

Künstliche Intelligenz, Daten und die Medizin in Zeiten von Corona

Der Mensch ist kein Prophet
Anfang Februar hielt ich im Hofspielhaus zu München einen Vortrag über Künstliche Intelligenz (KI) in der Medizin. Dabei erwähnte ich das KI-Programm der kanadischen Plattform BlueDot, ein Modell aus künstlichen neuronalen Netzen (KNN), das die „Weltgesundheit“ überwacht: Schon in den frühen Stunden des 31.12.2019 hatte BlueDot über den Ausbruch eines grippeähnlichen Virus im Wuhan-Gebiet in China berichtet und die Weltöffentlichkeit vor Reisen dahin gewarnt. Ganze neun Tage vor den Warnungen vor dem neuartigen Coronavirus der Weltgesundheits-organisation (WHO) am 9.01.2020.

Bild von Jacqueline Macou auf Pixabay.
BluDot verarbeitet Millionen von Nachrichten, Daten über Tier-, Insekten- und Pflanzenkrankheiten, Flugkartenbestellungen, offizielle Verlautbarungen wie die der W.H.O und viele andere Daten im Internet, um vor Gefahrenzonen zu warnen: Welche Krankheiten drohen, sich in die Welt auszubreiten? Wo liegen die Brandherde, die nicht besucht werden sollen?
BlueDots Warnung vor COVID-19 war durch die Auswertung von auf Chinesisch geschriebenen Medienberichten über 27 Lungenentzündungsfälle motiviert, im Zusammenhang mit einem Markt mit Meeresfrüchten und lebenden Tieren in Wuhan-Gebiet. Aus Daten über den Verkauf von internationalen Flugkarten bestimmte BlueDot, wohin die Infizierten die Krankheit bringen könnten: Das größte Risiko für die weitere Verbreitung des neuen Corona-Virus trugen Bangkok, Hongkong, Tokio, Taipeh, Phuket, Seoul und Singapur. 11 der ersten Städte an der Spitze der BlueDot-Liste waren auch die ersten Orte, an denen COVID-19-Fälle aufgetreten sind.
Das war nicht der erste Erfolg, der BlueDot verbuchte. Bereits 2016 hatte das KI-Modell erfolgreich vorausgesagt, dass sich das Zika-Virus in Florida ausbreiten würde – sechs Monate vor dem Ausbruch. Auch die Ausbreitung des Ebola-Virus im Jahr 2014 aus Westafrika hatte BlueDot erkannt. Selbstverständlich arbeiten viele menschliche Experten und auch andere Technologien als KI daran, uns vor Epidemien zu warnen, sie zu verhindern, sie zu bekämpfen. Doch KI leistet jetzt auch einen Beitrag, und der ist nicht klein. Der Gründer der BlueDot-Plattform, der Epidemologe Dr. Kamran Khan, sagte:
„Auf keinen Fall würden wir behaupten, dass KI dieses Problem gelöst hat. Dies ist nur eines der Tools in der Toolbox. Wir verwenden künstliche Intelligenz nicht, um die menschliche Intelligenz zu ersetzen. Wir verwenden sie im Grunde genommen, um die Nadeln im Heuhaufen zu finden und sie unserem Team zur weiteren Untersuchung und Analyse vorzustellen.“
Bei meinem Vortrag im Hofspielhaus brachte ich die Meldung über BlueDot nur als ein Beispiel dafür, wie KI uns im Kampf gegen die Ausbreitung vor ansteckenden Krankheiten helfen kann. Niemand von uns im Theater erfasste jedoch die volle Bedeutung der BlueDot-Warnung: dass die damalige Wuhan-Wirklichkeit bald die Wirklichkeit der ganzen Welt werden würde.
„Bei einer weltweiten Epidemie kannst du nicht mehr auf der Bühne auftreten“, sagte mir eine Freundin kurz nach dem Vortrag. Damals lachte ich darüber. Doch nur ein paar Wochen später war ich aller meinen Veranstaltungen los: 40 Stück wurden mir von der Mitte März nur bis Ende Mai abgesagt.

Hätte ich das nicht ahnen müssen? Hätte ich die BlueDot-Meldung nicht ernster nehmen sollen? Jahrelang habe ich doch über die Entstehung des genetischen Codes geforscht und mich dabei ausgiebig mit RNA-Viren beschäftigt, zu denen Corona-Viren gehören. SARS-Cov-19 war ja schon damals auf seiner Welttour. Wer hat aber am Anfang Februar geahnt, in was sich die ganze Welt ab Mitte März wandeln würde?
Wieder mal zeigte sich: Der Mensch ist kein Prophet. Kein Mensch erfasst ein komplexes Problem, das von tausenden Faktoren abhängt wie das Klima oder eben die Ausbreitung einer Krankheit, um daraus Vorhersagen zu treffen. Auch kein „traditionelles regelbasiertes“ Computerprogramm kann ein solches komplexes Problem lösen. Weil wir nun mal nicht alle Regeln kennen, die das komplexe Problem vollständig beschreiben würden. Wir sind nicht in der Lage, ein solches Programm zu schreiben. Komplexe Probleme können nur von Programmen gelöst werden, die das selbst aus sehr vielen Beispielen lernen – aus Unmengen von Daten: Von künstlichen neuronalen Netzen (KNN), unserer heutigen Künstlichen Intelligenz.
Die Grenzen der KI
Doch sollten wir auch die Grenzen des Könnens unserer KI-Modelle beachten: KNN treffen umso bessere Entscheidungen, je mehr und je bessere Daten sie für ihr Training bekommen. AlphaGo und AlphaGo Zero haben Millionen Go-Spiele gespielt, bevor sie Go-Weltmeister schlagen konnten. Ein gutes KI-Bilderkennungsprogramm muss mit Hunderttausenden Bildern trainiert werden, um Äpfel von Birnen aber auch von Zitronen, Bananen, Erdbeeren und allen anderen Obstsorten zu unterscheiden, mit einigen Tausend Bildern für jede Klasse von Früchten. Wenn man genug Bilder hat, kann man in die Obstkiste auch Gemüse legen. Bei einem solchen Training lernt das Modell die Merkmale von jeder Sorte Obst und Gemüse kennen, deren Bilder es zu verarbeiten bekam und kann ab da jede Birne und jeden Rettich bestimmen, auch wenn die Birne wie ein Apfel aussieht und der Rettich wie eine Zuckerrübe.
Sowie der Mensch aber dank gutem unverdorbenen Essen gesund lebt, müssen KI-Programme mit „guten“ Daten trainiert werden, um richtig zu funktionieren: Beschädigte, verrauschte, mehrfach vorkommende u. a. mangelhafte medizinische Bilder werden aussortiert, wenn eine KI lernen soll, Tumorarten zu unterscheiden. Wenn der Datensatz (hier die Tumorbildersammlung) neutral ist, von guter Datenqualität und vollständig für das zu behandelnde Problem, liefern diese Modelle in der Testphase gute Ergebnisse, die dann mit Schlagzeilen gefeiert werden wie: Künstliche Intelligenz erkennt Tumore besser als Mediziner.
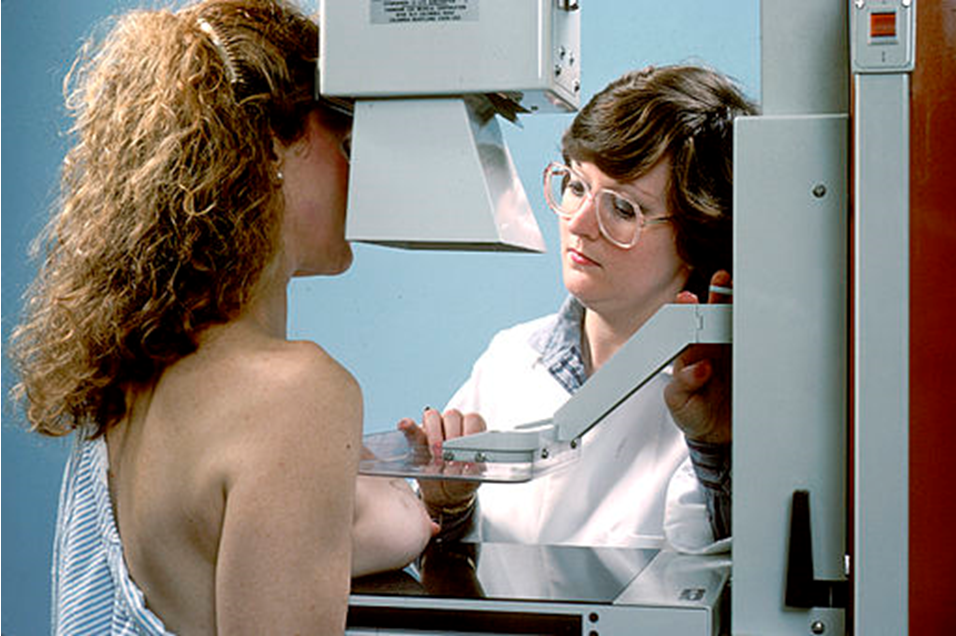
Mammographie: Googles Firma DeepMind trainierte ihr KNN-Modell mit 76.000 Mammographie-Aufnahmen aus Großbritannien und den USA. Das Modell erkannte bösartige Tumore auf den Aufnahmen besser als ein menschlicher Prüfer und genauso gut wie zwei menschliche Prüfer zusammen. Den Nature-Artikel zu der Studie gibt es hier. Bild: Wikimedia Commons. Autor Bill Branson.
