

Menschen und Maschinen und das Wunder ihrer Sprache

Die maschinelle Verarbeitung natürlicher Sprache (Natural Language Processing – NLP – weiter auch: maschinelles Sprechen) ist das Flaggschiff der “Künstliche Intelligenz”-Forschung. Schon ihr geistiger Vater Alan Turing machte 1950 mit seinem Turing-Test die Sprache zum Hauptmerkmal der Intelligenz: Eine Maschine ist dem Menschen im Denken nur dann ebenbürtig, wenn ein menschlicher Prüfer die Maschine bei einem schriftlich geführten Gespräch von einem Menschen nicht unterscheiden kann.

Doch jahrzehntelang nachdem Turing seinen Test entwickelt hatte, dümpelte die Mensch-Maschinen-Kommunikation vor sich hin. Bis eine alt-neue Art Texte zu kodieren ihnen auch etwas von ihrer Bedeutung entlockte und zusammen mit künstlichen neuronalen Netzen mit „Gedächtnis“ eine Revolution im maschinellen Sprechen verursachte. Sehen wir uns aber zuerst an, wie unser Gehirn Sprache erzeugt und verarbeitet. Wie ist natürliche Sprache entstanden?
Schon der Entdecker der Evolutionstheorie Charles Darwin meinte, die Sprache habe sich aus lautlichen Nachahmungen von Umweltgeräuschen entwickelt. Wenn ein Urmensch plötzlich das Brummen eines Bären vernahm, gab er das Brummen sofort weiter. Die Urmenschen, die sich drüber lustig gemacht und gelacht haben, wurden gefressen. Nur diejenigen überlebten, die schnell davonliefen. Das heißt dann natürliche Auslese und spiegelt auch den Spruch meiner Mutter wieder: „So lange die Sprache lebt, ist der Mensch nicht tot.“

Heute wissen wir, Vögel und Primaten kommunizieren viel differenzierter miteinander, als man gedacht hat. Diese Tiere verwenden sogar zusammengesetzte Alarmrufe. Manche Affen können ihre Artgenossen mit unterschiedlichen Rufen vor Feinden am Himmel oder solchen am Boden warnen und ihre Alarmrufe nach Bedarf mit einer zusätzlichen Lautendung versehen. Damit bringen sie zum Ausdruck, dass zwar Gefahr drohe, diese aber nicht so groß sei und man weiter chillen könne. Das sind schon kleine Sätze, oder? Manche Menschen sprechen auch nicht viel komplizierter.
Hat Sprache sich also nur durch die Nachahmung der Umweltgeräusche entwickelt? Manche Forscher denken, Sprache sei aus Gebärden entstanden. Gehörlose nutzen bei ihrer Gestik-Kommunikation die gleichen Gehirnteile, die auch der Verarbeitung der normalen Sprache dienen. Und Greifbewegungen erleichtern das Verständnis beim Lesen.
Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.
Wohl hat bei der Entstehung und Evolution der Sprache beides eine Rolle gespielt: Lautliche Nachahmungen der Umweltgeräusche und Gestik und Greifbewegungen: und damit zusammengehörend alles, was wir mit unseren Sinnen wahrnehmen und mit unserem Gehirn verarbeiten. Das setzten wir mit Hilfe unseres Körpers in Handlungen und Bewegung um und entwickelten so weiter unser Gehirn, unser Denken und unsere Sprache.
Dass unsere Motorik und diese „Verkörperung“ des Denkens und der Sprache – des „Embodimets“ auch bei der Entwicklung der künstlichen Intelligenz wesentlich ist, sehen heute immer mehr KI- und Robotikforscher.
Wie kommt Sprache aber im Gehirn zustande? Dank den 86 Milliarden Neuronen im menschlichen Gehirn und etwa 100 Billionen Verbindungen dazwischen können im Gehirn Milliarden kleine neuronale Netzwerke entstehen. Je nach Aufgabe feuern Neurone (Gehirnzellen) in diesen Neuronenverbänden zusammen. So wird auch die Sprache nicht nur in den zwei Sprachzentren in der linken Gehirnhälfte (dem Broca- und Wernicke-Areal) verarbeitet und produziert, wie man früher dachte, sondern im ganzen Gehirn, also auch in der rechten Gehirnhälfte.
Dadurch kann der Mensch seine Sprache sehr pragmatisch gestalten, das heißt dem momentanen Gesprächspartner anpassen: schon ein achtjähriger „Gangsta“ in Neuperlach in München spricht ganz anders zu seinem Lehrer als zu einem anderen „Gangsta“, wenn er ihn disst: „Isch mach disch Döner, Alta!“
Der Mensch nutzt also bei jedem Gespräch, beim Zuhören, beim Schreiben, sein ganzes Wissen, das er im Laufe des Lebens angesammelt hat. Somit ist unsere Sprache sehr kontextabhängig und für jeden „uneingeweihten“ Zuhörer mehrdeutig, etwas also, was Computerprogramme und Maschinen völlig überfordert. Mit Hilfe seines gesamten Wissens versucht unser Gehirn ständig vorauszuahnen, was unser Gesprächspartner sagen würde, damit das Gespräch flüssig bleibt. Haben Maschinen angesichts der Komplexität unseres Gehirns überhaupt eine Chance, die natürliche Sprache zu meistern?
Diese Programme sollen Texte zusammenfassen, übersetzen oder in großen Textsammlungen wichtige Zusammenhänge aufdecken – in Nachrichten, in Posts in den sozialen Netzwerken wie in Tweets bei Twitter, in Blogs, in großen Bibliotheken und Datenbanken wie Wikipedia u.a. Auch Spracherkennung und Stimmungsanalyse gehören zum “maschinellen Sprechen”. Genauso wie die liebsten Gesprächspartner der einsamen Herzen mit den Smartphones: Alexa (Amazon), Cortana (Microsoft), Siri (Apple) und Google Assistant. Der Google-Übersetzer ist ein Paradebeispiel für ein maschinelles Sprachprogramm, das Google heute „Google Neural Machine Translation“ (GNMT) nennt. Diese Bezeichnung zeigt auch, von welchen Maschinen die maschinelle Verarbeitung der natürlichen Sprache heute gemeistert wird.
Doch fangen wir auch beim maschinellen Sprechen am Anfang an: Noch Jahre nach Turing taten Maschinen sich mit der Sprache schwer. In klassischen Wortverarbeitungs-Programmen wurden Texte oft „atomisiert“ und einzelne Wörter willkürlich als Zahlen kodiert, ohne ihre Verwandtschaft untereinander zu berücksichtigen: Das Wort „Bier“ zum Beispiel trug eine ganz andere und willkürliche Zahl als das Wort „Schweinshaxn“, obwohl die beiden Nahrungsmittel sind und zumindest in Bayern ganz nah zusammengehören.
So arbeiten immer noch naive Bayes-Klassifikatoren als SPAM-Filter: Die Programme ermitteln nur, wie oft einzelne Begriffe wie z. B. „diskret“, „Viagra“ und „Potenz“ in SPAM- und HAM-eMails vorkommen. Ein HAM ist eine normale eMail, kein SPAM also. Mit diesen Wahrscheinlichkeiten ausgerüstet suchen die Programme in einer neuen eMail nach diesen Begriffen: Je häufiger sie gefunden werden, umso wahrscheinlicher handelt es sich um einen SPAM.
„Bayes“ bezieht sich auf den Satz von Bayes, mit dem man bedingte Wahrscheinlichkeiten berechnen kann: Wie wahrscheinlich ist eine eMail ein SPAM, wenn darin nicht nur „diskret“ allein, sondern noch dazu „diskret“ und „Viagra“ und „Potenz“ vorkommen? Naiv heißen die Programme, weil sie den Text naiv behandeln, ohne zu beachten, wie die einzelnen Wörter darin zusammenhängen, das heißt, welche Sätze sie bilden. Trotzdem filtern sie ganz gut SPAMs heraus und zeigen somit: Schon solche primitiven Sprachverarbeitungs-Programme können gut ihre Aufgaben erfüllen.
Dem Sprachwunder der Künstlichen Intelligenz (KI) ELIZA von Joseph Weizenbaum von 1966 lag ein Thesaurus zugrunde – ein Wörterbuch der sinn- und sachverwandten Wörter. ELIZA als Psychotherapeutin wurde damals recht berühmt. Doch obwohl das Chatbot dank dem Thesaurus rudimentär auch die Verwandtschaft der Wörter berücksichtigte, hatte ELIZA keine Chance, den Turing-Test zu bestehen. Wenn ELIZA im Gespräch nicht weiterwusste, sagte es allgemeine Floskel oder wiederholte sich.
Online kann man mit ELIZA auch heute sprechen. Auf dem Bild sehen Sie mein gestriges Gespräch mit ELIZA. Was sage ich und was sagt ELIZA? 😊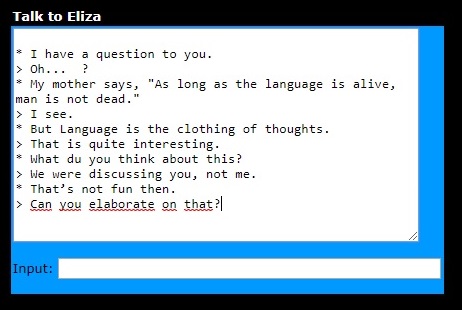
Genauso habe ich mich jahrelang auch über den Google-Übersetzer lustig gemacht, indem ich ihn schöne deutsche Sätze ins Englische und gleich zurück ins Deutsche übersetzen ließ. Den so hin und zurück übersetzten Text verglich ich dann mit dem Original und postete den Quatsch bei Facebook.
Der Satz, „Wer schwankt, hat viele Wege.“, wurde so zu: „Wer winkt, hat viel vom Weg.“
Schon am berühmten Schachtelsatz von Lessing scheiterte Google jämmerlich, obwohl der Satz recht eindeutig ist, vor allem, wenn man in ihm die Kommas richtig setzt: „Derjenige, der denjenigen, der den Pfahl, der an der Brücke, die an der Straße, die nach Mainz führt, liegt, stand, umgeworfen hat, anzeigt, bekommt eine Belohnung.“ Lessings Satz hat den Weg durch den Google-Übersetzer nicht einmal hin ins Englische geschafft. Vom Weg zurück ins Deutsche gar nicht zu reden.
Wir müssen noch mehrdeutiger und in Schachtelsätzen sprechen, dachte ich. Dann haben die Maschinen keine Chance gegen uns, was Sprache angeht. Früher war ja jeder Deutscher ein Dichter oder Denker, weil er Bücher voller Schachtelsätze hatte lesen müssen. Doch bald sollte ich von der neuen Wirklichkeit des NLP eingeholt und für meinen Hohn bestraft werden. Die heutigen Maschinen können lernen, und sie lernen immer schneller: Künstliche neuronale Netze.
Vor ein paar Wochen sollte ich ein Stück zum Faust-Jahr für die Deutsche Akademie der Technikwissenschaften schreiben: „Faust und künstliche Intelligenz“ und damit bei „acatech am Dienstag“ auftreten. Nichts leichter als das, dachte ich. Ich konnte doch am Nachmittag vor der Veranstaltung ein paar Sätze aus „Faust“ mit dem Google-Übersetzer ins Englische und zurück ins Deutsche übersetzen. Sicher würde so genug Lustiges herauskommen.
Doch jeden Satz von Goethe, mit dem ich den Übersetzer von Google am Nachmittag vor der Veranstaltung fütterte, kam nach dem oben beschriebenen Rundweg nahezu unbeschädigt wieder im Deutschen an. Was jetzt? Zehn Sätze übersetzte ich so, zwanzig Sätze … In zwei Stunden sollte die Veranstaltung stattfinden und ich hatte noch keinen Stoff dafür! Statt über Google-Übersetzer zu spotten, musste ich ihn immer mehr bewundern. Hat Google am Ende die ganze „Faust“-Tragödie samt ihrer perfekten Übersetzung ins Englische seinem Übersetzer einverleibt?
Ich ließ „Faust“ beiseite und suchte nach Sätzen von Goethe voller mehrdeutiger Metapher. Es mussten sich doch ein paar symbolische Worte von Goethe finden lassen, an denen Google-Übersetzer scheitern würde. Und endlich kamen diese Sätze:
„Wer das erste Knopfloch verfehlt, kommt mit dem Zuknöpfen nicht zu Rande.“, wurde nach der Hin-und-zurück-Übersetzung zu: „Wer das erste Knopfloch vermisst, kommt mit dem Knopf zur Seite.“ Jawohl! Goethes Knopflöcher haben mich gerettet!
Und Goethes Satz, „Die Welt urteilt nach dem Scheine.“, kam viel aktueller aus der Übersetzungsmaschine heraus: „Die Welt beurteilt die Rechnungen.“ Somit war Goethe dank der künstlichen Intelligenz des Google-Übersetzers im real existierenden Kapitalismus angelangt. Nur den oben zitierten Schachtelsatz von Lessing bekommt Googles-Übersetzer immer noch nicht richtig hin. Sicher nur eine Frage der Zeit.
Wieso ist künstliche Intelligenz von Google so gut im Übersetzen geworden? Wie konnte Google so schnell das Genie der maschinellen Verarbeitung der natürlichen Sprache werden?
Der erste Teil der Lösung des Rätsels heißt „Word2Vec“ (Mikolov et. al.). Diesem und ähnlichen Algorithmen liegt eine erstaunlich simple Annahme zugrunde: je ähnlicher der Kontext von zwei Wörtern (bzw. von zwei Sätzen) ist, also ihre textliche Umgebung, eine umso ähnlichere Bedeutung haben sie: Zum Beispiel liegen die Wörter „Frau“ und „Königin“ statistisch gesehen in einer ähnlicheren textuellen Umgebung als „Frau“ und „Fisch“, genauso wie „Angst“, „Furcht“, „schockierend“ aber auch „Flucht“ eine solche Verwandtschaft zeigen.
