

Clever Codes
BLOG: Heidelberg Laureate Forum

We are all surrounded by codes. Computers process huge amounts of information in a multitude of formats – written text, numbers, images and audio/video – and a variety of coding methods are used to make storing and transmitting information more efficient and more reliable.d
To be clear, this doesn’t mean coding as in writing software – I’m talking about encoding: converting data into a different format, using a set of predetermined mappings. A simple example would be converting the alphabet to numbers, using A=1, B=2 etc. Codes in general are simply a way to convert information into a different form, that helps us store and transmit it, and can range from very simple to quite complex.
Code Re(a)d
For example, a code your computer is literally using right now is ASCII – the American Standard Code for Information Interchange. This was originally developed in America in the 1960s, as a way to standardise the process of converting letters (used to display text on the then-relatively-new computer screens) into numbers the computer could process and store.
You’d imagine there’d be endless possible ways to decide on the ordering – do we start with A=1, or A=0, and where do we assign punctuation marks like space, full stop and comma – and what about capital and lower-case letters? Since so many computer systems were being developed, it made sense to have a standard everyone could use.
The original standard involved a simple character set with a single upper-case alphabet, a small selection of punctuation marks and a set of control characters (things like ‘new line’, ‘tab’ and indicators for the start and end of headings and blocks of text, used for different types of printing machines and displays). Since then, it’s been gradually expanded to incorporate more symbols and character sets for different languages and has now become part of the larger Unicode system (which also includes pictorial symbols like emoji).
This larger system is still built on the same basic principle – each character you might type has a number allocated to it. There are also clever features built into the choice of numbering – for example, take a look at this section of a table of ASCII codes for just the visible, printable characters.
| 32 | space | 64 | @ | 96 | ` |
| 33 | ! | 65 | A | 97 | a |
| 34 | “ | 66 | B | 98 | b |
| 35 | # | 67 | C | 99 | c |
| 36 | % | 68 | D | 100 | d |
| 37 | & | 69 | E | 101 | e |
The ASCII for capital A corresponds to the number 65, and the ASCII for lower-case a is 97. This might seem like a fairly arbitrary choice until you think about the fact that these numbers will be stored and processed using binary. If you write the numbers in binary, you might see an interesting pattern:
| 0100000 | space | 1000000 | @ | 1100000 | ` |
| 0100001 | ! | 1000001 | A | 1100001 | a |
| 0100010 | “ | 1000010 | B | 1100010 | b |
| 0100011 | # | 1000011 | C | 1100011 | c |
| 0100100 | % | 1000100 | D | 1100100 | d |
| 0100101 | & | 1000101 | E | 1100101 | e |
Since binary is base 2, each column corresponds to a particular power of 2 – 1, 2, 4, 8, 16, 32, 64 and so on. The 64 column is the left-most column in these 7-digit binary strings, and since 65 is one more than 64, its binary representation is made up of just a 64 and a 1 (1000001).
As you look down the column, you’ll see the numbers all start the same way – the capital letters with 100, and the lower-case with 110 – and the remaining five binary digits just tell you how far through the alphabet you are, using the classic A=1, B=2 system. This means to write a letter in binary, I can simply convert it to a number, e.g. (M=12), write that in binary (12 -> 01100), then write 100 at the front for capital M, and 110 for lower-case.
When designing a code like this, choosing to include patterns like this don’t just make for satisfying realisations 50 years later – they also mean that the code is easier to use. There are plenty of other ways codes can be made more efficient and useful through clever design.