Wenn aber gut trainierte KI-Programme in echten Krankenhäusern eingesetzt werden, kann plötzlich alles anders sein: Das Modell liefert Ergebnisse, welche die Ärzte zum Lachen bringen. Oder zum Weinen. Ein berühmtes Beispiel hierfür ist IBMs KI-Maschine Watson:
Mit Dr. Watson gegen Krebs
2011 hat Watson einen Sieg gegen Ken Jennings und Brad Rutter im amerikanischen Fernsehquiz Jeopardy errungen. Jennings und Rutter waren ausgewiesene Jeopardy-Champions. Bei diesem Quiz Menschen gegen Maschine gewann Watson 1 Million Dollar. Leider konnte sich die Maschine nichts dafür kaufen – IBM hat das Geld für gemeinnützige Zwecke gespendet. Ein Meilenstein der KI war das aber schon.

Bild: Wikimedia Commons. Autor: Atomic Taco.
So motiviert rüstete IBM Watson auf einen ultimativen Krebs-KI-Experten um, Watson for Onkology, der den Ärzten auch Empfehlungen für Krebstherapien geben sollte. Doch im realen Leben erwies sich Dr. Watson als Kurpfuscher. Einem Krebspatienten mit starken Blutungen empfahl die Maschine ein Medikament, dass die Blutungen verstärken würde. Watsons Kapriolen verführten einen Arzt an der Jupiter-Klinik in Florida zu einer poetischen Bemerkung: „This product is a piece of shit.”
Was ließ Watson scheitern? Watson war von den Ärzten des Memorial Sloan Kettering (MSK) Krebszentrums trainiert worden. Stat News konnte die zwischen den Ärzten und IBM ausgetauschten Dokumente einsehen. Danach hatten die MSK-Ärzte die Maschine mit vielen hypothetischen Krankheitsverläufen und künstlich erzeugten Falldaten gefüttert. Statt mit nur echten Patientendaten. Somit haben dann die behandelnden Ärzte in echten Krankenhäusern von Watson Behandlungsempfehlungen bekommen, die sich nach den Behandlungsmethoden des MSK-Ärzteteam orientierten. Nicht nach echten Patientengeschichten. Der Grund am Versagen von Watson waren also die schlechten Daten, mit denen die Maschine trainiert wurde.
Data is all you need
Doch auch ein richtig trainiertes KNN-Model kann versagen. Stellen wir uns vor, wir trainieren das Modell überwacht mit Tumor-Bildern von zwei verschiedenen Arten: Bösartig oder gutartig. Nach dem Training bestimmt das Modell während der Testphase immer richtig, ob es sich um einen bösartigen oder um einen gutartigen Tumor handelt. Ein Krankenhaus kauft das Modell, doch plötzlich liefert das Modell falsche Ergebnisse. Warum? Weil eben die Tumorbilder im Krankenhaus nicht eine solch gute Qualität haben wie die, an denen das Modell trainiert wurde. Oder etwas anders sind.
Eine Sammlung von Daten ist ein Datensatz. Bevor ein Datenwissenschaftler ein KI-Modell zu entwickeln anfängt, muss er den zu verarbeitenden Datensatz ordentlich erforschen: Wie wurden die Daten gesammelt? Wo zeigt der Datensatz Lücken? Wo sind die Fehler? Daten werden nicht im Labor gesammelt, sondern meistens in der realen Welt oder in der virtuellen des Internets und sehen dementsprechend aus: mangelhaft.
Vor kurzem zeigte Adama Geitgey in seinem Medium-Blog, wie die Verarbeitung von Corona-Epidemie-Daten zu Fehlern und falschen Folgerungen führen kann, wenn man sich keine großen Gedanken über diese Daten macht: „Sie wären überrascht, wie oft Leute in das Bauen der Modelle hüpfen, ohne sich die Daten angesehen zu haben.“ Ist eine solche Missachtung der Daten nicht absurd? Ein KNN ohne Rücksicht auf seine Trainingsdaten zu entwickeln, mutet genauso an, wie wenn ich Gulasch aus 5 Kilo Fleisch und 5 Kilo Zwiebeln in einem 2-Liter-Topf kochen möchte.
Die den Daten innenwohnende Muster hängen auch davon ab, wie die Daten gesammelt wurden. Adam Geitgey brachte ein Beispiel über die Anzahl der Covid-19-Verstorbenen in britischen Krankenhäusern. Diese Zahlen werden jeden Tag gemeldet, doch zeigen sie jeden Sonntag und Montag einen Rückgang. Was ist an diesen Tagen anders? Ändert sich da das Personal? Werden die Patienten an diesen Tagen anders versorgt oder behandelt?

Die pro Tag an Covid-19 Verstorbenen im Vereinigten Königreich von https://www.worldometers.info/coronavirus/country/uk/. Abdruck des Bildes mit freundlicher Genehmigung von Adam Gitgey.
Die Lösung des Rätsels liegt in der Art, wie die Anzahl der Toten gesammelt und gemeldet wird: Die meisten Krankenhäuser sind an Wochenenden nicht voll besetzt und können ihre Daten nicht rechtzeitig und perfekt melden. Diese langsame Berichterstattung führt über das Wochenende zu einem Rückgang und nach dem Wochenende zu einem entsprechenden Anstieg der Anzahle der Toten. Weil diese Zahl aber sowieso einen Tag verzögert gemeldet wird, beobachtet man diesen Rückgang am Sonntag und Montag anstatt am Samstag und Sonntag.
KI sagt schwere Covid-19-Verläufe voraus
Jeden Tag erfahren wir jetzt über neue Anwendungen der KI im Kampf gegen den Corona-Virus: KNN helfen Medikamente und Impfstoffe gegen Covid-19 zu finden. Die Modelle zeigen uns aber auch, wie die Krankheit sich ausbreitet. Mit ihrer Hilfe könnten wir vielleicht bestimmen, warum manche mit dem Corona-Virus infizierte Menschen gar keine Krankheitssymptome entwickeln, andere aber daran sterben. Schon jetzt wissen wir, dass eine Person ein umso größeres Risiko trägt, je älter die Person und männlich ist und je mehr Vorerkrankungen wie Herzerkrankungen und Diabetes sie aufweist. Sicher spielen genetische Faktoren eine Rolle. Sicher auch Umweltfaktoren wie das Rauchen, die eigene Krankheitsgeschichte. Kann auch sein, dass uns Ansteckungen mit anderen Coronaviren gegen SARS-Cov-2 etwas immunisiert haben. Diese Fragen können wir vielleicht bald mit Hilfe von KNN beantworten. Wenn sie mit richtigen Daten trainieren werden.
Nach einem Training mit Daten von nur 53 Covid-19-Patienten aus zwei chinesischen Krankenhäusern konnte ein KI-Modell der Universität New York mit 80 % Wahrscheinlichkeit richtig voraussagen, welche Coronavirus-Infizierte schwere Atemkrankheiten entwickeln würden, wie das akute Atemnotsyndrom (ARDS). Erstaunlicherweise waren für die KI-gestützte Bestimmung des schweren Verlaufs der Covid-19-Krankheit nicht bekannte Faktoren entscheidend, wie das Geschlecht, das Alter, bestimmte Muster in den Lungenscans, Fieber und eine strenge Immunantwort. Nur drei Faktoren waren für den schweren Verlauf der Krankheit entscheidend: die Überproduktion des Leber-Enzyms Alaninaminotransferase (ALT), das massiv in der Leber von Hepatitis-Patienten vorkommt. Weiter spielten eine Rolle Muskelschmerzen (Myalgie), die auf viele Entzündungen im Körper hinweisen, und eine erhöhte Menge von Hämoglobin. Hämoglobin transportiert Sauerstoff ins Gewebe und kommt auch bei Rauchern erhöht vor. Das zeigt, warum auch Raucher zu der Covid-19-Risikogruppe gehören.
Diese Faktoren können selbstverständlich von den oben erwähnten Faktoren abhängig sein wie das Alter, das Geschlecht und bestimmte Vorerkrankungen: Je mehr ein Patient zum Beispiel an Diabetes leidet, umso mehr Entzündungen gibt es in seinem Körper. Wenn KI-Programme auf diese Art Daten von viel mehr Patienten untersuchen könnten, würde man relativ sicher entscheiden können, welche Patienten man nach Hause schicken und welche im Krankenhaus bleiben sollten.