„Word2Vec“ sagt auf Deutsch „Wort zum Vektor“. Ein Word wird ein Vektor – ein Vektor ist ein mathematisches Objekt, das durch seine Richtung und seinen Betrag definiert wird und nicht wie eine einfache Zahl behandelt werden darf. Wir können hier aber einen Vektor einfach als eine Spalte mit Zahlenwerten betrachten und uns nur merken: Man kann Vektoren addieren und subtrahieren und somit auch ihre Entfernung im Raum berechnen. Kann man also aus einem genug großen Text einen Raum solcher Wortvektoren bauen, deren Entfernungen in diesem Raum auch ihre Bedeutung wiederspiegeln, also das, was ein Text aussagt?
Ja, man kann: Dabei lässt man ein künstliches neuronales Netz für jedes Wort eines Textes „Entfernungsgewichte“ zu jedem anderen Wort dieses „Textraums“ ermitteln. Diese Gewichte bilden dann die Komponenten des gegebenen Wortvektors. Erstaunlicherweise kann diese „Worteinbettung“ (word embedding) von einem künstlichen neuronalen Netz mit nur zwei Schichten berechnet werden, wie Google-Forscher herausgefunden haben. Trotzdem ist der Algorithmus sehr effizient. Mit der schon berühmt gewordenen Wortvektor-Rechnung: “King – Man + Woman” errechneten Mikolov und seine Kollegen (damals bei Google) einen Wortvektor, der ganz nah am Wortvektor für Queen stand. In dem hier verlinkten Blogeintrag ist das Word2Sync-Modell tiefgehender und bebildert erklärt.

Der „Word2Sync“-Algorithmus ist aber nur eine Seite des modernen maschinellen Sprechens. Welches künstliche neuronale Netz steckt aber hinter dem Sprachwunder von Google?
In der Bilderkennung leisten konvolutionelle neuronale Netze (CNN – convolutional neural networks) gute Arbeit. Sie können Bilder auf wichtige Parameter reduzieren. Bildlich vergleicht das Eckhart Wein mit der Funktion einer Taschenlampe. Wie ein Dieb, der in einer dunklen Galerie nach van Goghs Sonnenblumen sucht und das Spotlicht seiner Taschenlampe nur über die Blumen führt, ohne sich mit dem Bildhintergrund zu beschäftigen, lassen CNNs Unwichtiges an einem Foto weg und greifen nur das wichtige Motiv eines Bildes heraus: ein Gesicht zum Beispiel. Erst dann wird das so vorbereitete Bild in ein überwachtes künstliches neuronales Netzwerk gespeist, das mit vielen solchen Bildern trainiert wird, bis es jedes Gesicht erkennt. Ein mächtiges Werkzeug, das aufgrund dieser „Faltung“ bzw. Datenreduktion sehr viel Rechenleistung spart. Künstliche neuronale Netze müssen ja mit Unmengen an Daten trainiert werden, deren Handhabe auch unsere heutigen rechenintensivsten Computer überfordert.
Wer sich über die grundlegenden Arten der künstlichen neuronalen Netze und über ihre Unterschiede verständlich und relativ einfach informieren will, dem kann ich dieses wunderbare Taschenbuch „Artificial Intelligence. Making Machines Learn. A Friendly Introduction.“ von Eckhart Wein empfehlen.
Doch für eine tiefgehende Verarbeitung der natürlichen Sprache sind CNNs nicht geeignet. Ein Text ist eine Folge von Wörtern und Sätzen, also eine Sequenz. Wenn wir diesen Zusammenhang bei der Sprachverarbeitung erhalten wollen, brauchen wir ein künstliches neuronales Netz, das ein Gedächtnis hat, sich also grob gesagt bei der Bearbeitung eines Wortes daran „erinnert“, was das vorherige Wort war.
Solche mit „Gedächtnis“ arbeitenden Netzwerke gibt es tatsächlich, und das schon seit den 80er Jahren – rekurrente neuronale Netze (RNN – recurrent neural networks). Doch wie alle tief lernende neuronale Netze werden sie erst in den letzten Jahren exzessiv angewendet – dank der gestiegenen Rechenleistung unserer Rechner und den großen Datensätzen, an denen sie lernen können.
In einem RNN werden die Ausgabesignale der Neurone (Knotenpunkte im Netz) auf drei verschiedene Arten zurückgeleitet, damit der Zusammenhang in einer Sequenz nicht verloren geht und die Neurone sich quasi erinnern, was vor der momentanen Eingabe da war: Entweder wird das Neuron mit seiner Ausgabe gespeist, oder mit der Ausgabe eines Neurons der vorangehenden Schicht, oder mit der Ausgabe eines Nachbarneurons aus derselben Schicht. In diesem Sinn bekommt jedes Neuron eine ganz neue Eingabe und zusätzlich eine Eingabe aus der vorausgehenden Ausgabe. Am Bild sehen Sie nur die einfachste Art: Ein Neuron wird mit einer neuen Eingabe und mit seiner eigenen Ausgabe gespeist.
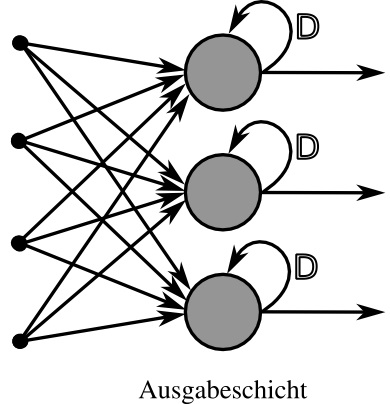
Rekurrentes neuronales Netz mit einer Schicht mit direkten Rückkopplungen. Quelle: Wikimedia Commons = Erstellt von Chrislb. Author = Christoph Burgmer.
Mit rekurrenten neuronalen Netzen kann man im Web auch selbst spielen: Mit etwas Python-Programmierung und der online frei zugänglichen NLP-Bibliothek TextBlob zum Beispiel eine Sentiment-Analyse (Gefühlsanalyse) der Tweets von Donald Trump durchführen, wie unter diesem Link Rodolfo Ferro. Wer hätte gedacht, dass 51 % von Trumps Tweets positiv sind?
Mit “Word2Vec” (Wort zum Vektor) und ähnlichen Algorithmen wie auch „Sen2Vec“ (Satz zum Vektor) werden Textdaten für die eigentliche Eingabe in den rekurrenten neuronalen Netzwerken vorbereitet. Für die weitere Verarbeitung dieser Textdaten nutzt GNMT (Google Neural Machine Translation) zwei rekurrente Netzwerke: einen Encoder und dem angeschlossenen Decoder. Dazu vielleicht aber ausführlicher in einem anderen Blogtext, damit ich hier bald zum Punkt komme. 🙂
Diese zwei verbundenen rekurrenten Netze des Google leisten nie Dagewesenes in der maschinellen Verarbeitung der natürlichen Sprache: Auf seiner diesjährigen Entwickler-Konferenz stellte Google seine Sprach-KI Duplex vor. Mit einer neuen Stimme des Google Assistants rief Duplex bei einem Friseur an und konnte dort einen Termin vereinbaren, ohne vom Friseur als ein Sprachprogramm (Chatbot) erkannt zu werden. Turing lässt grüßen. Mittlerweile bin ich relativ zuversichtlich, dass Chatbots den Turing Test bald reihenweise werden bestehen können, ohne allgemeine künstliche Intelligenzen zu sein. Um dem Menschen ebenbürtig zu werden, muss ein Chatbot wohl mehr leisten, als den Menschen nur täuschen zu können.
Im März dieses Jahres kündigte Microsoft einen neuen Chinesisch-Englisch-Übersetzer an, der laut Experten gleich gut wie ein menschlicher Übersetzer übersetzen könne. Die neuen künstlichen neuronalen Netze für NLP arbeiten selbstverständlich nicht wie das menschliche Gehirn. Trotzdem legen ihre Erfolge in der Verarbeitung der natürlichen Sprache nahe, dass das menschliche Gehirn sich bei seiner Arbeit Milliarden überlagerter neuronaler Netze bedient, also eines viel komplexeren Systems, als es zwei künstliche rekurrente neuronale Netze sind. Kann man Netzwerke im Gehirn auch mathematisch als statistische Optimierungsverfahren formalisieren? Vielleicht wenn wir zuerst lernen, künstliche neuronale Netze zu verstehen?
Wird eine Maschine irgendwann ein Werk wie “Faust” schreiben können?
willkommen auf meinem SciLogs-Blog "Gehirn & KI".
Ich möchte hier über alle möglichen Aspekte der Künstliche-Intelligenz-Forschung schreiben. Über jeden Kommentar und jede Diskussion dazu freue ich mich sehr, denn wie meine Mutter oft sagte:
"Solange die Sprache lebt, ist der Mensch nicht tot."
Neues über künstliche Intelligenz, künstliche neuronale Netze und maschinelles Lernen poste ich häufig auf meiner Facebook-Seite: Maschinenlernen
Hier etwas zu meiner Laufbahn: ich studierte Chemie an der TU München und promovierte anschließend am Lehrstuhl für Theoretische Chemie der TU über die Entstehung des genetischen Codes und die Doppelstrang-Kodierung in den Nukleinsäuren.
Nach der Promotion forschte ich dort einige Jahre lang weiter über den genetischen Code und die komplementäre Kodierung auf beiden Strängen der Nukleinsäuren:
Neutral adaptation of the genetic code to double-strand coding.
Stichworte zu meinen wissenschaftlichen Arbeiten: Molekulare Evolution, theoretische Molekularbiologie, Bioinformatik, Informationstheorie, genetische Codierung.
Zur Zeit bin ich Fachdozent für Künstliche Intelligenz an der SRH Fernhochshule und der Spiegelakademie, KI-Keynote-Speaker, Schriftsteller, Bühnenliterat und Wissenschaftskommunikator. Auf YouTube kümmere ich mich um die Videoreihe unserer SRH Fernhochschule "K.I. Krimis" über ungelöste Probleme und Rätsel der Künstlichen Intelligenz.
U. a. bin ich zweifacher Vizemeister der Deutschsprachigen Poetry Slam Meisterschaften.
Mein Buch „Doktorspiele“ wurde von der 20th Century FOX verfilmt und lief 2014 erfolgreich in den deutschen Kinos. Die Neuausgabe des Buches erschien bei Digital Publishers.
Mein Sachbuch über Künstliche Intelligenz "Ist das intelligent oder kann das weg?" erschien im Oktober 2020.
Im Tessloff-Verlag erscheinen meine von Marek Blaha wunderschön illustrierten Kinderkrimis "Datendetektive" mit viel Bezug zu KI, Robotern und digitalen Welten.
Viel Spaß mit meinem Blog und all den Diskussionen hier :-).
Jaromir
Für mich ist nicht (Zitat) die Sprache das Hauptmerkmal der Intelligenz, sondern das Denken. Dumm nur, dass Platon Denken als “stummes Sprechen (mit sich selbst)” interpretierte. Doch Platon ist mit solchen Vereinfachungen bei weitem nicht allein. Fast alle Philosophen und Denker, die etwas über Denken und Sprechen gesagt haben, lieferten suggestive Antworten, die aber letztlich nur Ausdruck eines tiefen Unwissens sind.
Für mich ist Sprechen eine Art Digitalisierung des Denkens, wie Buchstaben und Hieroglyphen als frühe Digitalisierung der Sprache aufgefasst werden können. Doch beim Digitalisierungsschritt vom Denken zum Sprechen wird viel wichtiges vom Denkprozess eliminiert – nämlich das dynamische, flüchtige, probabilistische.
Für mich basiert Denken auf einem inneren Beziehungsnetz zwischen den Objekten des Denkens, wobei Word2Vec nur gerade einen Aspekt dieses reichen inneren Beziehungsnetzes wiedergibt. Ein wesentlicher Aspekt des Denkens ist für mich die Imagination, das sich nur im Kopf abspielende Simulationsspiel, das “Was wäre wenn”-Spiel. Denken ist für mich auch nicht auf den Menschen beschränkt. Ein Eisbär, der unter einem kleinen Eisberg hindurchschwimmt um die Robbe auf der anderen Seite zu überraschen, der zeigt in meinen Augen, dass er etwas gedacht, ja möglicherweise einen ganzen Denkprozess durchlaufen hat.
Warum aber verwechseln so viele Menschen Sprache mit Denken? Wohl einfach darum, weil wir uns nur mit Sprache mitteilen können und wir letztlich sogar unser Denken nur über eine Versprachlichung fassbar machen können.
In diesem Zusammenhang möchte ich Werbung machen für den Spektrum der Wissenschaft- Artikel im Heft 7.18 mit dem Titel “Selbstständig lernende Roboter”. Dort wird die These vertreten, dass beim menschlichen Lernen der ständige Abgleich zwischen erwarteten Ereignissen und statfindenen Ereignissen eine wichtige Rolle spiele, dass also ständig eine innere Vorhersage der weiteren Entwicklung des Geschehens geschehe.
Übrigens basieren Humor und Witz gerade darauf, dass man die Erwartung des Zuhörers auf überraschende Weise enttäuscht/widerlegt.
@Martin Holzherr: “Für mich ist nicht (Zitat) die Sprache das Hauptmerkmal der Intelligenz, sondern das Denken.”
