

How Data Science Can Help Us Understand (and Fight) Wildfires

The 2019-2020 Australian wildfires burned an estimated 186,000 square kilometers (72,000 square miles), ravaging the country and killing up to 1 billion animals. In California, the 2019 wildfire season ravaged over 1,000 square kilometers, often in or close to inhabited places. As climate change continues to mount, wildfires are expected to become a more and more serious problem – and data science can be an important ally in this fight.

Dr. Tom Beer watched in dismay as wildfires ravage through Australia. Beer read the reports and followed the news, dreading the effects of a devastating wildfire season. As anyone keeping an eye on the situation, Beer was devastated; but he wasn’t surprised.
In 1986, Beer was working at CSIRO, an Australian federal government agency responsible for scientific research. He was studying wildfires and was instructed to take a look at how the greenhouse effect was changing wildfires. The study, which was published in 1988, was almost prophetic.
The greenhouse effect, the study documented, would make wildfires more likely and more dangerous. More greenhouse gases meant higher temperatures, which in turn mean less moisture and more dry vegetation — perfect fuel for wildfires. Furthermore, climate change would fuel stronger winds, further exacerbating the spread of wildfires. Rising temperatures make worse wildfires, the paper concluded.
The results were, at best, ignored. Dr. Graeme Pearman, Beer’s supervisor (who had instructed him to look at this topic in the first place) went on to give over 500 presentations on climate change in future years, many of which addressed wildfires. Both Beer and Pearman, however, received criticism for this. The science was “shoddy”, some would say. Large wildfires did not happen for ten years, and climate change acceptance was painstakingly slow.
So their results went largely unnoticed. It took decades before science (and tragic events) vindicated them.
Modern wildfire models
As time passed, our understanding of wildfires changed and improved. Satellite data offered large-scale observation data, and increasing computation power allowed the development of increasingly complex models. Wildfire studies became more quantitative and more detailed – and computer models became an important tool.
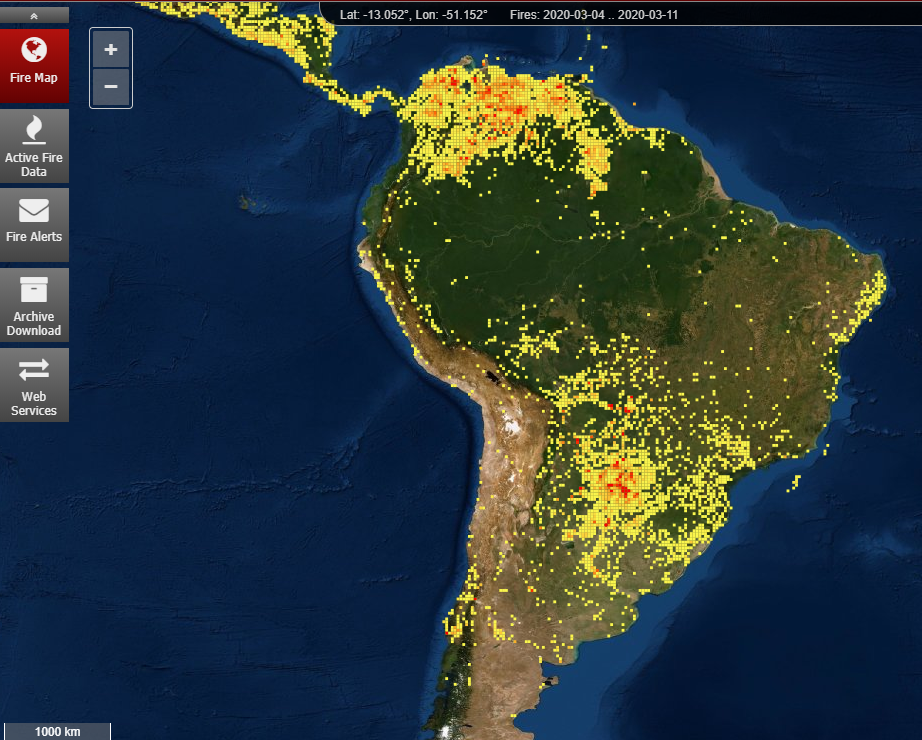
Wildfire models use numerical data to simulate the behavior of wildland fires. Models start out with simple inputs, such as the surface geometry and the type of fuel — in most cases, the vegetation which is expected to burn.
Intuitively, this is easy to understand. Dry wood burns more than wet wood, small twigs burn faster than larger ones, and so on. But numerically modeling these parameters is an entirely different problem.
Fire (and wildfire in particular) is a notoriously difficult thing to predict. This is why, in addition to well-established chemical and physical equations, wildfire models also tend to include semi-empirical fire spread equations, which are usually published by the forestry services of several countries. This makes wildfire modeling particularly interesting and particularly challenging.
In addition, models must also consider fire as an active parameter that could actively change its surroundings: a strong fire can produce storms and strong winds, which further affect it, creating a complex feedback loop.
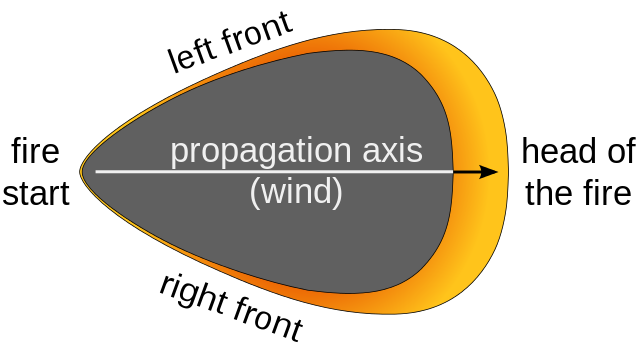
Models are also influenced by weather and moisture, and must, therefore, be coupled with atmospheric simulations — adding another layer of complexity into the mix. It is not surprising then that modern models are already incorporating massive amounts of data and machine learning; some models require supercomputers to be able to run.