Ein Land wird hochgefahren
China hat als erstes Land den Kampf gegen das neuartige Coronavirus aufnehmen müssen. Auch deswegen bekam zuerst China die Epidemie in den Griff. Schon am Anfang März konnte der chinesische Lockdown gelockert werden. Die Forscher der chinesischen Bankgesellschaft WeBank untersuchten mit künstlichen neuronalen Netzen den Einfluss der Coronavirus-Epidemie auf die chinesische Wirtschaft. Grandios und recht kreativ dabei empfinde ich die dafür verwendeten Daten: Satelliten-Aufnahmen, z. B. Infrarot-Bilder der „Hotspots“ der Metallindustrie – je mehr der Ofen heizt, umso mehr Menschen sind in der Stahlhütte am Werk. Weiter wurden anonyme GPS-Daten der Arbeitspendler, und Aktivitäten in sozialen Netzwerken von dem KI-Modell ausgewertet. Alle Daten aus der Zeit vor dem Corona-Ausbruch, am Gipfel der Corona-Epidemie und danach.
Das KI-Modell zeigte, dass die chinesische Wirtschaft sich bereits am Anfang März zu 75 % erholt hatte. Aber auch andere interessante Erkenntnisse lieferte diese BigData-Analyse mit KI: Die Corona-Krise verursachte große Innovationen der Online-Welt: Die arbeitsbedingte Telekomunikation stieg während der Krise um 537 %, Online-Bildung um 169 %, das Online-Spielen um 124 %, Video-Streaming um 55 % und die Aktivitäten in den sozialen Netzwerken um 47 %. Das merke ich auch in Deutschland: Noch nie war ich so viel bei Facebook, Instagram, WhatsApp und vor allem bei ZOOM unterwegs wie in diesen Tagen. Unsere Veranstaltungen wanderten in die virtuellen Räume.
Mit einem Fuß in der Zukunft
Einerseits stürzt die Corona-Epidemie die ganze Welt in nie dagewesene Zeiten der Distanz. Gang anders, als wir Menschen es gewöhnt sind: Bei Bedrohung treibt uns unser Instinkt normalerweise dazu, Nähe zu suchen, zu Menschen, die uns lieben, die uns helfen könnten. Und jetzt? Wir schützen uns und die anderen nur dann, wenn wir sie uns vom Leib halten. Doch die Zeiten der Nähe kommen wieder, das weiß ich. Jetzt machen wir das Beste daraus. So wie der Mensch schon immer aus Krisen gestärkt herauskam.
Jeden Tag bekomme ich naturwissenschaftliche Newsletter aus der ganzen Welt: Die meisten Nachrichten der letzten Wochen drehen sich um den Kampf gegen das Corona-Virus. Wissenschaftler aller Länder vereinigt euch, flüstert Karl Marx aus dem Grab. Überall auf der Welt werden jetzt Technologien entwickelt, die uns helfen, auch die Ausbreitung von anderen, vielleicht noch viel schlimmeren Krankheiten als Covid-19 sehr früh vorherzusagen und zu verhindern. Eine weltweite Ebola-, SARS- oder MERS-Pandemie würde zu viel mehr Toten führen als die heutige. Auch diese Krankheiten waren in den letzten Jahren unterwegs in die weite Welt. Damals rettete uns nur Glück. In der Zukunft kann uns sicher nur gute Vorbereitung retten. Die Zukunft kommt aber auf jeden Fall. Ihre Medizin wird in diesen Tagen entwickelt. In einem rasenden Tempo, so schnell wie nie zuvor. Mit dieser neuen Medizin stehen wir viel besser aufgerüstet gegen Pandemien da. Auch dank Künstlicher Intelligenz.
Science is the poetry of reality.
Bleiben Sie gesund!
Titelbild: Gerald Altmann auf Pixabay.
willkommen auf meinem SciLogs-Blog "Gehirn & KI".
Ich möchte hier über alle möglichen Aspekte der Künstliche-Intelligenz-Forschung schreiben. Über jeden Kommentar und jede Diskussion dazu freue ich mich sehr, denn wie meine Mutter oft sagte:
"Solange die Sprache lebt, ist der Mensch nicht tot."
Neues über künstliche Intelligenz, künstliche neuronale Netze und maschinelles Lernen poste ich häufig auf meiner Facebook-Seite: Maschinenlernen
Hier etwas zu meiner Laufbahn: ich studierte Chemie an der TU München und promovierte anschließend am Lehrstuhl für Theoretische Chemie der TU über die Entstehung des genetischen Codes und die Doppelstrang-Kodierung in den Nukleinsäuren.
Nach der Promotion forschte ich dort einige Jahre lang weiter über den genetischen Code und die komplementäre Kodierung auf beiden Strängen der Nukleinsäuren:
Neutral adaptation of the genetic code to double-strand coding.
Stichworte zu meinen wissenschaftlichen Arbeiten: Molekulare Evolution, theoretische Molekularbiologie, Bioinformatik, Informationstheorie, genetische Codierung.
Zur Zeit bin ich Fachdozent für Künstliche Intelligenz an der SRH Fernhochshule und der Spiegelakademie, KI-Keynote-Speaker, Schriftsteller, Bühnenliterat und Wissenschaftskommunikator. Auf YouTube kümmere ich mich um die Videoreihe unserer SRH Fernhochschule "K.I. Krimis" über ungelöste Probleme und Rätsel der Künstlichen Intelligenz.
U. a. bin ich zweifacher Vizemeister der Deutschsprachigen Poetry Slam Meisterschaften.
Mein Buch „Doktorspiele“ wurde von der 20th Century FOX verfilmt und lief 2014 erfolgreich in den deutschen Kinos. Die Neuausgabe des Buches erschien bei Digital Publishers.
Mein Sachbuch über Künstliche Intelligenz "Ist das intelligent oder kann das weg?" erschien im Oktober 2020.
Im Tessloff-Verlag erscheinen meine von Marek Blaha wunderschön illustrierten Kinderkrimis "Datendetektive" mit viel Bezug zu KI, Robotern und digitalen Welten.
Viel Spaß mit meinem Blog und all den Diskussionen hier :-).
Jaromir
Zitat:
Ja, wobei aber auch ein AI-Programm nicht voraussieht, dass sie, Jaromir Konecny infolge Covid-19 alle ihre Veranstaltungen loswerden. Bis jetzt mindestens sind KI-Programme nicht zu kausalem Denken in der Lage, sie können keine echten Schlussfolgerungen ziehen, sondern „nur“ gerade die Funktionswerte einer hochkomplexen, vieldimensionalen Funktion relativ gut „erahnen“.
Einfach schlechte Daten für schlechte Leistungen von KI-Programmen verantwortlich zu machen, löst das Problem nicht, dass heutige KI-Programme die Welt schlicht und einfach nicht verstehen. Etwas was Menschen viel besser können, denn Menschen können die Gründe verstehen, die zu schlechten Daten führen – Maschinen bislang nicht.
Die Folgeprobleme von Covid-19 wie gebrochene Karrieren, Arbeitslosigkeit, Konkurse, die können jedenfalls Menschen heute viel besser erahnen (erahnen aber nicht vorsusberechnen) als jedes KI-Programm.
Martin Holzherr: ” Bis jetzt mindestens sind KI-Programme nicht zu kausalem Denken in der Lage, sie können keine echten Schlussfolgerungen ziehen, sondern „nur“ gerade die Funktionswerte einer hochkomplexen, vieldimensionalen Funktion relativ gut „erahnen“.”
Jaromir: KI-Programme, das heißt künstliche neuronale Netze (KNN) sind Werkzeuge, die entwickelt wurden, um einzelne komplexe Aufgaben zu lösen, die wir selbst nicht lösen können, weil sie eben zu komplex sind. KNN erweitern also unsere Fähigkeiten: Sie können bösartige Tumore auf Mammographie-Aufnahmen erkennen, Augenkrankheiten auf Augenscans, Vorhoflimmern aus SmartUhr-Daten, Texte ins Chinesische übersetzen, selbstfahrenden Autos den Weg weisen und und und. Es liegt in ihrer Natur, wichtige Zusammnehänge in komplexen Datensätzen zu ermitteln, die dem Datensatz innewohnende Repräsentation also in Hinsicht auf ein Problem.
Warum KNN dann noch zu kausalem Denken fähig sein müssten, verstehe ich nicht. Sie sind ein Werkzeug! Von den Programmen kausales Denken zu verlangen, kommt mir so vor, als ob man sagen würde: “Okay, eine Zange kann schon Schrauben aus dem Brett ziehen, denken aber kann sie nicht.”
@Jaromir Konecny (Zitat):
Antwort: Ohne schlussfolgerndes und urteilendes Denken werden künstliche neuronale Netze immer fehleranfällig im Einzelfall bleiben, auch wenn sie statistisch gesehen besser abschneiden als ein Mensch im Durchschnitt.Ein Versagen im Einzelfall welches etwa dazu führt, dass ein autonom fahrendes Auto ein entgegenkommendes Auto nicht mehr erkennt oder das dazu führt, dass es eine Geschwindigkeitsbeschränkung falsch liest, kann zu tödlichen Unfällen führen. Bei Tesla-Automobilen mit Fahrassistent wurden solche schwerwiegenden Fehlzuordnungen bereits als Ursache für Unfälle nachgewiesen. Der arxiv-Artikel DARTS: Deceiving Autonomous Cars with Toxic Signs geht darauf ein und bringt schon in der Einführung folgende Einschätzung der Gefahren einer falschen Erkennung eines Verkehrsschildes:
Täuschungsversuche waren auch bereits im Einsatz befindlichen Produkten wie Tesla-Atos erfolgreich. In der Schlussfolgerung des Artikels liest man;
Martin Holzherr: “Ohne schlussfolgerndes und urteilendes Denken werden künstliche neuronale Netze immer fehleranfällig im Einzelfall bleiben, auch wenn sie statistisch gesehen besser abschneiden als ein Mensch im Durchschnitt.”