Für mich ist ein Merkmal “ein charakteristisches Zeichen, an dem eine bestimmte Person, Gruppe oder Sache, auch ein Zustand erkennbar wird”, so wie für den Duden auch. 🙂
Deswegen habe ich die Sprache als “Hauptmerkmal der Intelligenz” genannt, an dem man die Intelligenz/menschliches Denken erkennen kann. Deswegen hat wohl auch Turing die Prüflinge in seinem Test sprechen/schreiben und nicht z. B. Musik spielen lassen, um beurteilen zu können, ob sie Menschen seien oder Maschinen.
@Martin Holzherr: “Für mich ist Sprechen eine Art Digitalisierung des Denkens, wie Buchstaben und Hieroglyphen als frühe Digitalisierung der Sprache aufgefasst werden können. Doch beim Digitalisierungsschritt vom Denken zum Sprechen wird viel wichtiges vom Denkprozess eliminiert – nämlich das dynamische, flüchtige, probabilistische.”
Jaromir: Meiner Meinung nach ist das Denken und das Schreiben nicht nur die unvollkommene Wiedergabe des Denkens, wie Sie’s wohl mit der “Digitalisierung des Denkens” meinen, sondern eine Erweiterung des Denkens und seine Konzentrierung aufs Wesentliche – ein Säuberungsvorgang.
Ums literarisch zu sagen: Vielleicht ist das Schreiben das “künstliche neeuronale Netz”, das dem Denken hilft, wichtige Signale von den Unwichtigen zu trennen, das Rauschen zu eliminieren.
Einen Text zu verfassen, ist für jeden Schriftsteller ein sehr kreativer Vorgang, erst jetzt entsteht der Roman/die Geschichte/das Gedicht – die Kunst. Die Literatur wird ja als Kunst betrachtet, nicht das Denken der Autoren dahinter. Wohl Reich-Ranicki sagte mal: ein guter Roman muss klüger als sein Autor sein. Als Schriftsteller glaube ich: er hatte recht.
@Martin Holzherr: “Warum aber verwechseln so viele Menschen Sprache mit Denken?”
Jaromir: Ich hoffe schon, dass für die meisten Menschen – wie schon oben geschrieben – die Sprache die Äußerung des Denkens ist, eventuell wie für mich, seine Verdichtung. 🙂
Ergänzung: Wenn für mich bereits Eisbären denken können, stellt sich die Frage, was den Menschen denn über Eisbären auszeichnet. Es ist die Komplexität und die Abstraktheit der möglichen Gedanken, die den Unterschied ausmacht. Der Mensch kann nicht nur über Dinge nachdenken, sondern sogar über Gedanken über Dinge. Der Mensch kann übers Denken nachdenken. Dass kann kein Eisbär.
@ Jaromir Konecny: Ja, Sprache als Verdichtung, Säuberung aufgefasst, zeigt gerade einen wesentlichen Unterschied zwischen Denken und Sprache: Die Geschwindigkeit. So schnell reden (oder gar schreiben) wie denken, kann eigentlich niemand.
An den Autor: Warum wird hier erklärungs- und kritiklos NLP benannt bzw. (meiner Wahrnehmung nach) fast schon als synonym mit Sprache / Sprachstruktur an sich verwandt?
Meines Wissens ist NLP zumindest teilweise Pseudeowissenschaft und die angeblichen Effekte sind nicht belegt.
Ich würde den grundsätzlich interessanten Beitrag gern anderen empfehlen, aufgrund der Einbindung von NLP auf diese unkritische Art werde ich aber wohl davon absehen.
@Nik Fiend: Sie meinen mit NLP wohl “Neuro-Linguistische Programmieren”. 🙂
In meinem Artikel geht es um “Natural Language Processing”, also um maschinelle Verarbeitung der menschlichen Sprache, oder einfacher gesagt: Wie bringt man Computern das Sprechen bei.
Das benutzen Sie täglich, wenn Sie einen Online-Übersetzer gebrauchen oder ein computer gestütztes Sprachprogramm wie Siri oder Alexa und viele andere. 🙂
Kann aber sein, dass Sie nur einen Scherz gemacht haben, da NLP ja im Artikel genug erklärt ist. Trotzdem wünsche ich Ihnen einen schönen Tag!
@ Jaromir Konecny (Zitat): Kann aber sein, dass Sie nur einen Scherz gemacht haben, da NLP ja im Artikel genug erklärt ist. Trotzdem wünsche ich Ihnen einen schönen Tag!
Richtig. Hier stellt sich sogar die Frage, wie sicher man sein kann, dass Nik Fiend (not friend? oder gar Fiend als Anagram von Feind?) ein Mensch und kein AI-Programm ist. Nun, hier bin ich mir ziemlich sicher, dass Nik Fiend ein Mensch und kein AI-Programm ist, allein schon wegem dem ersten Satz:
Warum wird hier erklärungs- und kritiklos NLP benannt bzw. (meiner Wahrnehmung nach) fast schon als synonym mit Sprache / Sprachstruktur an sich verwandt?
Wir verstehen diesen Satz sofort als emotional gefärbte Aussage gegenüber einer umstrittenen Glaubenslehre namens NLP. Solche emotional gefärbten Sätzen sind typisch für Menschen. Eine Künstliche Intelligenz dagegen müsste die Emotion simulieren und würde dann wohl emotional weniger überzeugen.
Übrigens: Google versteht sich neurdings sogar auf Scherze. Ich habe eben Anagram in googles Suchleiste eingegeben und Google antwortete: Did you mean: Nag A Ram
🙂 Danke für den Hinweis. Ich habe mich im Namen vertippt, habe es jetzt geändert. Mit den Namen von anderen sollte man keine Scherze treiben.
Bei meinem Blogtext habe ich mir aber tatsächlich viele Gedanken über die Bezeichnung “Natural Language Processing” (NLP) gemacht. Zuerst verwende ich als Tscheche, der deutscher Schriftsteller geworden ist, sehr gern deutsche Ausdrücke und nicht englische, zu zweit musste ich mindestens die suchmaschinen-bedingte Verwechslung mit dem anderen NLP befürchten. Nun ist aber der deutsche Ausdruck dafür “maschinelle Verarbeitung der natürlichen Sprache” ein Wortungetüm – wenn man das zehnmal im Text verwenden soll, tut’s einem weh. Trotzdem habe ich den Text jetzt angepasst und auch das NLP entweder damit oder mit “maschinelles Sprechen” ersetzt. 🙂
@Martin Holzherr: Übrigens: Google versteht sich neurdings sogar auf Scherze. Ich habe eben Anagram in googles Suchleiste eingegeben und Google antwortete: Did you mean: Nag A Ram
Jaromir: Das finde ich großartig! 🙂
JK
Schreiben (Sprechen) und Denken
Die Kryptologie liefert ein schönes Modell über Denken und Sprechen bzw. Schreiben
Auf der untersten Stufe liegt die Wahrnehmung , die ein Gefühl auslöst.
Das Gefühl wird codiert in einen Laut. z.B. Aah, Au,
Jetzt schaltet sich das Gehirn dazu und der Schmerzenslaut wird in Sprachform codiert :Aua
Das Geschehnis wird reflektiert (gedacht) und in Sprachform codiert : So ein Mist,
Wenn ich diesen Sachverhalt der Nachbarin erzähle, dann dramatisiere ich noch mehr und benütze auch noch andere Wörter. Gestern ist mir der Aktenordner auf den Zeh gefallen…..
Das heißt, das Sprechen und Schreiben erfordert eine komplexe Denkleistung und das Merkmal bei all diesen Schritten ist die Codierung. Und beim Schreiben kommt noch eine weitere Codierung hinzu, die der normgerechten Rechtschreibung.
1. Fühlen
2. Codierung als Laut
3. Codierung als Lautmalerei in der jeweiligen Sprache
4. Codierung in Satzform
5. Codierung in normgerechter Form der jeweiligen Sprache und
6. Codierung in die Schriftzeichen der jeweiligen Sprache.
Der Kryptologe verändert entweder die Laute bzw. Sprache oder er verändert die Schriftzeichen.
@Lennart:
Danke für Ihren erhellenden Beitrag. Kryptologie und Codierung ist meiner Meinung nach für die maschinelle Verarbeitung der natürlichen Sprache sehr wichtig. Ich muss mich mit Kryptologie wieder mal etwas beschäftigen.
Nachdem Shannon seine Informationstheorie augefstellt hatte, sollte mit seiner Informationsformel, die er der Thermodynamik entnahm (für Entropie) nur die Syntax einer Nachricht behandelt werden. Jahrelang sträubten sich dann Informationstheoretiker dagegen, die Semantik der Nachrichten zu quantifizieren. Deswegen wurden Codes nur für die Syntax einer Nachricht entwickelt. Man dachte nun mal, die Bedeutung einer Nachricht ist mathematisch nicht quantifizierbar. Mit Word2Vec-Modellen bzw. -Vektorräumen, deren Vektoren auch etwas von der Bedeutung einer Nachricht codieren, ändert sich das aber. Hier interessiert mich sehr: Wie groß ist der Teil der semantische Information eines Textes, der bei der Word2Vec-Codierung verloren geht? Und: Wie kann man einen Text codieren, also in Zahlen umwandeln, damit möglichst viel seiner Bedeutung erhalten bleibt?
M.Holzhherr:
“Weil wir uns nur mit Sprache mitteilen können…”
Einspruch. Die Evolution hat uns die Mimik und Gestik gegeben. So kommunizieren Eltern mit ihrem Baby auch über diese Art der nonverbalen Kommunikation.Instinktiv schauen wir anderen Menschen zuerst in ihr Gesicht, da uns Mimik und Gestik erste wichtige Informationen über das Wesen dieses Anderen mitteilen. Die Evolution hat uns dafür mit EMPATHIE ausgestattet. Über unsere Spiegelneuronen im Gehirn werden wir befähigt den Zustand der anderen Person emotional zu erfassen. Paare, die jahrzehntelang zusammen leben,benötigen kaum noch sprachliche Kommunikation, da die nonverbale Kommunikation (Blicke, Haltungen ) den jeweiligen Zustand des anderen manifestiert.
Wahrscheinlich basiert Sprache auch auf die in Worten gefaßten Erklärungsversuche von Mimik und Gestik.
@Golzower: “Die Evolution hat uns die Mimik und Gestik gegeben. …”
Jaromir: Das ist eine wichtige Anmerkung: Unser Denken wird bei unserer Kommunikation nicht nur in Sprache “übersetzt” und verdichtet, sondern auch in unsere Mimik und Gestik. Auch wenn wir uns davon im Zeitalter des Internets und der geschriebenen Nachrichten zunehmend entfernen. 🙂
Wenn man darüber nachdenkt, welcher Klotz durch welche Öffnung passt, dann verwendet man dazu normalerweise keine Sprache.
Roboter und Computerspiele verwenden zu diesem Zweck 3d-Modelle.
Ein Bild sagt mehr als tausend Worte.
Ein praktisches Beispiel:
https://www.youtube.com/watch?v=YMTGP9fM04A
@Karl Bednarik: “Wenn man darüber nachdenkt, welcher Klotz durch welche Öffnung passt, dann verwendet man dazu normalerweise keine Sprache.”
Jaromir: 🙂 Das stimmt! Ein schönes Beispiel.
JK
Text und Bedeutung
Die Bedeutung eines Textes ergibt sich einmal aus dem Wortlaut selbst , aber auch aus dem Kontext, der gar nicht mal geschrieben sein muss, “das was zwischen den Zeilen steht” und dem Umfeld (ich nenne es mal so) , das was alles zu einem Begriff dazugehört, das was der Schreiber beim Lesen eines Begriffes voraussetzt. Bei dem Begriff Abgasschwindel wird vom Katalysator nicht gesprochen, wird von Stickoxiden nicht gesprochen, da bestimmt die Zielsetzung des Berichtes, was relevant ist im Zusammenhang mit diesem Text.
Ich denke, dass ist das Schwierigste für die KI, zu erkennen, was ist die Zielsetzung des Berichtes, und welche Themen werden als gewusst vorausgesetzt.
Eine 1 : 1 Übersetzung von geschriebener Sprache in Ziffern ist möglich, sogar ohne Verlust, aber die Rückübersetzung in eine andere Sprache geht nur lückenhaft, weil sich Worte nicht 1 : 1 in eine ander Sprache übersetzen lassen. Bei Redewendungen wird es noch schwieriger und wenn sie dann auch noch ironisch gemeint sind, dann haben wir Menschen ja sogar Schwierigkeiten.
@Lennart: “Text und Bedeutung
Die Bedeutung eines Textes ergibt sich einmal aus dem Wortlaut selbst , aber auch aus dem Kontext, der gar nicht mal geschrieben sein muss, “das was zwischen den Zeilen steht” und dem Umfeld (ich nenne es mal so) , das was alles zu einem Begriff dazugehört, das was der Schreiber beim Lesen eines Begriffes voraussetzt.”
Jaromir: Der Word2Vec-Algorithmus im künstlichen neuronalen Netz lernt, aus dem Kontext der Wörter im Text ähnliche Wörter im Raum der Wortvektoren in der Nachbarschaft zu gruppieren – je ähnlicher der Kontext von zwei Wörtern um so ähnlicher sind sie3 und um so näher liegen ihrer Wortvektoren im Raum der Wortvektoren beisammen. Der Algorithmus kennt also nicht die Bedeutung der einzelnen Wörter und schafft es trotzdem, nur aus dem Kontext etwas Bedeutung herauszulesen. Das finde ich einfach erstaunlich.
@Lennart: “Eine 1 : 1 Übersetzung von geschriebener Sprache in Ziffern ist möglich, sogar ohne Verlust, aber die Rückübersetzung in eine andere Sprache geht nur lückenhaft, weil sich Worte nicht 1 : 1 in eine ander Sprache übersetzen lassen. Bei Redewendungen wird es noch schwieriger und wenn sie dann auch noch ironisch gemeint sind, dann haben wir Menschen ja sogar Schwierigkeiten.”