Ultimately, a risk index is developed as an output, and several predictions are made about the emergence and evolution of wildfire.
The connection to climate change is, in one regard, pretty obvious. Many areas on Earth are already seeing average temperatures 1°C above preindustrial levels, excess drought, and an increasing frequency of extreme weather events. In places such as Australia and California, drought has become a key parameter affecting wildfires, and conditions created by a heating climate are exacerbating wildfire risk.
In this sense, the devastating wildfires in Australia are not surprising. They are part of a larger trend which we will see in many parts of the world (although in truth, they were worse than anything models had predicted) — a trend which was predicted by numerous models.
But computer models can do more than just help us understand wildfires — they can help us tackle them.
Prescribed fires: a story of numbers and people
The ultimate goal of computer models isn’t only to gain a better understanding of the process, but also to direct effective policy. For wildfires, in particular, this is essential in the case of a controversial practice: controlled fires.
Wildfires, it should be said, are a natural process. Natural wildfires eliminate excess fuel (such as fallen wood and litter) and keep forests widely spaced. Under normal conditions, natural wildfires can help replenish forests.
But as it so often happens, the natural balance has been heavily tipped by human activity.
In addition to climate warming, human activity has affected forests in more direct ways, through forest management practices. Humans don’t really like wildfires — they threaten our safety and infrastructure — so most preventive measures focus on reducing wildfires as much as possible.
This phenomenon was traditionally counterbalanced through controlled fires. A growing body of evidence (much of it based on models) suggests that carefully prescribed fires can have long-lasting beneficial effects. However, controlled fires can be risky, and they tend to attract negative media coverage, so most policymakers have shifted away from this practice. Disasters such as the one at the Bandelier National Monument in New Mexico in 2000 (when a prescribed fire went out of control and forced the displacement of 400 people) definitely don’t help the case.
This is where wildfire models come in handy. Behavior modeling can predict how the fire will develop and where it will go, finding under what conditions prescribed fires can be safely carried out. Modeling can also estimate ecological and hydrological effects, along with other effects (such as the amount of smoke produced).
At a local and regional scale, data science can help forest planners safely deploy prescribed fires, reducing the risk of catastrophic damage caused by excess fuel in the forest. We can learn to map and classify wildfires and build algorithms to make predictions about fire likelihood.
On a global scale, we can better understand how climate change is increasing the risk of wildfires. Beer and Pearson correctly predicted that climate change will increase the risk of wildfire more than 30 years ago; more refined models can help us understand that risk even better.
The threat of wildfires is very serious, as we’ve seen in recent years – and is likely to become even more prevalent as global temperatures continue to increase. We’d be wise to learn from Australia’s lessons and work to limit future tragedies as much as possible.