Jaromir: Sollen wir also warten, bis künstliche neuronale Netze schlussfolgernd und urteilend denken können? Einige KI-Experten meinen ja, das passiere nie. Sie verlangen allgemeine künstliche Intelligenz für Programme, die eventuell nur Gurken sortieren sollen. Die meisten KNN werden heutzutage so eingesetzt, dass es vollkommen reicht, sie zu testen, wenn sie trainiert sind. Klar sollen wir Kontrollmechanismen für KNN entwickeln. Die Kontrolle sollte aber weiterhin der Mensch ausüben, eventuell mit anderen Werkzeugen, das heißt Programmen. So ist es mir auch lieber, als dass sich schlussfolgernde und urteilende Maschinen selbst kontrollieren.
@Jaromi Konecny: Schlussfolgern bedeutet so einfache Dinge (für Menschen) wie etwa einen auf die Strasse rollenden Ball 🏀 mit einem Kind 🧒 zu assoziieren – und das Auto 🚘 zu verlangsamen oder zu erwarten, dass hinter einem haltenden Bus Personen aussteigen und plötzlich auf der Strasse erscheinen könnten.
Wir Menschen als Autofahrer oder Velofahrer sind uns dessen oft gar nicht bewusst. Aber wir handeln oft, weil wir etwas voraussehen oder ahnen. Ferner klassifizieren Autofahrer auftauchende Gegenstände bereits im Fahrkontext. Ein Stück Karton 📦 auf der Strasse kann man überfahren, eine Öllache aber sollte ein Motorradfahrer meiden. Es geht also gar nicht darum Dinge zu erkennen, sondern darum die Bedeutung der Dinge für das Fahren zu verstehen.
Künstliche neuronale Netze sind ein Werkzeug, das bei seinem Training auf das Bewältigen einer Aufgabe optimiert wurde. Wenn man Fehler vermeiden will, muss man diese Werkzeuge zuerst mit einem “neutralen” Datensatz mit Daten von hoher Qualität trainieren, dann ihre Funktion ausgiebig testen und, wenn ihre Entscheidungen große negative Auswirkungen haben könnten, muss man sie kontrollieren. Mit unserem gesunden Menschenverstand aber auch mit anderen Programmen. Von einer solchen Maschine zu verlangen, dass sie allgemein schlussfolgern bzw. einen “gesunden Maschinenverstand” selbst zeigt, geht an der ganzen Sache vorbei.
@Jaromy Konecny: ein selbstfahrendes Auto muss ein kleiner Verkehrsexperte sein. Bei Rechtsvortritt muss es abschätzen ob es anhalten muss, wenn ein Auto von rechts naht oder ob es mit Beschleunigen eine Kollision vermeiden kann. Auch auf unvorhergesehene Verkehrssituationen muss es sinnvoll reagieren, bei beginnendem Regen oder einsetzender Dämmerung den Fahrstil anpassen und es muss damit zurechtkommen, dass andere die Verkehrsregeln verletzen.
Ganz anders beim Robotstaubsauger. Der darf auch Mal eine Münze aufsaugen oder sich in einem Wollknäuel verstricken.
Je nach Anwendung gibt es also ganz andere Anforderungen. Nicht für alle Anwendungen und Situationen, denen das AI-System begegnen wird, gibt es überhaupt die nötigen Daten. Oder trainiert man selbstfahrende Fahrzeuge etwa darauf wie sie auf Geisterfahrer reagieren sollen?
Ein Auto kann autonom fahren, ohne das Fahren zu verstehen. Die meisten autonom fahrenden Autos haben viel mehr Kilometer ohne Unfälle als jeder menschliche Fahrer hinterlegt, ohne dass sie verstanden haben, was sie tun. Es müssen nun mal in einem selbstfahrenden Autos so viele lernende Programme an der Erkennung seiner Umwelt und seiner Steuerung arbeiten, dass das Modell daraus auf alle auch unvorhergesehenen Straßensituationen reagiert. Das ist momentan noch nicht ganz erfüllt, deswegen müssen noch menschliche Kontrollfahrer mitfahren. In ein paar Jahren ist es aber so weit. Ohnen dass Autos gelernt haben, zu denken. 🙂 Das müssen sie nicht. Sie müssen uns nur sicher vom Ort A zum Ort B bringen. So wie ein Pferd, dem man beigebracht hat, nicht alles zu rammen, was ihm in den Weg kommt, wenn man’s zum Ziel reitet. Nur besser. 🙂
@Jaromir Konecny (Zitat):
Nein, ein aufmerksamer, professioneller Fahrer hat weniger Unfälle als ein selbstfahrendes Fahrzeug. Die meisten Unfälle passieren durch Unaufmerksamkeit, Abgelenkheit und Fahrunfähigkeit. Darum sind autonme Fahrzeuge heute schon besser als der durchschnittliche Fahrer. Wirklich gut sind selbstfahrende Fahrzeuge heute nicht. Sogar die autonomen Fahrzeuge von Waymo haben Mühe in eine Spur mit stehenden Fahrzeugen einzuspuren, weil sie nicht wissen wie man sich hineindrängt.
Über diese Schwächen wird nur selten berichtet, weil es (noch) einen Hype gibt.
@Jaromir Konecny: Besuchen die doch mal die Website von Waymo. Sogar dort wird deutlich, dass Waymo weiss, dass ihr Vorteil gegenüber einem menschlichen Fahrer die Tatsache ist, dass ein Waymo-Fahrzeug nicht betrunken und nicht abgelenkt ist (Zitat)
Dass Waymo-Fahrzeuge nicht betrunken und nicht unaufmerksam sind, macht sie noch lange nicht zu guten Fahrern.
Ob KI oder ein Mensch „besser“ Auto fahren kann, diese Frage ist absurd. Tausende Ehen scheitern an dieser Frage, die letztlich auf Rechthaberei hinausläuft.
Ein ehemaliger Nachbar (im Nebenberuf Fahrlehrer) hat seiner Frau wegen einer Lappalie das Auto fahren verboten, kurz darauf hatte er selbst einen Totalschaden.
Es kommt darauf an, ob KI Autos weniger Schäden verursachen, Kosten z.B. bei den Bus- und Taxifahrern einsparen. Geld regiert die Welt.
Vermutlich werden besonders am Anfang, „ratlose Autos“ am Straßenrand herumstehen und nicht selbständig weiterfahren können, weil sie wegen einer „ungewöhnlichen Situation“ nicht weiterfahren können. Dann muss eben ein Mitfahrer eingreifen, oder der ADAC schaltet sich per 5G Funknetz auf den Autocomputer „auf“ und hilft weiter.
@Jaromir Konencny, Elektroniker: Elektroniker hat recht: Autonomes Fahren wird kommen, auch wenn autonome Fahrzeuge immer wieder versagen, dabei aber immerhin keine Unfälle verursachen wie es angetrunkene und unaufmerksame Fahrer tun.
Hier noch ein Artikel indem darauf hingewiesen wird, dass Waymo-Ingenieure sehr genau wissen, dass ihre Fahrzeuge heute und noch auf lange Zeit Schwierigkeiten im Verkehr haben werden.
In 5 big challenges that self-driving cars still have to overcome Liest man:
Autofahren erfordert viele komplexe soziale Interaktionen – die für Roboter immer noch schwierig sind.
Ein Großteil der Tests, die Google im Laufe der Jahre durchgeführt hat, bestand darin, die Software der Autos so zu “trainieren”, dass sie verschiedene heikle Situationen erkennt, die auf den Straßen auftauchen. Das Unternehmen sagt zum Beispiel, dass seine Autos nun Radfahrer erkennen und ihre Handzeichen interpretieren können – etwa das Abbremsen, wenn der Radfahrer beabsichtigt, abzubiegen. Hier ist eine Demonstration:
So weit, so gut. Aber Olson weist darauf hin, dass es Tausende und Abertausende anderer Herausforderungen gibt, die auftauchen, von denen viele recht subtil und unvorhersehbar sind. Stellen Sie sich zum Beispiel vor, Sie sind ein Autofahrer, der auf einen Zebrastreifen kommt, und ein Fußgänger steht auf dem Bordstein und schaut auf sein Smartphone. Ein menschlicher Fahrer wird ihr Urteilsvermögen nutzen, um herauszufinden, ob diese Person auf der Stelle steht oder geistesabwesend im Begriff ist, die Straße zu überqueren, während er in sein Telefon vertieft ist. Ein Computer kann diesen Anruf (noch) nicht tätigen.
Oder denken Sie an all die verschiedenen Fahrsituationen, die Blickkontakt und subtile Kommunikation erfordern, wie das Navigieren an Kreuzungen mit vier Fahrtrichtungen oder ein Polizist, der mit Autos um einen Unfallort herumwedelt. Leicht für uns. Immer noch schwer für einen Roboter. Wie Sam Anthony von der Harvard University betont, sind KI-Autos unglaublich leicht zu trollen.