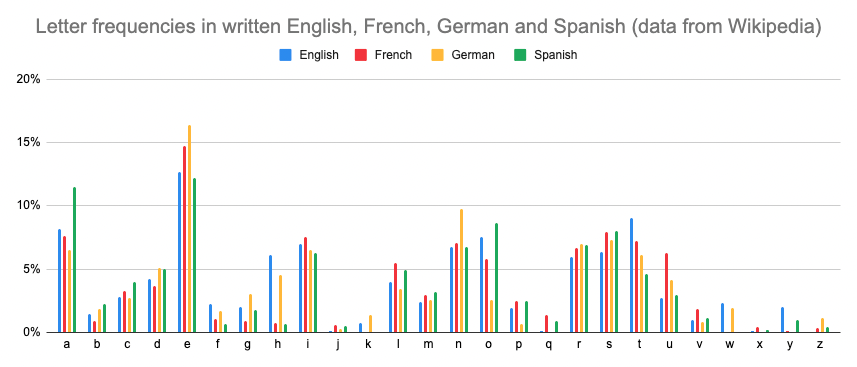
One simple example is how Morse code uses particular strings of dots and dashes to represent letters. Unlike the ASCII codes, Morse Code doesn’t use the same number of symbols in every codeword – some are shorter, like E and T, and others use longer strings.
The letters with one-symbol codewords, E and T, both share the property that they occur relatively frequently in written language – as do A, I, N and (to some extent) M, which use the two-symbol strings. Other commonly used letters, like S and O, use the more memorable three-symbol codewords, dot-dot-dot and dash-dash-dash.
When developing this code, the engineer Alfred Vail (who expanded it from Morse’s original numbers-only version to also transmit letters) could have just written the possible combinations of dots and dashes in any order and assigned them to the letters. Instead, choosing to assign shorter strings to common characters means that communicating in Morse code is more efficient – the average number of dots and dashes needed to transmit a message is lower. It’s also easier for a human operator to type, since the more commonly used letters are easier to remember.
Can we (pre)fix it?
Another clever design trick that can be used when your code has different length codewords is to make it a prefix code. A prefix code has the property that none of the code strings occur at the start of any of the others. For example, using only the codewords 11, 12, 211 and 212 would work as a prefix code, but using 12, 21, 221 and 122 wouldn’t – if you see a ‘12’ at the start of a codeword you don’t know which of ‘12’ or ‘122’ is being typed.
One main benefit of this is that you don’t need to specify where the breaks between codewords are – we say the code is uniquely decodable, since there’s only one way to interpret a given string of digits as a set of separate codewords. Try this example:
| Code: E = 111 T = 010 A = 000 R = 1101 H = 1010 | Decode the message: 101011100011010101101000010111 |
This means we can get the benefit of variable-length strings, and use shorter ones for more commonly communicated symbols, without needing to use any extra information to indicate how to parse the message. These kinds of tricks mean that we can both communicate messages more efficiently, and store data in an encoded form using less space.
Data compression – a hugely important feature of computer system design – uses tricks like this all the time to store data using fewer bytes of space on your hard drive or memory. The ideal is lossless data compression – storing something more compactly, but without losing any of the information, so that after decompressing it again you get back all the information that was there before. Techniques for lossy data compression are easier to design – storing photos with lower resolution, or audio files that lose sound quality – but there are ways to compress data that don’t lose a single bit.
Huffman coding uses a clever system – it analyses the data being stored prior to encoding, and determines the frequency of each symbol in the data. Since the information stored isn’t necessarily going to be written language, and might be computer code, image or audio information, this might not match the frequencies of letters in language we saw earlier – but for a given file, the frequencies can be tallied.
This is then used to design a prefix code, using shorter strings for more common symbols, and inventor David Huffman came up with an efficient algorithm to sort and assign the codes to pack data into a smaller space. While there is then also a requirement to communicate the particular coding used, this will only take up some of the space saved by reducing the length of the message, and it’s still more efficient than a fixed-length code like ASCII.
How low can you go?
How much more efficient such codes can get depends entirely on the contents of the data. For example, if every symbol occurs equally frequently in the message, it’s not possible to save as much space as if you have a more varied distribution. If you have one symbol that dominates, and occurs more than half the time, Huffman coding is inefficient. Prefix codes generally are also inefficient on small alphabets.
These issues are related to ideas that mathematician Claude Shannon studied as part of his groundbreaking Mathematical Theory of Communication. He posited that information, and the way it’s transmitted, doesn’t have to bear any relation to the actual information you’re sending.

For example, in a system where the only two things you can transmit are the word ‘yes’ and the entire text of the bible, you still only send one bit of information – even though the bible is a long chunk of text – since it’s only one of two options. A clever realisation of Shannon’s was how patterns in data – like letters of high frequency in written language – can be exploited to reduce how much actual information is needed to transmit something.