Jaromir: Das stimmt. Nur sind die künstlichen neuronalen Netze wohl mittlerweile einem normal intelligenten menschlichen Übersetzer ebenbürtig, wenn man den Experten glauben darf, die den neuen Microsoft-Englisch-Chinesisch-Übersetzer beurteilt haben. Und wie im Artikel oben beschrieben schafft auch der neue neuronale Übersetzer von Google langsam Wunder. Obwohl man über das Programm noch vor zwei Jahren nur lachen konnte. Ich bin davon überzeugt, dass die KIs in zwei, drei Jahren auch Literatur autonom übersetzen können.
@Karl Bednarik;
Zu diesem Zweck eignen sich auch vorsprachliche Kleinkinder. Man gibt ihnen ein Spiel an die Hand, genau mit dieser Funktion.
Die Sprache ist das wichtigste Ausdrucksmittel des Menschen, neben Gestik und Mimik. Man kann in das Hirn nicht hineinschauen, um die Gedanken zu sehen oder zu erraten. Was und wie der Mensch denkt, lässt sich nur in seinen Ausdrucksweisen erkennen. Der Expression der Gedanken steht auf der anderen Seite die Impression gegenüber. Dabei ist das Verhältnis von Expression und Impression immer unterdeterminiert, denn jedes Ausdrucksmittel bedarf der Deutung. Hier liegen die Quellen für Missverständnisse in der Kommunikation.
@anton reutlinger: “Was und wie der Mensch denkt, lässt sich nur in seinen Ausdrucksweisen erkennen. Der Expression der Gedanken steht auf der anderen Seite die Impression gegenüber. Dabei ist das Verhältnis von Expression und Impression immer unterdeterminiert, denn jedes Ausdrucksmittel bedarf der Deutung. Hier liegen die Quellen für Missverständnisse in der Kommunikation.”
Jaromir: Zum Beispiel wollte ich Karin immer eine Geschichte erzählen, während sie wollte, dass ich zum Punkt komme. 🙂
@anton reutlinger (Zitat): Man kann in das Hirn nicht hineinschauen, um die Gedanken zu sehen oder zu erraten. Ja, aber Telepathie ist ein alter Wunsch- (oder Alb-) Traum. Elon Musks Neuralink will solche Telepathie mittels Brainimplantat ermöglichen, wobei ihm aber nicht die Kommunikation zwischen 2 Personen vorschwebt, sondern die Kommunikation einer Person (die den Neuralink implantiert hat) mit dem Computer/Internet.
Mit Gedanken kommunizieren kann man jedenfalls nur dann ohne weiteres, wenn Personen, die gleiche Gedanken haben, mental gleiche oder ähnliche Aktivitäten haben. Damit stellt sich die Frage. Wenn zwei Personen an die Zahl 13 denken, gibt es dann eine gleichartige Hirnaktivität bei diesen beiden? Untersuchungen dazu scheinen das bis zu einem gewissen Grad zu bestätigen – mindestens, wenn die Personen nicht an abstrakte Dinge denken, sondern beispielsweise denselben Film anschauen. In diesem Fall – beide schauen denselben Film – findet man sehr ähnliche Hirnaktivität.
Im sehr empfehlenswerten Quanta-Magazin ist gerade ein wunderbarer Artikel über die Prediktive-Kodierungs-Hypothese des Gehirns und künstliche neuronale Netze erschienen: Deep Mind hatte ein künstliches neuronales Netz (GQN – Generative Query Network) vorgestellt, das eine virtuelle dreidimensionale “Welt” aus wenigen zweidimensionalen Bildern vervollständigen konnte. Das Netz konnte also voraussagen, wie diese virtuelle “Welt” insgesamt aussah. Darüber wollte ich auch mal hier im Blog schreiben, jetzt muss ich das anders angehen. 🙂 Auf jeden Fall kann ich den Artikel sowie das Quanta-Magazin wärmstens empfehlen:
Nach der Hypothese der prediktiven Kodierung macht das Gehirn ständig Voraussagen über die Welt und die unmittelbare Zukunft. Wenn die Voraussagen falsch sind, korrigiert das Gehirn sie und lernt dadurch. Dieses Modell erklärt auch gut, warum wir bei unseren Handlungen aber auch Gesprächen nicht ständig ins Stocken kommen.
Zwar gehört das nicht ganz zu meinem Blogtext oben über die menschliche und maschinelle Sprache, andererseits habe ich in diesem Blogtext auch das prediktive Modell in Zusammenhang mit einem Gespräch erwähnt:
“Mit Hilfe seines gesamten Wissens versucht unser Gehirn ständig vorauszuahnen, was unser Gesprächspartner sagen würde, damit das Gespräch flüssig bleibt.”
Auch meine kleine Hypothese :-), die ich hier schon öfter erwähnt habe, dass das Gehirn eine Überlagerung von Milliarden kleiner und großer neuronaler Netze ist, stimmt mit der “prediktiven Kodierung” überein. Oft betonen wir, die sich mit künstlichen neuronalen Netzen etwas auseinandersetzen, dass sie nur auf einer sehr großen Vereinfachung des Gehirns und seiner Funktionen basieren. Trotzdem glaube ich mittlerweile, dass die künstlichen Netze und das Gehirn beide sich der Fähigkeit des Perceptrons und somit des Multi-Layer-Perceptrons (ein Netz aus Neuronen einfach gesagt) bedienen, rechnen und lernen zu können, wenn durch ein solches Netz richtige Signale fließen: entweder durch die Gehirnaktivität in Bewegung gesetzt oder durch Algorithmen in künstlichen Netzen.
Der große Unterschied zwischen den natürlichen neuronalen Netzwerken im Gehirn und den künstlichen, wäre dann die Beschaffenheit der Knotenpunkte dieser Netze. In künstlichen Netzen sind sie nun mal nur Knotenpunkte, im Gehirn dagegen hoch autonome kleine Fabriken – Gerhirnzellen. In diversen Gehirnzellen-Verbänden erzeugen sie dann diverse Gehirnaktivitäten, die sich überlagern usw. Das bewerkstelligen unsere Gehirnzellen mit Hilfe ihrer genetischen Ausstattung, ihrer erlernten Dynamik und Struktur und dank dem Einfluss anderer Gehirnzellen.
Somit wäre auch die Korrektur der Gehirnvoraussagen eine sehr komplexe Fehlerrückführung, also Backpropagation of Error, wie man sie in künstlichen neuronalen Netzen als Algorithmus anwendet. 🙂
@ Jaromir Konecny (Zitat): Somit wäre auch die Korrektur der Gehirnvoraussagen eine sehr komplexe Fehlerrückführung, also Backpropagation of Error, wie man sie in künstlichen neuronalen Netzen als Algorithmus anwendet. Nur, dass die für das Deep Learning in tiefen neuronalen Netzen so wichtige Backpropagation – also das Setzen/Korrigieren von Inputgewichten für die rückwärtigen Neuronen aufgrund eines Fehlers an der Front (im Output) – biologisch nicht realistisch ist. In den Nervenzellverbänden des Hirns gibt es keinen massiven Rückfluss von Information, die Information fliesst (fast immer) von Neuron A zu B und von dort zu C, aber kaum je wieder zurück von C zu A. Mir scheint, man hat heute noch nicht wirklich verstanden wie das Gehirn genau lernt. Man hat es konzeptionell aber sogar besser verstanden als auf der biologischen Ebene, auf der Ebene der Nervenzellen und ihrem Geflecht versteht man es eigentlich überhaupt nicht. Das spricht auch Yoshua Bengi in Towards Biologically Plausible Deep Learning an, wo er schreibt (übersetzt von DeepL):
Betrachten wir zunächst die Behauptung, dass moderne, tiefe
Lernalgorithmen auf Mechanismen beruhen, die biologisch unplausibel erscheinen, wie z.B. die Gradientenrückpropagation, d.h. der Mechanismus zur Berechnung des Gradienten einer Funktion in Bezug auf neuronale Aktivierungen und Parameter. Die folgenden Schwierigkeiten können hinsichtlich der biologischen Plausibilität der Backpropagation aufgeworfen werden:
(1) die Back-Propagation-Berechnung (von der Outputebene kommend gerichtet auf auf untere versteckte Ebenen) ist rein linear, aber biologische Neuronen verschachteln lineare und nichtlineare Operationen,
(2) wenn die im Gehirn bekannten Rückkopplungswege (mit ihren eigenen Synapsen und möglicherweise ihren eigenen Neuronen) zur Ausbreitung der Kreditvergabe durch Backprop verwendet würden, bräuchten sie genaue Kenntnisse über die Ableitungen der Nichtlinearitäten am Arbeitspunkt, der in der entsprechenden Feedforward-Berechnung auf dem Feedforward-Pfad verwendet wird,
(3) In ähnlicher Weise müssten diese Rückkopplungspfade exakt symmetrisch zu den Vorwärtspfaden angelegt sein,
(4) reale Neuronen kommunizieren durch (möglicherweise stochastische) Binärwerte (Spikes), nicht durch saubere kontinuierliche Werte,
(5) Die Berechnung müsste genau getaktet werden, um zwischen Feedforward und Back-Propagation zu wechseln (da Letzteres die Ergebnisse des ersten benötigt), und
(6) es ist nicht klar wo die Ziele für den Output (die Labels des supvervised Learnings) herkommen sollten
Yoshua Bengi gehört dabei zu der nicht kleinen Zahl der Deep Learning-Forscher, der gerade auch daran interessiert ist, wie reale Gehirne lernen und für Yoshua Bengi ist es ziemlich klar, dass die für das Lernen von künstlichen neuronalen Netzen so wichtige Backpropagation in realen Gehirnen nicht funktionieren kann.
Er schlägt im Artikel deshalb einen biologisch motivierten Algorithmus für das natürliche Lernen in Gehirnnetzwerken vor und meint, dass dieser auch für künstliche neuronale Netze vielversprechend sein könne.
Man muss sich aber bewusst sein, dass echter, grundsätzlicher Fortschritt im neuronalen Computing äusserst langsam vor sich geht und dass auch ein Konsensus über die wichtigsten Mechanismen des Lernens von Hirnen heute noch nicht existiert. Das Human Brain Project wurde deshalb von vielen Hirnforschern und selbst von Deep Learning-Forschern als zu ambitioniert kritisiert (Zitat Wikipedia, übersetzt von DeepL): Peter Dayan, Direktor für Computational Neuroscience am University College London, argumentierte, dass das Ziel einer groß angelegten Simulation des Gehirns radikal verfrüht sei,[14] und Geoffrey Hinton sagte, dass “das reale Problem mit diesem Projekt ist, dass sie keine Ahnung haben, wie man ein so großes System zum Lernen bekommt”.
@Martin Holzherr: “Nur, dass die für das Deep Learning in tiefen neuronalen Netzen so wichtige Backpropagation – also das Setzen/Korrigieren von Inputgewichten für die rückwärtigen Neuronen aufgrund eines Fehlers an der Front (im Output) – biologisch nicht realistisch ist.”
Jaromir: Der Vergleich mit “Backpropagation” der künstlichen neuronalen Netze war nur ein Scherz – deswegen das Smiley dabei. Eine “sehr komplexe Fehlerrückfuhrung” im Gehirn war aber ernst gemeint: Wenn die Prediktive-Kodierung-Hytpothese beim Gehirn stimmt, dann muss das Gehirn seine falschen Voraussagen sofort korrigieren und dadurch lernen, um in der Zukunft auf eine ähnliche Situation besser reagieren zu können. Das ist dann eine “Fehlerrückführung”, klar aber nicht nur eine einfache Rückführung der Outputsignale. An dieser Funktion sind nun mal viel mehr hoch komplexe Netzwerke beteiligt als in einem Computer mit einem künstlichen neuronalen Netz.
Danke für den Hinweis auf Yoshua Bengi – das klingt alles sehr vernünftig, was er schreibt. Ich glaube aber, einen einzigen “biologisch motivierten Algorithmus für das natürliche Lernen in Gehirnnetzwerken”, wie Bengi vorschlägt, wird es nicht geben. Wenn, wie ich annehme, das gesamte neuronale Netz im Gehirn eigentlich eine hoch komplexe Überlagerung von Milliarden kleiner und großer neuronaler Netzwerke ist, dann werden dort auch etliche “Algorithmen” zusammen und gegeneinander wirken, oder vielleicht nur wenige Algorithmen, die aber durch Verstärkung, funktionelle Überlagerung und Dämpfung, und das in allen möglichen Arten und Abarten, die Neurone zum Feuern bringen, oder wohl besser gesagt, durch die hoch komplexen Aktivitäten der Neurone als Algorithmen definiert werden können.
Das Gehirn richtet sich ja nicht nach einprogrammierten Algorithmen, nur kann uns der wissenschaftliche Reduktionismus auch hier erlauben, die Gehirnaktivität auf das Zusammenspiel von einigen definierbaren Vorgängen zurückzuführen, die man dann eventuell auch als Algorithmen aufstellen oder mathematisch formalisieren kann. Vielleicht nicht ganz, in einem bestimmten Umfang aber schon. Obwohl wir viel nicht wissen, können wir der Natur immer mehr Geheimnisse entlocken.
MH
als Laie macht man sich auch seine Gedanken, wie das Lernen funktioniert.
Mir fällt auf, dass beim Menschen die Sinnesorgane Ohr, Auge, Nasenöffnung, Hände, Gehirn doppelt angelegt sind. Ist das so, weil es sich bewährt hat ?