Olson erklärt, dass vollständig selbstfahrende Autos letztendlich vier Schlüsselaufgaben beherrschen müssen: 1) die Umgebung um sie herum zu verstehen; 2) zu verstehen, warum die Menschen, denen sie auf der Straße begegnen, sich so verhalten, wie sie sind; 3) zu entscheiden, wie sie reagieren sollen (es ist schwierig, eine Daumenregel für Vierwegestopschilder aufzustellen, die jedes Mal funktioniert); und 4) mit anderen Menschen zu kommunizieren.
Fazit: Wenn Jaromir Konecny hier abstreitet, dass autonome Fahrzeuge die Verkehrssituaion verstehen müssen obwohl Waymo-Ingenieure das ebenfalls sagen, dann zeigt er genau den gleichen Technologie-Optimismus wie er bei vielen Erneuerbaren-Evangelisten festzustellen ist, die Schwierigkeiten einer rein erneuerbaren Energietechnologie am liebsten totschweigen.
Zitat:
Ja und nein. Ja, weil man tatsächlich auch ohne Denken Auto fahren kann. Nein, weil wenn man ohne Denken fährt, letztlich kein besonders guter Autofahrer ist. Denken beim Autofahren bedeutet vor allen den Kontext berücksichtigen, korrekte Vorhersagen machen, Gefahren erkennen, Verkehrsregeln kennen und potenzielle Verstösse dagegen erkennen. Das sind lauter Dinge, womit ein Deep Learning System Schwierigkeiten hat. Ein Deep Learning System wird beispielsweise nicht unbedingt aus der schlingernden Fahrweise des Autos vor ihm darauf schliessen, dass vom Fahrer eine Gefahr ausgeht, es wird auch weniger gut in der Lage sein einzuschätzen, ob ein Mensch am Strassenrand drauf und dran ist die Strasse zu überqueren. Teslas Fahrassistent vergass auch schon mal überstehende Gegenstände des kreuzenden oder entgegenkommenden Fahrzeugs zu berücksichtigen und Googles mit Lidar ausgerüsteten Autos hatten/haben Schwierigkeiten bei Stau in die Spur einzuschwenken auf der die Autos nur ruckweise vorwärtskommen.
Fazit: Autofahren im Schlafwandelmodus ist kein besonders sicheres Fahren. Nur dazu aber sind heutige autonome Fahrzeuge momentan in der Lage.
Als Informatiker muss ich ihren Ausführungen widersprechen:
“KNN erweitern also unsere Fähigkeiten: Sie können bösartige Tumore auf Mammographie-Aufnahmen erkennen, Augenkrankheiten auf Augenscans, Vorhoflimmern aus SmartUhr-Daten, Texte ins Chinesische übersetzen, selbstfahrenden Autos den Weg weisen und und und”
Eine KI erkennt nichts, denn das würde eine Erkenntnis voraussetzen.
Eine KI kann Muster finden und diese z.B. in Bildern als verdächtig markieren.
Füttern sie aber eine KI statt mit Röntgenbildern einer Brust mit Urlaubsfotos oder einem anderen Organ, so wir die KI auch irgendein Ergebnis liefern. Anders als ein Radiologe würde die KI nicht einmal merken, dass die Daten, die ihr vorgesetzt wurde, unsinnig sind.
Ich kenne aus eigene Erfahrung KIs, die z.B. Fingerabdrücke auf Röntgenfilmen als Mikroverkalkungen und damit als ein Hinweis auf Krebs erkennen … ein Mensch hätte diesen Fehler sicher nicht gemacht.
Das ist auch keine Schwäche des Trainings oder der Daten vor Ort, sondern der Unterschied von Labor und Realität.
Was sich heute KI nennt ist nichts als Statistik .. mit Intelligenz hat es nichts zu tun.
Deswegen sollte man auch nicht so tun als wenn eine KI etwas “besser” oder “intelligenter” als ein Mensche könnte … für eine Diagnose macht ein Arzt viel mehr als nur ein Bild betrachten … und ein Autofahrer kann sein Auto auch noch fahren, wenn kein digitalisiertes Strassennetz etc. zur Verfügung steht.
etc.
einer: “Als Informatiker muss ich ihren Ausführungen widersprechen: … Eine KI erkennt nichts, denn das würde eine Erkenntnis voraussetzen.”
Jaromir: Ich hoffe, ich darf Ihnen auch widersprechen: Für das Wort “erkennen” erlaubt der Duden die Bedeutung “aufgrund bestimmter Merkmale ausmachen, identifizieren”. Und genau das machen künstliche neuronale Netze (KNN): Sie erschließen und identifiziren Merkmale der Daten, die sie verarbeiten. Man kann das selbstverständlich auch Mustererkennung nennen oder das Finden einer Repräsentation für die verarbeiteten Daten oder die Ermittlung einer Funktion bzw. ihrer Approximation, wie die Ausgabe des KNNs von seiner Eingabe abhängt.
Ich musste jetzt lachen, da ich in dieser Diskussion selbst Herrn Holzherr zurede, dass wir nicht erwarten sollen, künstlichen neuronalen Netzen “das Denken” beizubringen. 🙂
Ich sehe das Problem hier ist vor allem die Begrifflichkeit.
Meiner Meinung nach erkennt eine KI einen Tumor genauso wie eine Photodiode Licht “erkennt”.
Und mein Verständnis von “erkennen” kommt von Erkenntnis.
Oft ist das Problem, dass Pattern-Matching mit Diagnose o.ä. gleichgesetzt wird. Damit habe ich ein Problem.
Weil so auch Erwartungen geweckt werden, die eine schwache KI nicht erfüllen kann. Da reichen ggf. schon kleine Veränderungen an Strassenschildern und es kommt großer Mist raus. Das ist ein grundsätzliches Problem von Pattern-Matching. Denn man kann nicht mit allen zu erwartenden Daten trainieren .. und genau da wird auch der Unterschied zu einer starken (K)I sichtbar.
Wenn man die Datenqualität halbwegs kontrollieren kann, kann man ganz tolle Sachen mit KI machen … aber draussen in der Wildnis? Da wird ein Laster schnell mal zu einem Tunnel …
einer: “Füttern sie aber eine KI statt mit Röntgenbildern einer Brust mit Urlaubsfotos oder einem anderen Organ, so wir die KI auch irgendein Ergebnis liefern. Anders als ein Radiologe würde die KI nicht einmal merken, dass die Daten, die ihr vorgesetzt wurde, unsinnig sind.”
Jaromir: Das ist eine triviale Tatsache. Das habe ich hier im Blog öfter thematisiert, zum Beispel die berühmten Experimente, in denen man in Wohnzimmerfotos einen Elefanten kopierte und die KNN-Modelle dadurch so verwirrte, dass diese dann nicht einmal einen Stuhl von einem Sofa unterscheiden konnten, obwohl sie eben darauf trainiert waren, Wohnzimmergegenstände zu unterscheiden.
KNN werden NUR auf eine bestimmte Aufgabe hin trainiert. Wenn wir ein KNN trainieren, Tumore auf Mammographie-Aufnahmen zu erkennen, was macht es dann für einen Sinn, ihnen Urlaubsfotes zu zeigen? Das wäre das Gleiche, wie mit einem Hammer Blech schneiden zu wollen.
Ok – das war auch extrem .. ggf. reichen schon ein paar für einen Menschen u.U. nicht wahrnehmbare Veränderungen an einem Schild o.ä. und die Ergebnisse einer KI sind nicht mehr vorhersagbar.
Das Problem ist hier halt, dass das Pattern-Matching bzw. die Optimierung der Gewichte im NN nur bedingt etwas mit dem zu lösenden Problem zu tun hat.
einer: “Das ist auch keine Schwäche des Trainings oder der Daten vor Ort, sondern der Unterschied von Labor und Realität.
Was sich heute KI nennt ist nichts als Statistik .. mit Intelligenz hat es nichts zu tun.”
Jaromir: Aha! Und wa ist der Unterschied von Labor und Realität? Ich verrate’s Ihnen: Die verwendeten Daten. 🙂
Niemand behauptet hier, dass künstliche neuronale Netze intelligent sind. Der Begriff Künstliche Intelligenz wurde 1956 von John McCarthy in einem Antrag für die legendäre Dartmouth-Konferenz entwickelt, um damit Programme zu definieren, die egal welche Aspekte des menschlichen Denkens nachahmen können. Deswegen zählt man zu dem großen Gebiet der Künstlichen Intelligenz auch das klassische Maschinenlernen wie zum Beispiel Entscheidungsbäume, das tatsächlich nichts als Statistik ist. Schon ein Programm, das Gurken aufgrund ihrer Qualität klassifizieren kann, ist somit Künstliche Intelligenz. So ist es nun mal, das haben gscheitere Leute als wir entschieden: John MacCarthy, Marvin Minsky, Claude Shannon und viele andere KI- und Informatik-Urväter der Konferenz in Dartmouth.