For example, Shannon conducted experiments on how easily people are able to predict what the next letter or word will be in a sentence. If someone is presented with the initial words ‘Once upon a’, there aren’t many fairy-tale fans who wouldn’t be able to guess that the next word is likely to be ‘time’. Similarly, faced with a word starting with a Q, there’s a good chance the next letter is U.
This means that ‘time’ and ‘U’ somehow convey less information to the person receiving the message – if they were missing, the meaning of the message would be unaffected. However, if I received the message ‘Meet me at the’ with the next word missing, there’d be a lot more information carried by that missing word, since I have less chance of predicting what it’s going to be. Shannon called this concept information density – not all letters and words are created equal, and some are more important than others.
While these ideas may seem simple, lossless data compression and coding underlies huge amounts of modern technology, and sometimes it’s nice to take a moment to appreciate just how clever these structures and ideas are, and how they make things work so effortlessly.
Quote: We are all surrounded by codes.
Indeed. Not only surrounded, but embedded in codes we are. For there is also the genetic code, without which we would neither exist nor persist. The genetic code (called a code by Erwin Schrödinger in his book “What is Life”) is the opposite of a minimal code. It is a degenerate, a redundant, an error-tolerant code that maps 64 possible codes to 20 amino acids and 3 stop codons.
Life does not use data compression because life prefers life to death by a single error.
Aus diesseitiger Sicht ist die Lebensdatenhaltung, DNA und so, kein “Code”, sondern “Programm” (kein Programm-Code also [1]), ein Austausch zwischen erkennenden Subjekten ist nicht angestrebt, sondern es wird “Programm”, eine Anweisung an die Natur liegt sozusagen vor, (nach Ausführung) repliziert, weitergegeben.
[1]
Wer anders meint, muss “nur” den Sinn extrahieren, sprachlich erklären.
Dann revidiert Dr. Webbaer seine Einschätzung bedarfsweise.
@Dr.Webbaer: DNA-Nukleotide entsprechen Aminosäuren und es gibt eine Abbildung, die jedem DNA-Nukleotid eine Aminosäure oder ein Stopp-Codon zuordnet. Genau dies nennt man einen Code. Hinter einem Code steckt also eine diskrete Abbildung.
Daten müssen nicht Code meinen, bei unverstandenen Daten – die Lebens-Datenhaltung ist unverstanden und hat wohl auch so zu bleiben, sie ist insofern kein Code, sondern “nur” Programm (Code kann auch Programm meinen, korrekt!) – vergleiche :
-> https://www.etymonline.com/word/code#etymonline_v_15772
Code entsteht dann, wenn Vorschriften, es wird auch von Kodierungsvorschriften geredet, zwischen Sender und Empfänger (vorab) ausgetauscht sind.
Wenn gewusst, was gemeint ist. (Zumindest, harhar, vom Gerät.)
Ansonsten sind’s “nur” Daten, in diesem Fall muss von einem (unverstandenen) Programm ausgegangen werden.
Vgl. mit :
-> https://de.wikipedia.org/wiki/Diskret
@Dr.Webbaer: DNA-Code ist kein Programmcode im klassischen Sinn, denn die Aktionen, die zu einem Programm gehören werden von den Proteinen, den Enzymen ausgeführt. So gesehen ist DNA-Code nur eine Form der Speicherung von Lebens-Programmen. Die eigentlichen aktiven Lebensprogramme sind die Proteine und Enzyme für die die DNA die Vorlage ist.
Es liegt eine Datenhaltung, die Lebensdatenhaltung terrestrischer Art vor.
Vgl. auch mit diesem Jokus :
-> https://www1.wdr.de/wissen/technik/dna-speicher-100.html
Derartige Datenhaltung scheint dann, neben der Epigenetik, Programm zu sein, wenn auch von den von Ihnen genannten Einheiten umgesetzt und womöglich anderweitig per se unverständlich.
A complete different method to safe space is shorthand.
