, but I’ll revisit the video when I’ve got a chance this evening; it remains totally possible I’m getting this wrong.
Here’s the way I understood it: He simply pointed out that the researchers were puzzled by the fact that the algorithms performed better on synthetic data, and that perhaps was an inspiration for this line of research. He wasn’t trying to make a point about how one *should* test an algorithm, and indeed the rest of the talk has little to do with testing algorithms per se—as opposed to testing their ideas about hidden structures (on real data!).
As for the testing algorithms, I really don’t see any advantage to doing it on synthetic data, given that you have a representative piece of real data for which the algorithm is being designed. Of course, when designing abstract clustering algorithms (and not, say, clustering algorithms for 16S ribosomal RNA gene sequences), you often don’t have a luxury of knowing how the data looks like, so sometimes you have to rely on artificial data. But that’s just a necessity.
I went back and listened, and you’re totally right!
Thanks again for the corrections. Will try to update soon.