Doch künstliche neuronale Netze sind etwas mehr als Statistik. Im klassischen Maschinenlernen muss der Programmierer zuerst die Merkmale (Features) der Daten bestimmen, damit die Programme damit arbeiten können. Künstliche neuronale Netze ermitteln während eines Trainings mit vielen Daten (Beispielen) die Merkmale der Daten SELBST. Nach einem solchen Traininig können sie oft wunderbar verallgemeinern und auch die menschliche Leistung IN DIESER BESTIMMTEN AUFGABE übertreffen. Wenn Sie mir nicht glauben, googeln Sie einfach etwas. 🙂
Mir ist es nicht ganz klar, warum Sie hier den Menschen gegen die Maschine aufrechnen müssen. Klar kann ein Arzt viel mehr, als nur auf Tumorbildern bösartige von gutartigen Tumoren zu unterscheiden. Deswegen sage ich ja das Folgende (was Sie komischerweise kritisieren): Künstliche neuronale Netze sollen uns nicht ersetzen – sie sind Wekzeuge, die unsere Fähigkeiten erweitern.
Ansonsten gebe ich Ihnen aber vollkommen recht: Maschinen sind nicht intelligent, und werden es noch lange nicht sein. Bis eine Maschine das Gegenteil beweist. 🙂
Martin Holzherr: “Einfach schlechte Daten für schlechte Leistungen von KI-Programmen verantwortlich zu machen, löst das Problem nicht, dass heutige KI-Programme die Welt schlicht und einfach nicht verstehen.”
Jaromir: Welches Problem sollte denn gelöst werden? Ich wollte in diesem Blogtext zeigen, dass unsere heutigen KI-Programme IM ALLGEMEINEN mit vielen und hochwertigen Daten trainiert werden müssen, damit sie richtig funktionieren. Und das ist ein Fakt. Warum die Programme noch dazu die Welt verstehen müssten, verstehe ich nicht. Künstliche neuronale Netze (KNN) sind nur ein Werkzeug, das uns bei der Lösung von bestimmten Aufgaben hilft. Mehr ist nicht drin. Schon das, was drin ist, ist aber gut genug.
@Jarromi Konecny(Zitat):
Wenn ein Programm, das nicht einmal weiss was ein Blutdruck oder ein Mensch ist, ein blutdrucksenkendes Mittel verschreibt, dann sehe ich da schon ein Problem.
Gut, wenn man das Programm einfach als Assistenzsystem verwendet, kann man das verantworten.
Diese Programme sollen unsere Fähigkeiten erweitern, nicht uns ersetzen. In diesem Sinne sind sie tatsächlich unsere Assistenzsysteme. Mit mehr oder weniger Autonomie: 🙂 Mit ist es egal, ob die Maschine weiß, was Blutdruck oder ein Mensch ist, wichtig ist doch, dass sie ein blutdrucksenkendes Mittel entwickelt, dass tatsächlich funktioniert. Dann wird das Mittel getestet, so wie alle Medikamente getestet werden. Ogal ob sie von Menschen oder von Maschinen entwickelt wurden.
Martin Holzherr: “Die Folgeprobleme von Covid-19 wie gebrochene Karrieren, Arbeitslosigkeit, Konkurse, die können jedenfalls Menschen heute viel besser erahnen (erahnen aber nicht vorsusberechnen) als jedes KI-Programm.”
Jaromir: Da bin ich mir nicht sicher. Was in einem Jahr in bestimmten Breichen sein wird, könnten KI-Programme wohl besser voraussagen, als jeder Mensch. Wenn sie eben mit vielen relevanten historischen und momentanen Daten gefüttert werden. So wie sie besser als der Mensch das Wetter und die Aktienkurse voraussagen. Ein Mensch ist nun mal nicht in der Lage, solche komplexen Probleme zu erfassen. Niemand von uns weiß, was auf uns zukommt. So bleibe ich vorsichtshalber optimistisch. 🙂
Künstliche Intelligenz ist eine Kunst, die natürlich intelligent eingesetzt werden muss 😉
Danke für den interessanten Beitrag.
Das sehe ich genauso! Vielen Dank für den Zuspruch. Der freut. 🙂
Hallo,
ja der Beitrag ist toll. Bei de.rec.buecher hat man halt mal was gelernt, auch was den Umgang mit trolligen Beiträgen angeht, wie ich sehe …
Google hatte doch auch mal so ein Projekt, bei dem Grippewellen über Suchanfragen vorhergesagt wurden. Das wurde aber nicht weiterverfolgt, oder?
Hallo Gerald, danke! Ja, das waren Zeiten damals im Usenet. 🙂 Mit dem Google-Grippe-Projekt meinst Du wohl Google Flu Trends (GFT). Das Projekt hat man, vor 2010 gestartet, ein paar Jahre später versagte es aber völlig, und man hat’s abgeblasen. Wenn ich mich nicht irre, hing das auch von den Daten ab, mit denen man die Maschine trainierte. Vielleicht waren die Modelle aus künstlichen neuronalen Netzen damals noch nicht so weit. Erst 2012 startete ja mit dem Erfolg von AlexNet bei der ImageNet-Challenge die Revolution in Deep Learning.
Ein Gutes hat die ganze Corona-Geschichte ja: so manch geschätzter Blogger findet einmal wieder Zeit für einen Artikel.
Eine Frage hätte ich zu der Warnung von BlueDot: natürlich ist es eindrucksvoll, dass die Warnung so schnell kam, aber ist eigentlich bekannt, ob und wenn ja wie viele ähnliche Warnungen das System ausgegeben hat, die sich dann nicht bestätigt haben? Das scheint mir der kritische Test zu sein, denn ein System, bei dem z.B. auf 10 Fehlalarme ein Treffer kommt, wäre natürlich nutzlos.
Grundsätzlich erwarte ich auch, dass eine KI bei Zukunftsvoraussagen besser abschneidet als der Mensch. Ein Mensch betrachtet komplexe Datensätze stets durch ein Filter, das auf seinen persönlichen Erfahrungen beruht, das auch gerne als “gesunder Menschenverstand” glorifiziert wird. Dabei ist der gesunde Menschenverstand bekanntlich nichts anderes als die
(Einstein). Ein System, dass frei von solchen Vorurteilen ist, sollte mit komplexen Zusammenhängen schon besser zurechtkommen.
Es könnte den Menschen sogar dabei helfen, solche Vorurteile zu überwinden: im Go spielen Profis mittlerweile Josekis, die man über Jahrhunderte nicht einmal beachtet hatte, weil sie scheinbar elementaren Grundprinzipien widersprachen. AlphaGo fungierte hier als Augenöffner.
Genau die Frage nach den “Fehlalarmen” hätte mich auch interessiert?
Wenn man nicht geschickte Selektionskriterien verwendet, neigen derartige Systeme eine riesige Zahl von falschen Alarmmeldungen auszugeben.
Im Nachhinein könnte man sich leicht den erfolgreichsten Alarm heraussuchen.
aristius fuscus: “Ein Gutes hat die ganze Corona-Geschichte ja: so manch geschätzter Blogger findet einmal wieder Zeit für einen Artikel.”
🙂 Jetzt musste ich lachen. Sie haben aber recht. Nur fiel bei mir der Anfang der Corona-Krise mit der Abgabe meines Sachbuchs über Künstliche Intelligenz zusammen. 2019 musste ich sechs Bücher abegeben. Mir ging einfach die Zeit aus, zumal ich im Herbst sicher mindestens 40 Veranstaltungen hatte.
Jetzt bin ich aber wieder da und will hier öfter etwas posten, vielleicht einmal pro Woche. 🙂 Eher aber kürzere Texte: Interessantes über neu Entwicklungen in KI.
aristius fuscus: “Eine Frage hätte ich zu der Warnung von BlueDot: natürlich ist es eindrucksvoll, dass die Warnung so schnell kam, aber ist eigentlich bekannt, ob und wenn ja wie viele ähnliche Warnungen das System ausgegeben hat, die sich dann nicht bestätigt haben?”
Jaromir: Ob BlueDot auch öfter Falschalarm schlug, ist für einen Außenstehenden schwierig nachzuvollziehen. Ich weiß nicht, inwieweit BlueDots Vorhersagen von Menschen geprüft werden, bevor sie weiter in die Welt gehen. Hier würde ich aber sehr benevolent mit der Maschine umgehen. Sollche Modelle, die Monitoring für Ausbrüche von Krankheiten machen, sind meist auf im Internet frei zugängliche und unstrukturierte Daten angewiesen. Aufgrund von Datenschutz bekommen sie nicht die hoch qualitativen Daten der staatlichen Gesundheitsorganisationen. Meiner Meinung nach ist es ein Wunder, dass BlueDot uns bereits vor dem Zika- und Ebola-Virus und eben vor SARS-Cov-2 warnen konnte.
Ich hätte an Sie Herr Konecny, als Fachmann für evolutionäre Entwicklungen, eine Frage die Viren betreffend.
Wie wäre es, in Hinblick auf die vermutlich „immerzu weitergehende“ Evolution, wenn man nehmen wir einmal an, alle Viren (und eventuelle auch andere Krankheitserreger) die wir für schädlich halten, massiv ausrotten würden (und das auch könnten)?