Wenn wir also 2 Augen haben, dann haben wir im Gehirn mindestens 2 Neuronen dafür.
Und diese Dualität ist notwendig, um Ursache und Wirkung zu erkennen, bzw. zu erlernen.
Wenn man einen Regenwurm mit der Taschenlampe anleuchtet, dann geschieht nichts. versetzt man ihm aber gleichzeitig einen elektrischen Schlag, dann zuckt er zusammen. Wenn man das öfter macht, dann zuckt er schon zusammen, wenn man ihn anleuchtet, auch ohne Stromschlag. Also hat er was gelernt.
Ich stelle mir das so vor, dass das Neuron für das Licht und das Neuron für den Stromschlag sich verknüpfen, als logisches “Und”. Und am Ende braucht man nur ein Neuron zu reizen, dann zuckt der Regenwurm zusammen. Lernen ist also ganz mechanisch zu denken. Die Neuronen haben sich wie beim Computer miteinander verbunden. Beim Computer gibt es dafür Logikbausteine, die “AND” heißen. In der Praxis nimmt man NAND Bausteine, die das Ergebnis invertieren.
@Lennart (Zitat): “… beim Menschen die Sinnesorgane Ohr, Auge, Nasenöffnung, Hände, Gehirn doppelt angelegt sind.” Doppelte Augen, Ohren und Nasengänge lassen sich auch einfacher begründen: mit Sicherheit durch Redundanz. Nichts oder wenig zu sehen oder zu hören, kann für Tiere und Menschen den baldigen Tod bedeuten. Wohl auch deshalb die Verdoppelung, die es übrigens in der Raumfahrt ebenfalls bei vielen Systemen gibt, denn auch bei Raumsonden ist das “überleben” (der sündhaft teuren Sonde) häufig etwas vom Wichtigsten.
Zu Lennart : LERNEN
Schon Eric Kandel hat mit seinen Versuchen an der Seeschnecke Aplysia das Prinzip des Lernens nachgewiesen: Lernen ist, wenn der Organismus zwei oder mehrere gleichzeitig auftretende Reize miteinander verbindet/verknüpft. Auf diesem, Prinzip basiert auch die Klassische Konditionierung nach Pawlow. Es erfolgt sozusagen eine Assoziation.Die Sinnesorgane dienen hierbei lediglich der Aufnahme von Reizen. Der Schüler lernt in der ersten Klasse die Buchstaben A bis. Z. Er lernt , dass er diesen Reiz “A” mit dem Reiz “M” zu “MAMA” assoziieren kann. Die Schreibweise “MAMA” wird nun im Langzeitgedächtznis (Unterbewusstsein ) abgespeichert und ist jederzeit abrufbereit.Besonders eingeprägt werden solche Assoziationen durch emotionale Bewertungen.MAMA ist als solcher ein sehr starker emotionaler Reiz . Das Prinzip des Denkens basiert meiner Ansicht nach auf die bewußte und unbewußte Verknüpfung von Assoziationsmustern.
MH
mir geht es mehr um das Prinzip der Dualität.
Ein Neuron allein kann nichts lernen. Zwei Neuronen können geprägt werden, wenn sie eine Verbindung bekommen. Das bedeutet, dass Lernen als der Aufbau einer Struktur gesehen werden kann. Und wenn man die künstliche Intelligenz betrachtet, dessen Grundmuster ein NAND Baustein ist, dann kann man da schon eine Parallele sehen.
@Lennart: Nicht das Lernen an und für sich ist das Problem, sondern die Optimierung, die Eliminierung von Fehlern. Das Training von neuronalen Netzwerken läuft auf die Minimierung von Fehlern hinaus. Der Mensch ist ja auch ständig mit Fehlern konfrontiert und korrigiert sie ständig. Aber die Fehlerkorrektur bei uns scheint auf einer höheren Ebene abzulaufen als direkt bei der Neu- oder Andersverknüpfung von einzelnen Nervenzellen.
@Konecny: Eine schöne Arbeit, die zeigt wie Fehler verarbeitet werden:
http://www.sciencedaily.com/releases/2018/05/180503142656.htm ´Decoding the brain´s learning machine´
off topic: per Google [Kinseher NDERF denken_nte] findet man ein PDF mit meinem Erklärungsmodell für ´Nahtod-Erfahrung´(NTE). Wir können bei NTEs bewusst erleben, wie das Gehirn einen Reiz verarbeitet: eine Arbeitsweise die als Hypothese ´predictive Kodierung´ bezeichnet wird – kann damit mit konkreten eigenen Erlebnissen belegt werden. Seite 2 C-1 und Seite 4 sind die Regeln zu lesen. Seite 4-unten wird der ´Zeitlupeneffekt / slow motion perception´ erklärt
Die beschriebene Arbeitsweise erklärt auch, wie wir Sprache verarbeiten: per Mustervergleich durch Re-aktivieren vergleichbarer Erfahrungen. Und wenn man etwas falsches reaktiviert hat, dann wird dies mit 400 Millisekunden-Signal als Gehirnaktivität erkennbar (Wie im Quanta-Magazin-Artikel beschrieben: To make sense of the present brains may predict the future)
Diese Arbeitsweise ist übrigens bei vielen Witzen erkennbar: Am Anfang wird eine Erwartung im Gehirn erzeugt (= reaktiviertes Wissen) – und wenn das Ende des Witzes anders als erwartet ist, dann lachen wir weil wir diesen Fehler bemerkt haben.
Predictive coding (Zitat Wikipedia: Das Gehirn generiert und aktualisiert ständig Hypothesen, die den sensorischen Input auf verschiedenen Abstraktionsebenen vorhersagen) als Hypothese wie das Hirn arbeitet, gewinnt zunehmend an Unterstützern. Das aktuelle Spektrum der Wissenschaft 7.18 berichtet im Artikel “Selbstständige lernende Roboter” sogar über eine Anwendung dieser Verarbeitungsweise im I-Cube-Roboter (ähnelt äusserlich einem Kind). Unter anderem entstehe allein schon durch diese Arbeitsweise, in der der Roboter Voraussagen macht und Abweichungen von der Vorhersage als (zu minimierende) Fehler empfindet, eine einfache Art des sozialen Verhaltens. So reagiert I-Cube beispielsweise auf eine falsche Plazierung einer Eisenbahn durch eine Testperson mit einer Aktion, die das korrigiert und die Eisenbahn an den “richtigen” Ort setzt. Das entspricht ungefähr dem Bedürfnis die Dinge an die “richtigen” Orte zu versorgen, das ja einige von uns kennen.
@Holzherr
Als Reaktion auf einen neuen Reiz reaktiviert das Gehirn sofort dazu passende Erfahrungen – damit man sofort reagieren kann. Dies ist unsere wichtigste Überlebensfunktion.
Der arxiv-Artikel Deep Predictive Coding Network for Object Recognition berichtet über ein von den Autoren nach den Ideen des Predicitve Coding (ständiger Abgleich Vorausage/Hypothese mit sensorischem Input) implementierten bidirektionalen und rekurrenten neuronalen Netzes, von ihnen “Deep Predicitve Coding Networks” (PCN) genannt.
Eingesetzt wird dieses PCN-Netz für Klassifizierungsaufgaben (Erkennen von Tieren aus Fotos, Erkennen von handgeschriebenen Ziffern, etc) und es scheint praktisch immer besser abzuschneiden als klassische mehrschichtige (tiefe) neuronale Netze. Während klassiche mehrlagige neuronale Netze komplexere Aufgaben durch eine tiefere Architektur, also mehr Schichten von Neuronen, bewältigen, bewältigt ein PCN-Netz komplexere Aufgaben durch mehr Zykeln des Abgleichs von Vorhersage, Vergleich mit dem sensorischen Input und Verfeinerung der Vorhersage.
Die Autoren sind der Überzeugung, dass dies auch den Verhältnissen bei intelligenten Leistungen von Tieren und Menschen entspricht, die ebenfalls für komplexere Aufgaben nicht etwa komplexere Hirne entwickeln (was sie ja nicht für jedes neue Problem können), sondern länger nachdenken, was heisst, dass sie mehr Zyklen des Abgleichs von Hypothese und Realität durchlaufen müssen.
@Martin Holzherr: “Der arxiv-Artikel Deep Predictive Coding Network for Object Recognition berichtet über ein von den Autoren nach den Ideen des Predicitve Coding (ständiger Abgleich Vorausage/Hypothese mit sensorischem Input) implementierten bidirektionalen und rekurrenten neuronalen Netzes, von ihnen “Deep Predicitve Coding Networks” (PCN) genannt.”
Jaromir: Ich habe mir den Artikel jetzt schnell angeschaut: Es wird hier ein rekurrentes neuronales Netz von einer etwas komplexeren Architektur als die gängigen Netze verwendet. Sonst wird hier aber auch ein Gradientenverfahren benutzt, das Minimum der Fehlerfunktion gesucht und die Korrekturen ins Netz zurückgeführt – Backpropagation eben. 🙂
Das entnehme ich den Formeln und das sagen die Autoren ja auch selbst: “The error of classification backpropagates (top-down and bottom-up) across layers and in time to update the model parameters for multiple times (as many as the cycles of recursive computation) per training example or batch of examples.”
Vorläufig gibt es aber – meiner Meinung nach – keinen Beleg dafür, dass “Backpropagation of Error” auch in einem biologischen System, also im Gehirn, “benutzt” wird. Darüber haben wir schon oben gesprochen. Vielleicht irre ich mich: Ich kann mir aber wirklich momentan nicht vorstellen, dass die Funktionen des Gehirns mit einem einzigen neuronalen Netz erklärt werden können, egal wie kompliziert die Algorithmen sind, nach denen Signale durch das Netz geleitet werden. Na, ja, wenn die Algorithmen so kompliziert sind, dass sie auch ein genug großes Netzwerk ständig und grundlegend ändern das heißt dynamisch in viele kleine Netzwerke teilen und wieder zu größeren Netzwerken zusammensetzen, die überlagert und sich überschneidend zusammen arbeiten, würde dieses Modell vielleicht schon etwas das Gehirn wiedergeben. Ein solches Modell ist aber zu Zeit rechentechnisch nicht simulierbar.
Ich nehme an, dass im Gehirn sehr viele neuronale Netzwerke überlagert arbeiten, bzw. verkoppelt sind. Wenn es stimmt, bleibt dann die Frage, inwieweit man sich dem Gehirn mit einem Modell nähern kann, wenn man seine Eigenschaften wie die “prediktive Kodierung” in einem einzigen neuronalen Netz umzusetzen versucht. Zumal die “prediktive Kodierung” immer noch nur eine Hypothese ist, an die ich aber glaube – das gebe ich zu.
Ich führe hier aber auch oft Sachen an, die einzelne künstliche neuronale Netze bewerkstelligen und dadurch ähnliche Funktionen ausführen wie das menschliche Gehirn. Am Ende finde ich solche Arbeiten wie die diesen PCN-Artikel sehr nützlich, zumal ein solches Netzwerk anscheinend bessere Ergebnisse erzielt als klassische CNNs.
Noch einmal vielen Dank für den Tipp!
Zu K Richard:
Ich stimme ihnen zu. Das Gehirn befindet sich im ständigen Bewertungsmodus. Es kann nicht anders. Dadurch erfolgt ein permanentes LERNEN und eine permanente Veränderung der neuronalen Netze (Pastizität des Gehirns) Neuronale Verschaltungen, die “altes Wissen” beinhalten, werden durch neues Wissen ersetzt und veröden bzw. feuern nicht mehr.Ursache ist der Zwang der Evolution zur ständigen Bewertung. Künstliche Intelligenzen, wollen sie denn intelligent sein, müssen diesen Schritt nachvollziehen können.Sie müssen also den emotionalen und rationalen Wert von Reizen bewerten können.
@Golzower
Neuronale Verbindungen die ´altes´ Wissen beinhalten – werden nicht durch neues Wissen ersetzt; sondern dieses alte Wissen wird durch neue Informationen ergänzt. D.h. das Netzwerk mit Informationen wird vergrößert, je mehr wir dazu lernen.
(Erlebnisse ab dem 5. Schwangerschaftsmonat sind lebenslang erinnerbar. Dies belegt, dass ´altes´ Wissen nicht verschwindet.)
Zur Verarbeitung von Reizen/Gedanken nutzt das Gehirn unterschiedliche Strategien: z.B. a) reaktivieren vergleichbarer Erlebnisse (das ist die schnellste Arbeitsweise), b) wenn keine vergleichbare Erfahrung verfügbar ist – dann muss das Gehirn länger im Gedächtnis suchen/nachdenken (wie @Holzherr richtig anmerkte)
@Golzower:
Bei Wikipedia ´Schnelles Denken, langsames Denken´ finden Sie Infos zur Theorie von Daniel Kahnemann
@Golzower: noch ´ne Info
http://www.spektrum.de/magazin/synapsen-im-dornroeschenschlaf/1017127
(= Gehirn&Geist Artikel aus Heft 1-2/2010)
einmal geknüpfte Verbindungen im neuronalen Netzwerk können sich zurückbilden, wenn sie lange nicht gebraucht werden – diese Verbindungen bleiben trotzdem dauerhaft bestehen
Zu K Richard:
“diese Verbindungen bleiben trotzdem dauerhaft bestehen.”