You have to pronounce it loudly to understand its sense.
For computers its impossible to translate a message without errors.
“All letters and words are created equal(ly)”, abär sie tragen nicht gleich viel Information.
Biologisch betrachtbar hat sich dennoch Redundanz durchgesetzt, was einige verblüfft, es ging da wohl auch um Ausfalltoleranz.
Und um Nuancen, die gegenständliche Schrift, Hierogylphen und so, war “dichter”.
Das Web mag insofern Pakete, alles vely schlau indeed.
Letztlich geht es darum ein Bild, das sich beim Sender sozusagen aufgebaut hat, zum Empfänger zu transportieren, in der manchmal auch nur vagen Hoffnung, dass sich dort ein ähnliches wie das kodierte Bild aufbaut, wenn auf Empfängerseite passend dekodiert oder abstrahiert wird.
Mit freundlichen Grüßen
Dr. Webbaer
Bonuskommentar hierzu :
Die Humansprache funktioniert so, dass sich sozusagen angegrunzt wird, und vom Empfänger des sozusagen Nachricht aussendenden, grunzenden eben sendenden Subjekts entgegen genommen und extrahiert wird, Rauschen (bestmöglich) umgehend und sich, aus dem sozusagen schrecklichen “Gegrunze” des anderen etwas gedacht wird, auf Empfängerseite.
“Shannon-Weaver” sozusagen.
Dies liegt daran, dass die hier gemeinten Hominide nicht sozusagen zur Daten- und idF Informationsübertragung geboren sind.
Evolutionär sozusagen nicht, denn der Verdacht kann nicht ausgeräumt werden, dass sich wie hier gemeinte Hominide sozusagen begrunzen, mit viel “Rauschen”, gar den Schriftverkehr meinend.
—
Ein Gag besteht hier auch darin, dass der hier gemeinte Hominide die Sprache nur deshalb erfunden hat, um dem “Affen” auf dem anderen Baum mitzuteilen, dass er ihn nicht gut findet.
Weitere Gags sind denkbar, so soll bspw. und aus diesseitiger Sicht nie gedacht werden, dass etwas, hier ist auch die naturwissenschaftliche Theoretisierung gemeint, stimmt, richtig ist, wahr ist (außerhalb der Tautologie).
Auch bspw. die Gravitatationstheorie ist nicht richtig (“weil sonst alles wegfliegen würde”), sondern Beschaffenheit des Denkens.
—
In puncto Textverständnis rät Dr. Webbaer an literalistisch und intentionalistisch zu folgen.
Bestmöglich.
Miz freundlichen Grüßen
Dr. Webbaer
PS :
-> https://en.wikipedia.org/wiki/Claude_Shannon
-> https://en.wikipedia.org/wiki/Warren_Weaver
Dr. W.
Die Begriffe Programm, Code werden in der Umgangssprache ziemlich unterschiedlich gebraucht. Da haben wir das Fernsehprogramm, die Programmzeitschrift, das Computerprogramm immer mit anderer Bedeutung.
Bei Code ist es ähnlich, in der Kryptografie unterscheidet man zwischen „kodieren“ und „chiffrieren“. Ein code- Buch vertauscht ganze Worte gegen andere. Aus „Treffpunkt“ wird z.B. „Bach“usw. Werden nur die Buchstaben gegen andere vertauscht, dann sprechen wir von chiffrieren.
Das Wort code wird auch für eine bestimmte Anordnung von Zeichen gebraucht.
Ein reiner Binärcode ist anders strukturiert als ein ASCII – Code.
In diesem Sinne ist der Morsecode sogar doppelt codiert. Einmal als Punkt- und Strichfolge dann muss man noch wissen, in welcher Sprache gemorst wird, weil ja eine Sprache eine Codierung von Lauten zu Wörtern ist.
Was ist jetzt die DNA ? Was wurde da kodiert und von wem? Wer liest den Code und wer führt ihn aus.?
Nur mal als Anregung aus jenseitiger Sicht.
Today is pentecoste
After this I will pour out my Spirit on all humanity; then your sons and your daughters will prophesy, your old men will have dreams, and your young men will see visions.