Welche Folgen hätte dies aus Ihrer Sicht.
Den Einsatz von KI halte ich für genauso zweckmäßig wie Sie. Ich vermute, manche Gegner sehen in der KI eine Art „Konkurrenz“ für den Menschen, was im Bezug auf Arbeitsplätze, besonders auf die Abwertung höher qualifizierter Arbeitsplätze, sicherlich ein Problem werden könnte, z.B. verloren Versicherungsmathematiker ihre Jobs.
Andererseits macht es KI möglich riesige vorhandene Datenbestände nach bestimmten Mustern zu durchforsten bzw. auch neue Muster zu finden, die von Relevanz für einen bestimmten Zweck sein könnten.
KI ist eben, genau so wie Sie es sehen, ein Werkzeug für Fachleute.
Elektroniker: “Wie wäre es, in Hinblick auf die vermutlich „immerzu weitergehende“ Evolution, wenn man nehmen wir einmal an, alle Viren (und eventuelle auch andere Krankheitserreger) die wir für schädlich halten, massiv ausrotten würden (und das auch könnten)? Welche Folgen hätte dies aus Ihrer Sicht.”
Jaromir: Das würden wir nicht überleben. 🙂 Die meisten Mikroorganismen, Viren und Bakterien, leben in uns und mit uns symbiotisch. Krankheiten entstehen, wenn dieses Gleichgewicht gestört wird. Wohl sind wir selbst aus RNA-Viren entstanden, unser Immunsystem verdanken wir auf jeden Fall den Viren. Die bakterielle und virale DNA in unserem Körper macht mehr aus als unser eigenes Genom.
Elektroniker: “Den Einsatz von KI halte ich für genauso zweckmäßig wie Sie. Ich vermute, manche Gegner sehen in der KI eine Art „Konkurrenz“ für den Menschen, was im Bezug auf Arbeitsplätze, besonders auf die Abwertung höher qualifizierter Arbeitsplätze, sicherlich ein Problem werden könnte, z.B. verloren Versicherungsmathematiker ihre Jobs.”
Jaromir: Das sehe ich so wie Sie. So enthusiastisch wie ich bin :-), denke ich außerdem, dass wir mit künstlichen neuronalen Netzen eine große Chance bekommen haben, die Erde und uns vor uns selbst zu retten. Hier muss ich meinen tschechischen Landsmann Tomas Mikolov zitieren, den Entwickler des word2vec-Algorithmus, der die Verteilungshypothese in die maschinelle Verarbeitung der natürlichen Sprache einführte:
„Es gibt diese Argumente, dass wir vielleicht keine Künstliche Intelligenz entwickeln sollten, weil sie uns zerstören würde. Was ist aber, wenn das Nichterreichen der Künstlichen Intelligenz die größte existenzielle Bedrohung für die Menschen ist?“ (Tomas Mikolov)
Data is all [there is] [modifizierte Absatzüberschrift, dem dankenswerterweise zV gestellten Text entnommen]
…ginge ebenfalls.
Während spieltheoretisch oft aber ein Erfolg, ein Spielerfolg festgestellt werden kann, von AI beispielsweise, dass sich so iterativ und wohl mittlerweile auch probabilistisch vorgehend, ratend, also : stochastisch, bei Spielen, kann dies in der Natur, naturwissenschaftlich nicht sein, es liegt kein Prüfstein (Goethe, über das Schachspiel) vor, sondern die Welt geschieht sozusagen einfach.
Die AI kann also nicht klar trainiert werden.
Was natürlich aus diesseitiger Sicht nicht gegen den Einsatz von AI bei naturwissenschaftlicher Problematik, bei aktueller naturwissenschaftlicher Problematik spricht, aber doch der AI Grenzen aufzeigt, also dieses Nichtvorhandensein eines sozusagen unabhängigen Schiedsrichters, der einen Erfolg, einen Spielerfolg bedarfsweise zu messen in der Lage ist.
Methoden der AI könnten insofern vom eigentlichen Problem und seiner Lösung, wie bei “Corona” beispielsweise, die aktuelle Variante ist gemeint, sie kann noch mutieren, weggehen, so dass nur “gestochert” wird, von der AI, was nicht schlecht sein muss, aber für Entscheider zu berücksichtigen ist, also möglicher weltlicher Misserfolg der AI.
Erkennende Subjekte gehen i.p. Natur und ihrer Entwicklung wie folgt vor :
Sie erfassen ausschnittsartig, näherungsweise und an Interessen (!) gebunden, um dann ausschnittsartig, näherungsweise und an Interessen (!) gebunden zu theoretisieren, diese Arbeit dann in Liberaler Demokratie für die politische Bearbeitung bereit zu stellen, wobei Naturwissenschaftler nicht selbst über ein politisches Mandat verfügen und insofern die Bildung und Durchsetzung von Maßnahmen dem demokratischen Gerühre, dem so gemeinten (nie enden währenden) Diskurs überlassen bleibt.
Mal am Rande angefragt, für wie groß halten Sie, die Gefahr, Herr Konečný, persönlich?
(Auch einzelne Meinung interessiert, Dr. W hat, dies soll an dieser Stelle verraten werden, hierzu wenig Meinung, außer, dass die Remedy die Schadwirkung der Gefahr in keinem Fall übersteigen sollte.)
MFG
Dr. Webbaer
Die Überschrift meines Absatzes “Data is all you need” ist eine Anspielung auf den wegweisenden Artikel der Google-Forscher “Attention is all you need” über die fabelhaften Transformer – KI-Modelle der maschinellen Verarbeitung der natürlichen Sprache (natural language processing). 🙂
Dr. Webbaer: “Während spieltheoretisch oft aber ein Erfolg, ein Spielerfolg festgestellt werden kann, von AI beispielsweise, dass sich so iterativ und wohl mittlerweile auch probabilistisch vorgehend, ratend, also : stochastisch, bei Spielen, kann dies in der Natur, naturwissenschaftlich nicht sein, es liegt kein Prüfstein (Goethe, über das Schachspiel) vor, sondern die Welt geschieht sozusagen einfach.
Die AI kann also nicht klar trainiert werden.”
Jaromir: Künstliche neuronale Netze, unsere heutige KI also, können und müssen mit vielen Beispielen trainiert werden (ansonsten funktionieren sie nicht) und werden auch trainiert. Sonst würde es keine Medienberichte über diese Programme geben. 🙂
Dr. Webbaer: “Mal am Rande angefragt, für wie groß halten Sie, die Gefahr, Herr Konečný, persönlich?”
Jaromir: Welche Gefahr? (Ich liebe konkrete Fragen :-))
Ich könnte mir vorstellen dass es 2 grundsätzliche Anwendungsfälle für KI gibt, die auf die Bedenken von Dr. Webbaer eingehen.
1) Man lässt das System nach (mehreren) konkreten (komplexeren) Mustern und nach ihrem Auftreten bzw. Relationen in großen Datenbeständen (“Datenfriedhöfen”) suchen. Dies ist zwar wenig kreativ. Man hat das System aber gut unter Kontrolle.
2) Das System sucht selbständig systematisch nach unbekannten selbst generierten Mustern und eventuell auch Relationen. Dabei stößt das System auf Muster die bisher unbekannt, sehr nützlich aber auch völlig sinnlos sein können. Der Anwender muss versuchen vernünftige Interpretationen zu finden, was oft nicht gelingt. Es kann naheliegender Weise mitunter gefährlich sein Mustern (blind) zu vertrauen, zumal es dabei zu unbekannten Schäden kommen könnte.
Anschauliche, etwas an den Haaren herbeigezogene Bespiele:
1.) Eine Restaurantkette möchte wissen, wie der Zusammenhang zwischen dem Bierkonsum und scharfen Gulasch in Abhängigkeit von den Preisen ist, um den Umsatz zu maximieren.
2.) Die Restaurantkette ist “ahnungslos” und möchte nach „Konsummustern“ forschen die maximalen Gewinn versprechen. Das KI Programm kommt neben vielen anderen Vorschlägen darauf, dass scharfes Gulasch und Bier viel Umsatz generiert. Etwas skurril, aber es könnte z.B. auch davon abhängen dass es sehr heiß ist, oder die Kunden Fieber haben, was gar nicht berücksichtigt ist. (Nur besonders „starke“, womöglich auch noch “Bier resistente” Viren freuen sich und wandern über die Biergläser fast schon direkt von Mund zu Mund…)
@ Jaromir Konecny
Der unter der Leitung von Tomas Mikolov bei Google erstellte „Word2vec Algorithmus“ gehört für mich zu den hervorragendsten geistigen Leistungen der Welt.
Früher schien es unmöglich dass Computer jemals einen Text sozusagen „verstehen“ können, den Kontext, also in einem Text die „Bedeutung“ zumindest eines Wortes im Zusammenhang erkennen zu können. Der Word2vec Algorithmus kommt diesem Verstehen „näher“.
Es geht hier um Assoziationen bestimmter Art, z.B. in sprachlichen Texten. Von einer z.B. „Wortrepräsentation“, (Buchstaben, Objekt, Objektkomponente…) verweist grundsätzlich ein „Zeiger“ (Vektor) auf eine weitere „Repräsentation“ mit der ein (bewerteter) „Zusammenhang“ besteht.