Ich denke, dass zum Beispiel ein sechzigjähriger Mensch sich nicht an jeden Tag seines Lebens erinnern kann.Wahrscheinlich wird er sich aber an Erlebnisse und Ereignisse, die emotional eingefärbt sind, erinnern. Neuronale Netze, die emotional durch Gefühle eingefärbt sind, haben eine hohe Überlebensdauer ! Das implizite (Bild)Gedächtnis arbeitet auf dieser Grundlage.Vor einiger Zeit war ich an einem Ort, wo ich vor 50 Jahren als Kind mit meinen Eltern Urlaub gemacht habe.Bilder,Gefühle, Gedanken von damals wurden bis im Datail wieder reaktiviert.Dieses implizite Gedächtnis spricht auf Bilder an.Erkennt es ein Bild (Ort) wieder, so ruft es emotional eingefärbte Sinneseindrücke, Gefühle und Gedanken von damals die mit diesem Ort assoziiert wurden, ab , was evolutionär gesehen einen Sinn ergibt. Anders scheint mir das explizite Wissens-Gedächtnis zu arbeiten.Neues Wissen= neue synaptische Verbindungen. Gemäß der Hebbschen Regel verkümmern alte neuronale Verbindungen wenn sie nicht mehr benötigt werden also nicht mehr gemeinsam feuern.
@Golzower. Sie haben natürlich recht, dass nicht alle neuronalen Verbindungen bestehen bleiben.
Da unsere Erfahrungen aber mit Hilfe eines neuronalen Netzwerkes gespeichert werden, stört es nicht, wenn einzelne Neuronen nicht mehr beteiligt sind.
Unser Gehirn ist dazu da, unser Überleben zu ermöglichen. Ob wir uns richtig oder falsch erinnern, spielt in vielen Fällen keinerlei Rolle [Buchtipp: Julia Shaw, Das trügerische Gedächtnis – Wie unser Gehirn Erinnerungen fälscht]
@KRichard: “Unser Gehirn ist dazu da, unser Überleben zu ermöglichen. Ob wir uns richtig oder falsch erinnern, spielt in vielen Fällen keinerlei Rolle.”
Jaromir: Da haben Sie recht. Unsere Erinnerungen werden ja im Laufe des Lebens ständig durch neue Erfahrungen und Erlebnisse “vergewaltigt”. Es gibt wohl keine 1:1-Erinnerung zum Erlebten. Wir sind Meister darin, schnell und richtig Schlüsse zu ziehen, keine Gedächtnis-Meister wie der Computer. Nur so konnten unsere Vorfahren überleben: Ein Hauch Gefahr reichte, um davon zu laufen: Man musste nicht den ganzen Säbelzahntiger sehen, der Anblick seiner Säbelzähne reichte vollkommen, um sich sofort davonzumachen. 🙂
Zitat Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: Angehörige
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Zitat Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: https://www.jocelyne-lopez.de/sprachen/angehoerige.html
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Zitat Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe (bitte auf dem Link unter meinem Name in diesem Beitrag klicken)
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: Angehörige
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: Angehörige
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Jocelyne Lopez
Zitat Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: Angehörige
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
Jaromir Konecny weist darauf hin, dass AI-Programme inzwischen in verschiedenen Bereichen – inzwischen auch in Bezug auf die Sprachkompetenz – superhumane Leistungen vollbringen, also besser abschneiden als der menschliche Durchschnitt.
Tatsächlich haben AI-Programme immer noch nicht auch nur die allgemeine Intelligenz eines Kindes, sie können aber auf Domänen, in denen ihre Leistung durch eine Armada von Forschern und Trainingsprogrammen immer weiter gesteigert wurde, leistungsmässig den Durchschnittsmenschen weit übertreffen.
Ich behaupte: Genau diese superhumanen Fähigkeiten auf bestimmten Einsatzgebieten bedeutet, dass künstliche Intelligenz immer häufiger von immer mehr Leuten eingesetzt wird, denn aus Sicht von Ökonomien, die sich gegenseitig vor allem in Bezug auf die Qualität der Produkte konkurrenzieren (ein Luxusauto kostet sehr viel mehr als ein gewöhnliches und bringt auch eine grössere Marge), bedeutet eine Überlegenheit eines Menschen oder Programms in einem bestimmten wichtigen Gebiet, dass man für diese Fachperson oder dieses Programm sehr viel zahlt, dass man diese Person oder dieses Programm einsetzen will und nicht ohne sie auszukommen meint. Sprachliche AI-Software wird also irgendwann die ultimative Korrektursoftware sein oder wichtige Briefe und Dokumente stilistisch aufbessern oder gar selber schreiben. Aufgrund der Logik unserer Konkurrenzgesellschaft ist nichts anderes zu erwarten.
@ Jaromir Konecny: „Der Linguist Noah Chomsky glaubt, die Sprache sei vor etwa 50.000 Jahren durch eine kleine Mutation entstanden. Doch das sehen die meisten Evolutionsforscher anders. Auch andere Beobachtungen bestätigen, dass die Sprache nicht plötzlich durch Zufall entstanden ist: In Pavianrufen haben Forscher zum Beispiel fünf menschliche Laute gefunden. Der letzte gemeinsame Vorfahre von Mensch und Pavian lebte vor etwa 25 Millionen Jahren und konnte wohl sprachähnliche Laute ausstoßen. Auch das deutet daraufhin, dass die Sprache das Ergebnis eines langen Evolutionsprozesses ist.“
.
Dass nichtmenschliche Primaten nicht sprechen können, liegt wohl an physiologische Gegebenheiten im Bereich der Stimmbänder, denn es ist inzwischen nachgewiesen, dass sie die kognitiven Fähigkeiten haben, es zu tun: Ich verweise zum Beispiel auf die Forschung des Verhaltensforschers Prof. Roger Fouts, der 30 Jahre seines Lebens damit verbracht hat, Schimpansen die Gebärdensprache der Taubstummen beizubringen und das populärwissenschaftliche Buch „Unsere nächsten Verwandten – Von Schimpansen lernen, was es heißt, ein Mensch zu sein“ darüber geschrieben hat, das ich in meiner privaten Homepage vorgestellt habe: Angehörige
Die Tiere zeigen erstaunliche Fähigkeiten für Grammatik, Syntax, Satzaufbau, sowie zum Verständnis von abstrakten Begriffen. Sie sind sogar fähig zu eigenen Wortschöpfungen, wie zum Beispiel „Wasservogel“ für Ente oder „heißer Rauch“ für Zigarette. Sie unterhalten sich sogar unter sich in der Gebärdensprache und bringen sie dem Nachwuchs bei.
“Das trügerische Gedächtnis- Wie unser Gehirn Erinnerungen fälscht..”
Ist das nicht ein Beweis für die Hebbsche Regel ?! :Neuronale Netze, die über lange Zeit nicht mehr benötigt werden, verblassen. Es bleiben in der verblassenden Erinnerung nur noch einige gedankliche und emotionale Versatzstücke/Segmente. Da die Geschichte aber noch emotional nachwirkt, versucht das Gehirn bzw. unsere Bewertungssystem aus diesen “Segmenten” die damalige Story zu nachzuempfinden. Hierbei wird die Einbildung/Phantasie zur Hilfe genommen. Die Erinnerungen werden also nicht durch das Gehirn an sich gefälscht sondern durch die Art der Bewertung. So fließen bei der Bewertung neuere Erkenntnisse zur Lückenfüllung mit ein. Der Begriff “Wie unser Gehirn Erinnerungen fälscht” erinnert mich hier an eine eher esoterische und übersinnliche Sicht auf die neuronalen Abläufe.
Das Gehirn(die Amygdala) arbeitet betreffs der Gefahrenabwehr nach dem Ähnlichkeitsprinzip.Dieses kann manchmal trügerisch sein, wenn es den entfernt liegenden Stock mit einer Schlange verwechselt. Aber lieber diese trügerische Verwechslung als ein tötlicher Biss…
@Golzower
Das Erzeugen von falschen Erinnerungen ist im Experiment vielfach gelungen. Ebenso ist der Nachweis gelungen – anhand vorliegender Fakten – dass sich Menschen beim Erinnern sehr oft irren.
Die Arbeitsweise unsere Gehirns ist sehr fehlerhaft – ob alte oder neue Erfahrungen verarbeitet werden it dabei egal.
Bezüglich des Englisch-Chinesisch Übersetzers von Microsoft.
Vielen Dank für den Hinweis im Kommentar. Als jemand, der beider Sprachen mächtig ist, konnte ich der Versuchung nicht widerstehen das Ding mal selber auszuprobieren und ich bin beeindruckt… in Maßen.
Auf dem Microsoft Blog verlinken sie auf eine Testversion des Programms. Leider übersetzt diese Version nur in eine Richtung, aus dem Chinesischen ins Englische, weshalb der Hin-und-her Trick leider nicht möglich ist. Interessanterweise spuckt es nach jeder Eingabe zwei Versionen heraus: Eine “Forschungsversion” womit wahrscheinlich Entwicklungsversion gemeint sein soll und eine “Produktionsversion”, was wahrscheinlich das ist was später vermarktet werden soll.
Als Eingabetext habe ich einen Artikel aus der New York Times China verwendet, die gerade bei einem Übersetzungsvergleich den unschlagbaren Vorteil bietet, dass man sich die dort publizierten Artikel parallel auf Englisch und Chinesisch darstellen lassen kann.
Was man vorerst vermerken kann: Beide Versionen produzieren verständliche flüssige Texte, die den Sinn des Textes mehr oder weniger abbilden. Das ist eine Leistung. Allerdings haben beide Versionen auch ihre ihnen eigene Maken und Fehler.
Die Entwicklungsversion ist die eindeutig fehlerbehaftete. Ihre Übersetzungen sind weniger wörtlich und sie tendiert dazu, an Knackstellen im Text Synonyme anzuwenden, die wohl dem Ausdruck eines Muttersprachlers näher kommen soll. Auffällig ist, dass das Programm (oder das Netzwerk dahinter) es manchmal schafft, genau die Wortwahl zu treffen, die auch die Englische NYT Version benutzt, wenn sie sich von der Chinesischen Version sprachlich freimacht. Aber eher häufiger passiert es, dass sie sich bei der Wortwahl schlichtweg vergreift, was zu amüsanten Stilblüten führt.
Eine Schwäche der Entwicklungsversion ist, dass sie nicht mit Zitaten umgehen kann, obwohl diese im Chinesischen Text eindeutig mit den entsprechenden “Gänsefüßchen” markiert sind. Dies führt zu eindeutigen Zuweisungsfehlern bei der im Satz Subjekt und Objekt verwechselt werden. Manchmal wird sogar derjenige, der zitiert als Subjekt in sein eigenes Zitat eingebaut, obwohl der Zitierer gar nicht von sich selber spricht. Gerade in einem höchst politischen Artikel (Trump wird im eigenen Land nach seinem Putin-Treffen als Verräter beschimpft) macht sich das schmerzhaft bemerkbar.
Was der Entwicklungsversion jedoch erstaunlich gut gelingt ist die korrekte Transkribierung Englischer Namen aus dem Chinesischen heraus. Das ist gar nicht so trivial, denn phonetisch handelt es sich bei den Piktogrammen im Chinesischen immer um Silben, die in ihrer Anzahl beschränkt sind, was natürlich tonal längst nicht dieselbe Kombinierungsfreiheit erlaubt wie diskrete Buchstaben. Ganz abgesehen natürlich davon, dass die im chinesisch existierenden Silben sich phonetisch längst nicht mit den Buchstabenlauten “westlicher” Sprachen deckt. Man denke nur an den Witz des Chinesen, der zum Bäcker geht und mit zwei Blondinen rauskommt – zwei Blötchen bitte…
Es gibt im Chinesichen (und Japanischen) keinen r-Laut, auch wenn der Buchstabe bei der Transliteration (Pinyin) durchaus verwendet wird.
Lustigerweise macht die Produktversion bei der Transkribierung Englischer Namen genau die Arten von Fehler, die ich erwarten würde, auch wenn sie sonst die korrekteren (wenn auch sprachlich etwas steifen) Texte liefert.
Beispiel: Aus Senator John McCain
– macht die Produktversion “Senator Joseph Mckain”
– die Entwicklungsversion Sen. John McCain
Den Unterschied hier fand ich ganz besonders interessant. Zuerst einmal die Produktversion. “Joseph” scheint erstmal ein Fehler, wäre da nicht die Tatsache dass der chinesische Ursprungstext selber den Vornamen als 约瑟夫 angibt. Wie oben erwähnt, jedes Schriftzeichen ist exakt eine Silbe. Einen Namen wie Joseph transkribiert der Chinese als ‘yuē sè fū’. Strikt gesprochen sind Joseph nur zwei Silben, aber da nimmt man es leider nicht so genau. Was aber sicher ist, ist dass drei Schriftzeichen im Vornamen niemals ‘John’ ergeben kann, solange man sich den Vornamen als isolierte Information betrachtet. Die Entwicklungsversion hat das aber genau korrekt erkannt. Was mich jedoch richtig argwöhnisch machte, ist dass sie Senator als Sen. abkürzte. Der NYT Artikel in der Englischen Version verwendet exakt dieselbe Abbkürzung, was mich an der Stelle doch stutzig macht. Zugegeben, ich lese US-Zeitungen nicht so häufig, als das ich beurteilen kann, ob Sen. als Abkürzung ubiquitär verwendet wird, aber zumindest im Chinesischen Ausgangstext steht Senator als voller Begriff. Um genau zu sein muss sogar angemerkt werden, dass Abkürzungen, so wie sie in Buchstabensprachen häufig verwendet werden im Chinesischen aufgrund seiner Konstruktion linguistisch eins zu eins gar nicht möglich sind.