„Wortvektoren“ werden im Vektorraum möglichst so positioniert, dass Wörter, die gemeinsame Kontexte, (annähernd gleiche) Bedeutung haben, im Vektorraum möglichst nahe beieinander liegen. Dadurch kann letztlich die Zugehörigkeit zu einer bestimmten „Bedeutung“ errechnet werden.
In biologischen neuronalen Netzwerken gibt es sogar Assoziationen z.B. von Bildern mit Gefühlen.
Allerdings scheinen Gefühle schwer programmierbar, weil man nicht einmal versteht wie es dazu kommt.
Ich vermute, Gefühle (Qualia) entstehen an elektrisch chemischen Schnittstellen im neuronalen Netz, wenn mechanisch oder durch elektrische Impulse auf die die Atom/Molekülverbände „zusammenhaltenden Elektronenbahnen“ Einfluss genommen wird (Modulation). Aus der „Bahn geworfene Elektronen“ würden natürlich im neuronalen Netz ausgewertet, so das letztlich der Ort der Empfindungen korrekt lokalisiert werden kann, sofern es keine Störungen, z.B. Amputationen gibt. In diesem Fall kann es zu Phantomschmerzen kommen.
Die Informatik verwendet Zeiger (eine Art „Hausnummer“) als „Verweise“ auf „Speicherplätze“ (auch abstrakter Art).
Im neuronalen Netz verweisen („zeigen“) die Axone ausgehend von einem „Objekt(oder einer Objektkomponente)“ direkt als „Signalleitung“ auf ein nächstes „Objekt(Komponente)“, real repräsentiert als „Synapse“ und die Signale werden über die Dendriten (gezielt) zu einem weiteren Neuron, zwecks „logischer“ Verknüpfung (Schaltalgebra) mit anderen Signalen, geführt.
Diese logischen Verknüpfungen (Gatter (McCulloch)) ermöglichen auf allen Ebenen eine Bildung hoch komplexer Strukturen. Z.B. müssen gleichzeitig bestimmte „Muster“ auftreten um zunächst einen Buchstaben, danach ein Wort … letztlich Wissen(skomponenten) zu erkennen, „abzubilden“.
Bedeutet weiters, durch die Anlegung der Synaptischen Verknüpfungen wird „Wissen“ in die Struktur gemäß der Hebbschen Regel „eingeschrieben“, wie es E. Kandel entdeckt hat.
Es ist allerdings kein linearer Text wie bei der Textverarbeitung, sondern aus dem beschriebenen Sachverhalt folgt, dass die neue Information in die bestehenden Verknüpfungen durch Strukturerweiterungen (neue Synapsen) in die bestehende Struktur eingebunden wird. Auf diese Art entsteht das sich immer weiter entwickelnde „Wissen“. Wegen der grundsätzlichen baumartigen Struktur sind die „Zugriffseigenschaften“ bestens. Zusätzliche „weite Vernetzungen“ dürften die Assoziationen über den „engen Vektorraum“ hinaus ermöglichen.
Ich nehme an, es wird so nebenbei auch eine Art von „Zuordnungsstruktur“ neben der „puren“ Wissensstruktur gebildet, um den neuen (nunmehr mit dem alten Text „verwobenen“ neuen) Text später konkret einer „Inputsituation“ (z.B. gelesen in einer Fachzeitschrift) zuordnen zu können.
Beim Word2vec Algorithmus ist das „Wissen“ (derzeit vermutlich) auf die „Nebenbedeutungen“ bestimmter Worte begrenzt.
“Wer hätte das im Februar geahnt…”
Hier zeigt sich wieder einmal die Naivität der Menschen, die künstliche Intelligenz wahrscheinlich nicht hat. Ich selbst habe damals die Situation in China bereits als “Bedrohung” empfunden und mein gesunder Menschenverstand hat mir suggeriert, dass auf Grund dieser globalisierten uns in sich vernetzten Gesellschaft dieser Virus bald zu uns kommen könnte. Ich denke, dass viele Menschen sich in dieser abgesicherten Wohlfühlgesellschaft so nett eingerichtet haben, dass ihnen jede Zweifel vor möglichen Gefahrensituationen abhanden gekommen sind(Motto: Es gibt ja gegen alles eine Versicherung). Wenn sich selbst Experten und Politiker in dieser Wohlfühlblase -ganz der Realität entrückt- tummelten, dann sollte ,man in Zukunft mehr auf die künstliche Intelligenz setzen um die Menschen vor sich selbst zu schützen.
Man wusste schon seit lagem, dass Pandemien durch den Umgang der Menschen mit der Umwelt und der Globalisierung kommen werden.
Einige davon hatten wir ja schon. (Mers, Sars etc.)
Allerdings werden Probleme der Zukunft von der Politik in der Regel erst wahrgenommen, wenn es den Ausgang der nächsten Wahl ungünstig beeinflusst. (siehe in Deutschland z.B. Atomkraft, Klima …)
einer: “Allerdings werden Probleme der Zukunft von der Politik in der Regel erst wahrgenommen, wenn es den Ausgang der nächsten Wahl ungünstig beeinflusst. (siehe in Deutschland z.B. Atomkraft, Klima …)”
Jaromir: Das sehe ich genauso wie Sie. Auch die Politiker sind aber nur Menschen. Zu keinem dieser Themen herrscht in der Gesellschaft eine breite Übereinstimmung. Die Politiker sitzen immer in einer Falle: Etwas populistisch müssen sie schon entscheiden, sonst werden sie nicht gewählt. So trifft man nun mal Entscheidungen, die sich nach den Mehrheiten in der Bevölkerung richten.
Auch hier können uns aber künstliche neuronale Netze (KNN) helfen. Es ist leichter, einen “neutralen” Datensatz vorzubereiten, mit dem ein KNN trainiert wird, das neutrale Entscheidungen trifft, als einem Menschen neutrale Entscheidungen “beizubringen”. Eine Maschine hat keinen Blutzuckerspiegel, sie ist nicht depressiv oder sexuell unbefriedigt. “Vorurteile” hat sie und nicht neutrale Entscheidungen trifft sie nur dann, wenn der Mensch ihr diese beigebracht hat – mit einem nicht neutralen Datensatz.
Klar können KNN aufgrund ihrer momentanen Eindimensionalität plötzlich ganz verrückte Entscheidungen treffen. Deswegen müssen sie (und werden) ausgiebig getestet. Außerdem müssen sie von Menschen kontrolliert werden. Die verrückten Entscheidungen erleichtern uns aber die Kontrolle – sie sind schnell sichtbar.
Trotzdem bin ich mir sicher, dass diese verrückten Entscheidungen kleine Kinderkrankheiten sind. Die Algorithmen werden erst jetzt ordentlich entwickelt und werden immer besser. Schon gibt es Modelle, die eine etwas breitere “Sicht” haben, als sklavisch nur eine Aufgabe auszuführen. Ich glaube nicht, dass wir dafür eine allgemeine künstliche Intelligenz brauchen. Die wird, meiner Meinung nach, sowieso eher im Labor gezüchtet als programmiert. 🙂
KNN liefern schon jetzt in vielen Gebieten fabelhafte Ergebnisse. Bevor man das Ganze zerredet, sollte man vielleicht überlegen, dass man selbst jeden Tag Modelle aus künstlichen neuronalen Netzen verwendet, ohne es sich überhaupt bewusst zu sein.
@ Jaromir Konecny
Zitat: „….hat keinen Blutzuckerspiegel, sie ist nicht depressiv oder sexuell unbefriedigt. “Vorurteile” hat sie und nicht neutrale Entscheidungen trifft sie nur dann, wenn der Mensch ihr diese beigebracht hat ….“
So wie der Word2vec Algorithmus einen Text sozusagen fast schon „verstehen“ kann, also den Kontext, in einem Text die „Bedeutung“ zumindest eines Wortes im Zusammenhang erkennen zu können, sollte er auch irgendwann eine Nähe zu Depressionen oder zur sexuellen Befriedigung erkennen.
Vorerst einmal ohne eigenen “Empfindungen”.
Man könnte fast schon nur mit copy and paste (und neuen Bezeichnern) den Algorithmus so erweitern dass einfach „passend“ neue „Vektorräume“ für beliebige „psychische Dispositionen“ deklariert werden (und nicht nur für Wortbedeutungen).
Würde man womöglich auch noch irgendwann Empfindungen „realisieren“ können, wenn es z.B. möglich wäre zu erkennen welche „elektrischen Impulse“ (Ausschüttung von Elektronen) auf genau in der Nähe der o.a „Vektorräume“ platzierten chemischen Strukturen, z.B. auf „Elektronenbahnen“ (Kohäsionskraft) Einfluss nehmen könnten, die, von in diesem Fall elektronischen Auswertenetzwerk, z.B. als sexuelle Stimulation (Orgasmus) interpretiert werden.
Vermutlich käme es dann noch so weit, dass ein vielfältig gestaltetes und trainiertes KNN den ganzen lieben Tag lang immer nur an „das Eine“ denkt, was den Männern oft so unterstellt wird.