Ich bekomme bei dem Direktvergleich den Eindruck, dass beide Versionen auf einer gewissen Ebene recht unterschiedlich arbeiten, aber ich kenne mich zu wenig mit der Thematik aus, um das ordentlich in Worte fassen zu können. Ich hoffe, diese Kostprobe eines Stresstests ist halbwegs hilfreich und vielleicht versetze ich dem Microsoft Programm bei der nächsten Gelegenheit einer wahren Belastungsprobe, indem ich Chinesische Idiome, sogenannte 成语(chéngyǔ) verwende, die linguistisch und sprachkulturell eine ziemliche Sonderstellungs einnehmen.
Xiaolei Mu: “Bezüglich des Englisch-Chinesisch Übersetzers von Microsoft. … Es gibt im Chinesichen (und Japanischen) keinen r-Laut, auch wenn der Buchstabe bei der Transliteration (Pinyin) durchaus verwendet wird.”
Jaromir: Danke für den ausführlichen und ansprechenden Kommentar! Sehr interessant Ihre Erfahrung damit.
Über das fehlende “r” im Chinesischen habe ich schon mal eine Geschichte geschrieben. Die habe ich sogar in meinem letzten Roman “Die unglaublichen Abenteuer des Migranten Nemec” verwendet: Als Tscheche führe ich dabei einen “Sprachkampf” mit einer Chinesin durch: Sie will von mir, dass ich Wörter mit vielen Umlauten ausspreche wie “Kühlflüssigkeitsüberlaufbehälter” – ein Horror für einen Slaven. 🙂 Und ich verlange, dass sie “Rhabarbermarmelade” sagt. 🙂
Liest sich gut, zum “Machine-Learning” und hierzu ein kleiner Kommentar :
Die Deutschen haben massiv abgebaut in den letzten Jahrzehnten, damals konnten auch “einfache Leute” noch anspruchsvolle Korrespondenz, Briefe und so, verfassen, heutzutage herrscht sozusagen der funktionale Analphabetismus.
Die “Maschine” kann nicht die Welt verstehen, daran hapern auch Übersetzungsarbeiten.
MFG
Dr. Webbaer
Dr. Webbaer: “Liest sich gut, zum “Machine-Learning” …”
Jaromir: Danke für den Zuspruch! Der freut.
Dr. Webbaer: “Die Deutschen haben massiv abgebaut in den letzten Jahrzehnten, damals konnten auch “einfache Leute” noch anspruchsvolle Korrespondenz, Briefe und so, verfassen, heutzutage herrscht sozusagen der funktionale Analphabetismus.”
Jaromir: Das sehe ich genauso. Aber nicht nur die Deutschen haben abgebaut, die Tschechen auch: 😉 Im Sozialismus haben Bauarbeiter und Taxifahrer Dostojewski und Kafka gelesen. Heute nicht mehr. Mädchen lesen zum Glück noch, Jungs aber nicht. Beim Lesen setzt sich das Gehirn nun mal viel mehr mit dem Stoff auseinander, als wenn man nur Filme oder Serien “konsumiert”. Beim Filmegucken muss man ja nicht einmal die Bilder im Kopf selbst erzeugen. Hin und wieder zu überlegen, was mir der Autor sagen will, ist beim Fernsehen auch nicht mehr gegeben.
KRichard
“Dass sich Menschen sehr oft irren…”
Was nicht abzustreiten ist. Menschen erkennen und begreifen die Welt durch LERNEN. Je mehr ich lerne, um so mehr erkenne ich das mein EGO eigentlich ein Irrtum ist. EGO als Extrakt all meiner Erfahrungen und Glaubensmuster.Die Menschen irren sich auf Grund der Glaubens-und Verhaltensmuster, die sie selbst formen oder durch die Gesellschaft vorgeformt bekommen. In der DDR irrten sich die nahmhaften Wissenschaftler, die den Sieg des Sozialismus über den Kapitalismus propagierten.Heute irrt man sich ähnlich, aber niemand gibt diesen Irrtum zu, da man ihn noch nicht erkennt hat bzw. dieses gegenwärtige System für alternativlos hält. Wir irren uns- wenn sie so wollen- durchs Leben .Letzteres können sie aber nicht dem Gehirn vorwerfen, sondern der ewigen subjektiven Sinnsuche der Menschen.
Weil dies niemand sicher weiß, kann Dr. Webbaer auch hier solid erklären :
Die Sprache hat sich aus elementarer Notwendigkeit entwickelt und mit dieser Aussage sind erst einmal der Durst und der Hunger gemeint.
Daneben die Gefahr, die sinnhafterweise spezifiziert worden ist, “Bären” bspw. waren stets eine.
‘Bären’ wie ‘Barbaren’ (ebenfalls, metaphorisch gesprochen : “Brumm, brumm”) haben bei der sprachlichen Spezifikation, die oft lautmalerisch war, sicherlich ebenfalls geholfen.
Nun stellt sich natürlich die Frage, warum ausgerechnet der hier gemeinte Primat sinhhafterweise Sprachlichkeit entwickelt hat, und nicht etwa andere, bspw. auch Bären nicht.
Wenn das Wort der “Anfang” war, Dr. W hegt hier keinerlei Zweifel, zitiert gerne das dbzgl. großartige Intro des Johannesevangeliums, stellt sich die Frage, woher der Sinn kommt, die Vernunft oder Ratio.
Stanley Kubrick war so frei so vorzuschlagen, andere bemühen einen Gott und wieder andere die sog. Panspermie.
Ansonsten gibt es noch vglw. “trockene” Denker, die meinen, dass etwas ist oder sein kann, weil es ist.
Weil ansonsten sich die Fragen nicht stellten.
Dieser Ansatz ist sicherlich ursisch, zynisch, aber wurde auch von Fichte vertreten.
MFG
Dr. Webbaer
Dr. Webbaer: “Nun stellt sich natürlich die Frage, warum ausgerechnet der hier gemeinte Primat sinhhafterweise Sprachlichkeit entwickelt hat, und nicht etwa andere, bspw. auch Bären nicht.”
Jaromir: Eigentlich hat die Evolutionstheorie ganz vernünftige Erklärungen für das Entstehen des abstrakten Denkens und der Sprache bei Homo Sapiens: Der aufrechte Gang und energiereiche Nahrung. Der aufrechte Gang entstand wohl, weil die Gattung Homo dadurch einen evolutionären Vorteil beim Früchtepflücken bekam. Dadurch konnte unserem Körper viel energiereiche Nahrung zugeführt werden, die für die Entwicklung unseres Gehirns notwendig war. Außerdem kam das Feuer dazu, mit dem unsere Vorfahren ihre Nahrung viel energiereicher machen konnten.
Ich erinnere mich an eine Studie über 300 Affenarten, die man in drei Gruppen aufgeteilt hat: Früchtefresser, Grasfresser und Allesfresser. Die Früchtefresser haben auch das “gewichtet” größte Gehirn – hier hat es eine starke Korrelation gegeben. Deswegen war die energiereiche Nahrung wohl viel wichtiger für die Entstehung unseres Denkens als das soziale Leben in großen Gruppen. Hier gab’s bei den Affen keine Korrelation “Sozialität – großes Gehirn”. Ameisen und Bienen sind ja auch ganz schön sozial. 🙂
Dr. Webbaer: “Die Sprache hat sich aus elementarer Notwendigkeit entwickelt und mit dieser Aussage sind erst einmal der Durst und der Hunger gemeint.”
Jaromir: Hunger und Durst haben alle Arten. Doch den aufrechten Gang hat nur Homo Sapiens und seine Vorfahren entwickelt. So wird der aufrechte Gang wohl auch am Anfang der Sprache stehen: Die Hände waren befreit und konnten gestikulieren, aus der Kombination der Gestik und der Nachahmung der Umweltgeräusche konnte sich dann die Sprache entwickeln.
Wie wichtig Gestik und Motorik für unser Denken sind, zeigen unzählige Studien in der neuen Hirnforschung. Auch “adulte Neurogenese” gehört dazu: Durch Bewegung und vor allem komplexe Bewegungen wie Tanzen oder Jonglieren kann man auch im Erwachsenen Alter den Hippocampus entwickeln, der wiederum schlüsselhaft ist fürs Lernen und Gedächtnis.
@ Kommentatorenkollege ‘Golzower’ :
Der Mensch irrt in seinen Einschätzungen auf die Natur bezogen, nicht im tautologischen Sinne, hier ist bspw. die Mathematik gemeint, die zumindest eine Chance hat absolut ‘wahr’ zu sein, fortlaufend.
Er betreibt nicht Wissenschaft, denn er weiß ja nichts (abschließend), sondern er sucht Erkenntnis (“Scientia”), ist dabei recht gut und kam u.a. zum Skeptizismus und zur szientifischen Methode, die sich nicht um ‘Wahrheit’ kümmert, sondern um Erkenntnis.
Es mangelt hier an d-sprachigem Eintrag in der bekannten Online-Enzyklopädie, wie auch in anderen Sprachen, denn der Naturwissenschaftler würde schon gerne von Wissen sprechen und schreiben, statt von provisorischer Theorie mit (unbekanntem) Verfallsdatum, auch wenn dies richtig wäre.
Vgl. auch mit diesem Interview mit “Frenemy” Rahmstorf :
-> http://www.pik-potsdam.de/~stefan/mare-interview.html
MFG
Dr. Webbaer (der allerdings vergleichsweise sicher ist, dass die Aufklärung, im Kern das Sapere-Aude, durch liberale Gesellschaftssysteme vertreten wird und nicht durch sozialistische, im Sinne von Rousseau und anderen im Bereich der franz. Linie der Aukflärung)
Den ‘aufrechten Gang’ gab es schon bei den Dinosauerien, lieber Herr Konecny, und die waren recht stark und hier wird Dr. W auch ein wenig steif, womöglich ungünstig, Ihr Kommentatorenfreund (sofern er sich so bezeichnen darf, Sie scheinen ja sehr nett zu sein und Dr. W ist dies ebenso, versucht dies zu sein, zumindest), also hier kann im Moment nicht zugestimmt werden.
Die Not könnte es gewesen sein, die einige zur Sprache gebracht hat. [1]
MFG
Dr. Webbaer
[1]
Wobei die Panspermie und der Kubricksche dbzgl. Ansatz für einige gar nicht schlecht klingen, Dr. W bleibt abär gerne bei Fichte, der sich zu dieser Sicht durchgerungen hat : ‘Etwas ist, weil es so ist, und es ist so, wie es ist, weil es so ist.’
(Opi W lässt sich abär gerne auch anderweitig beraten, gar religiös, also wenn Sie womöglich dbzgl. etwas auf dem Lager haben?! – Dr. W konnte sich allerdings nie so, im Sinne von “Muss ich haben, hier und jetzt!” bspw. jüdischer Sicht anschließen, die die Welt als gotterfahren vor ca. sechs Tausend Jahren gebootet sieht, gar mit eingegrabenen Fossilien, um so nachfolgende Wissenschaftler zu täuschen; ansonsten ist es ihm abär schon so, dass es merkwürdig ist, dass die Welt mehrere Milliarden Jahre existiert und erst vor wenigen Jahrtausend Jahren Erkenntnis hervorkam; vielleicht wissen Sie mehr?!)
Dr. Webbauer: “Den ‘aufrechten Gang’ gab es schon bei den Dinosauerien, lieber Herr Konecny, und die waren recht stark und hier wird Dr. W auch ein wenig steif, womöglich ungünstig, Ihr Kommentatorenfreund (sofern er sich so bezeichnen darf, Sie scheinen ja sehr nett zu sein und Dr. W ist dies ebenso, versucht dies zu sein, zumindest), also hier kann im Moment nicht zugestimmt werden.
Die Not könnte es gewesen sein, die einige zur Sprache gebracht hat.”
Jaromir: Lieber Herr Dr. Webbauer, auch wenn der aufrechte Gang und somit die Befreiung der Hände eine sehr gute Voraussetzung oder sogar notwendige Bedingung liefert, abstraktes Denken und Sprache zu entwickeln, heißt es noch lange nicht, dass Zweibeiner notwendigerweise abstraktes Denken entwickeln. Sonst wären ja Laufvögel wie der Vogel Strauß oder Kängurus auch intelligent. Wie oben gesagt, bringt energiereiche Nahrung, wie Früchte aber auch durch Feuer zubereitete Nahrung, einen zusätzlichen Evolutionsvorteil für die Entwicklung des Gehirns. Unser Gehirn verbraucht etwa ein Viertel der Energie, die wir uns in Form von Nahrung zuführen. Schon das Gehirn anderer Primaten bedient sich nur etwa eines Zehntels des gesamten Energiebedarfs.
Wohl waren viele Dinosaurier “intelligenter” als z. B. die heutigen Vögel, und es kann ja sein, dass manche von ihnen im Laufe der weiteren Evolution noch intelligenter werden würden, wenn eine globale Katastrophe sie nicht ausgelöscht hätte. Unsere Arme und Hände haben sich ja auch etwa 10 Millionen Jahre lang an sehr komplexen Aufgaben entwickelt, bis Homo Sapiens auch dank ihnen Sprache entwickeln konnte. Die Klauen der Dinos scheinen eher verkümmert gewesen zu sein. Die Fleischfressenden Dinos haben wohl ihre Opfer mit ihren riesigen Kiefern gepackt und zermalmt, nicht ihre Klauen benutzt, um Beute zu machen. Sicher hat T. Rex sich mit Hilfe seiner Klauen keinen Steak grillen können. 🙂
Liebe Grüße
Jaromir
Dr. Webbaer: “Wobei die Panspermie und der Kubricksche dbzgl. Ansatz für einige gar nicht schlecht klingen, Dr. W bleibt abär gerne bei Fichte, der sich zu dieser Sicht durchgerungen hat : ‘Etwas ist, weil es so ist, und es ist so, wie es ist, weil es so ist.’ (Opi W lässt sich abär gerne auch anderweitig beraten, gar religiös, also wenn Sie womöglich dbzgl. etwas auf dem Lager haben?! – Dr. W konnte sich allerdings nie so, im Sinne von “Muss ich haben, hier und jetzt!” bspw. jüdischer Sicht anschließen, die die Welt als gotterfahren vor ca. sechs Tausend Jahren gebootet sieht, gar mit eingegrabenen Fossilien, um so nachfolgende Wissenschaftler zu täuschen; ansonsten ist es ihm abär schon so, dass es merkwürdig ist, dass die Welt mehrere Milliarden Jahre existiert und erst vor wenigen Jahrtausend Jahren Erkenntnis hervorkam; vielleicht wissen Sie mehr?!)”
Jaromir: Panspermie ist ja nur die Überlagerung des Problems. Die Evolutionsforschung erklärt immer besser die Entstehung des Lebens auf der Erde, des abstrakten Denkens und der Sprache. Auch immer mehr “Missing Links” werden ausgegraben. Meiner Meinung nach muss man hier keine zusätzlichen Annahmen machen, die am Ende nichts erklären.
Ich war früher sehr überrascht, als einer meiner “Kultwissenschaftler” Francis Crick gesagt hatte, dass Bakterien auf die Erde aus dem Weltall gekommen seien. Seine Frau kommentierte das damals mit – wenn ich mich richtig erinnere: Er sei verrückt. 🙂 Dabei hat Crick mit Watson die Struktur der DNA entdeckt und maßgeblich zu der Entschlüsselung des genetischen Codes beigetragen, hat sich also mit der “molekularen Evolution” gut ausgekannt.
Liest sich hier gut, lieber Herr Konecny, vielen Dank noch für Ihre Ergänzungen im Kommentariat, für Ihre Kompetitivität, ja, Sie wissen zu argumentieren, es spricht nun auch naturwissenschaftlich einiges für den hier gemeinten Affen zur Krönung der Schöpfung geworden zu sein, da stimmten sozusagen die Voraussetzungen, auch wenn er evolutionsgeschichtlich recht spät kam.
I.p. Sprachlernfähigkeit von Gerät ist Dr. W im Vergleich zu Ihnen und zu Linguisten, die hier bei den scilogs.de publizieren, deutlich pessimistischer, musste sich allerdings korrigieren lassen, denn die sog. neuronalen Netzwerke nehmen auch das Fehlen, den Misserfolg, in Kauf und leisten deutlich besser als hier erahnt.
Herauskommen kann aus seiner Sicht aber letztlich nur andere Sprachlichkeit, nicht humane.
MFG + weiterhin viel Erfolg + danke!
Dr. Webbaer (der die Dinos womöglich ein wenig überschätzt hat, auch die Eierlegerei spricht nicht unbedingt für günstige Weiterentwicklung der Gen-Datenhaltung)
Superhumane Leistungen werden AI unersetzlich in gewissen Gebieten machen. Ein solches Gebiet ist gemäss How Artificial Intelligence Can Supercharge the Search for New Particles die Teilchenphysik. Die Technik um neue Partikel zu finden nennt sich (übersetzt von google translate): “Bump Hunting”, die klassische Partikel-Jagd-Technik, die das Higgs-Boson gefunden hat. Die allgemeine Idee, nach einem der Autoren, Ben Nachman, ein Forscher am Lawrence Berkeley National Laboratory, ist es, die Maschine zu trainieren, seltene Variationen in einem Datensatz zu suchen.
..
Der vorgeschlagene CWoLa-Algorithmus, der für “Klassifizierung ohne Labels” steht, kann vorhandene Daten nach unbekannten Partikeln suchen, die entweder in zwei leichtere unbekannte Partikel desselben Typs oder zwei bekannte Partikel desselben oder eines anderen Typs zerfallen. Mit normalen Suchmethoden würden die LHC-Kollaborationen mindestens 20 Jahre brauchen, um die Möglichkeiten für letztere zu durchsuchen, und für die ersteren gibt es keine Suche. Nachman, der am ATLAS-Projekt arbeitet, sagt, dass CWoLa sie alle auf einmal erledigen könnte.
Zur natürlichen Intelligenz: In vielen Tierstammbäumen haben evolutiv spätere Formen sogar kleinere Hirne als evolutiv frühere. Erst bei den Primaten zeigt sich eine Entwicklung zu immer grösseren Hirnen. Warum? Wohl, weil Planung und Werkzeugbau aus einem spezialisierten Primaten, der in den Bäumen vorwiegend von Früchten lebte, eine Allrounder machte, der nun bei der Jagd darauf spezialisierten Raubtieren Konkurrenz machen konnte (schon früh wurden ganze Tierherden von Prähominiden in eine Hinterhalt getrieben und dann getötet) und der seine Umgebung zu seinen Gunsten umformen konnte, zumal zum grossen Gehirn noch die freien Arme und Hände kamen, die er für alles mögliche einsetzen konnte. Der Mensch zeichnet sich letztlich durch eine hohe allgemeine Intelligenz aus, während etwa Raubvögel ein auf das Erkennen und Jagen von Beutetieren spezialisiertes Hirn (und entsprechende Sinnesorgane) haben.
Mit anderen Worten: AGI (artificial general intelligence) ist der Schlüssel zur menschenähnlichen Intelligenz von Robotern.
@Konecny
Was gibt es über die Bedeutung an sich, die hinter Zeichen/Wörter/Sprache liegen, zu sagen? Ist das Information oder ist die Bedeutung an sich eine Entität? Wie sind Zeichen/Sprache und Bedeutung verknüpft? Welche Stellenwert nimmt die Bedeutung im Bewusstsein ein? Manchmal macht es mir mehr den Eindruck, Noam Chomsky`s Theroie/Idee der Universalgrammatik ist eine der Bedeutungen?
Die Evolution ist ein äußerst komplexer Vorgang, wenn sie auf komplexe Spezies wirkt. Eine Beschleunigung erfährt sie immer durch Rückkopplungen der Effekte. Der Mensch war ursprünglich ein Baumbewohner, daher schon mit effektiven Handwerkzeugen ausgestattet, wie die heute lebenden Primaten. Durch den aufrechten Gang wurden sie frei für das Jagen und Zerlegen von Beute. Das wiederum förderte die Leistungen des Gehirns, sowohl durch die Nahrung als auch durch die vielseitige Betätigung der Hände und Finger. Entscheidend ist aber, dass der Mensch seine eigenen Hände und Finger bei ihren Bewegungen und Handlungen beobachten kann und so die Handlungen sofort korrigieren kann. Diese Form von Rückkopplung ist die Grundfunktion der Kybernetik und der Intelligenz.
Die menschliche Evolution ist eine Spirale der Entwicklungen, die ohne Zielsetzung funktioniert, sondern durch die gigantische Anzahl der Individuen und durch die unterschiedlichen Lebenswelten mit unterschiedlichen Möglichkeiten und Anforderungen in Gang gehalten wird. Dabei kann die Evolution auch Merkmale entwickeln, die für das Leben nicht zweckmäßig und nicht notwendig wären, die im Verlauf der Evolution aber neue Funktionen annehmen und erfüllen können.
Die Entwicklung der KI ist mit der Evolution des Gehirns in keiner Weise zu vergleichen. Die KI hat konkrete Zielsetzungen und kann nicht im entferntesten die Komplexität des Gehirns erreichen. Die KI kann aber natürlich einzelne spezifische Funktionen der Intelligenz hinsichtlich ihrer Zielsetzungen nachahmen. Auch eine Form von “robotischem Bewusstsein” ist nicht auszuschließen, wenn der Roboter eine umfassende Sensorik für seinen eigenen Zustand bekommt und bestimmte Bewertungen vornehmen kann, aus denen er eigene Zielsetzungen ableiten kann. Letztlich aber bleibt er immer ein Produkt des Menschen.
Ist jedenfalls merkwürdig, dass Sprache und insbesondere Schrift so spät kamen.
Also Erkenntnis.
Es hat unklar zu bleiben, ob die allgemeine Entwicklung, die Welt ist gemeint, ohne Ziel oder besonderem Anspruch des Weltbetriebs ist, jedenfalls philosophisch.
Die KI kann, sobald selbstständig, mit der ‘Evolution des Gehirns’ verglichen werden.
Ganz unvermessen (vgl. auch bspw. mit vermessener Aussage aus dem Hause Hawking) eingeschätzt, kann soz. Alles passieren.
Welten erschaffen Welten.
Der Mensch an sich kam spät! Aber diese Feststellung ist relativ und wissenschaftlich irrelevant. Zur Entstehung der Sprachfähigkeit, nicht der Sprache(!), gibt es verschiedene Theorien, wen wundert’s. An der Sprachfähigkeit ist nicht nur das Gehirn beteiligt, sondern besonders die komplizierten Apparate zum Hören und Sprechen mit anatomischen Grundbedingungen, die den sprachlichen Fähigkeiten des Gehirns mit Sicherheit vorausgingen. Mit der Sprachfähigkeit kam die Möglichkeit der sprachlichen und symbolischen Kommunikation, die wiederum das individuelle Bewusstsein und die Intelligenz beförderte.
Ein Merkmal des Menschen, im Gegensatz zum Roboter oder zur KI, ist die Kreativität, die sich hauptsächlich aus der Beobachtung der Umwelt ergibt, mit einem gigantischen Angebot an Information zur Erfassung und Auswertung. Verschiedene Menschen nehmen die Umwelt verschieden wahr und werten sie individuell aus. Vieles davon ist dem Zufall oder der Willkür überlassen. Das wäre ein No-go für die Robotik oder KI, zum Beispiel die Unfälle mit autonomen Fahrzeugen. Die meisten technischen Systeme brauchen allerdings nicht viel Intelligenz.
Es hätte sich im Sinne der Kommunikation auch (gerne : rhythmisch) angetastet werden können, auch komplexe Inhalte meinend (eigentlich, wie Dr. W findet : naheliegend), der Informationsgehalt muss hier nicht leiden, wenn beachtet wird, dass Vieles i.p. Sprache im Sinne von Claude E. Shannon und Warren Weaver [1] auch anders ginge, auch hätte das Hirn direkt selbst für die Zwecke der Kommunikation belangt werden können, geeignete Fühler vorausgesetzt, auch hätte es Lebewesen geben können, die über Strahlung verlautbaren (gibt es ja auch), und Kompetitivität, die zur Sprach- und Inhaltsbildung Genüge hätte tun können auch.
Der Mensch ist aus diesseitiger Sicht ein beispielhaft Leistender, aber – stets soz. auf der Hand liegend – ersetzbar.
Nichts gegen Nasentrockenaffen (“Trockennasenprimaten”) natürlich!
Insofern ist (vergleichsweise) alles zufällig,
MFG
Dr. Webbaer (der sich hier hauptsächlich über die spät erhaltene soziale Vernunft wundert, denn diese wäre auch dann eine gute Idee, für Lebewesen, wenn zuvörderst “vermampft” wird)
[1]
Das “Rauschen” sozusagen ging es rauszukriegen, was nie umfänglich gelang, natürlicherweise.
PS hierzu :
Der Mensch ist aus diesseitiger Sicht ein beispielhaft Leistender, aber – stets soz. auf der Hand liegend – ersetzbar.
War natürlich aus hier promovierter Sicht Blödsinn.
Nur -irgendwie- theoretisch richtich.
Göthes Spruch „Die Welt urteilt nach dem Scheine.“ gilt auch für die Beurteilung des Leseverständnisses von sprachverarbeitenden Computerprogrammen. So schliessen viele von der richtigen Beantwortung von Fragen zu einem gelesenen Text, dass der Computer den Text verstanden hat. Doch dieser Schluss ist meist ziemlich falsch. Vielmehr gilt, dass ein Programm, das mit Deep Learning trainiert wurde, die Millionen bis Milliarden Beispiele, die ihm verfüttert wurden, dazu nutzen kann, verblüffend “richtige” Antworten zu geben ohne überhaupt etwas von der Sache zu verstehen.
Der arxiv-Artikel R3: A Reading Comprehension Benchmark Requiring Reasoning
Processes* fordert, dass computerbasierte Fragen-Antwort-Systeme in der Lage sein sollten, den Schlussprozess angeben zu können mit dem sie zur Antwort auf eine Frage kommen. Begründet wird diese Forderung gerade damit, dass es sich gezeigt hat, dass auch Fragen-Antwort-Systeme genau so wie bildverarbeitende Systeme durch konstruierte Beispiel getäuscht werden können, so dass sie auf leicht abgewandelte Fragen plötzlich überhaupt keine sinnvolle Antwort mehr generieren oder umgekehrt auf unsinnige Fragen die “Goldlösung” präsentieren.
Der Artikel fordert für ein Computersystem, das Fragen beantwortet, die Denkschritte die zur Lösung führen in Form der Text Reasoning Meaning Representation angeben zu können. Zugehörig zum Artikel gehört eine ganze Datenbank von Texten als Test für ein System, welches begründete Antworten zu Fragen zu einem Text geben kann.
Antworten begründen können deckt sich auch gut mit der generellen Forderung an AI-Systeme, Erklärungen abgeben zu können. Ein intelligentes System sollte tatsächlich angeben können wie es zu einem bestimmten Ergebnis kommt, genauso wie das von einem menschlichen Experten erwartet wird. Es stimmt zwar, dass auch hier Fallstricke lauern: Nicht immer stimmt die Erklärung für ein Denkresultat mit dem wirklichen Denkprozess überein, denn der wirklich Denkprozess entzieht sich oft einer einfachen Erklärung.
Weiter bin ich beim Lesen nicht gekommen, sicher meinem fehlenden Verständnis geschuldet.