

Der „Fingerabdruck“ eines Songs

Trotz Sonntag wollte ich arbeiten. Stattdessen summte ich aber Google Assistant auf dem Smartphone Songs vor. Prompt bekam ich ihre Titel geliefert: Googles Songsuche fand auch in meinem unbeholfenen Summen den „Fingerabdruck“ eines Songs. Am Anfang meiner Spielerei war ein Ohrwurm gewesen: Manchmal wache ich auf, und schon ist ein Ohrwurm da. Vielleicht von den Vögeln draußen “hereingezwitschert”. Dieser Ohrwurm hatte mir sicher schon im Schlaf zugesetzt. Sonst wäre er nach dem Aufwachen nicht so präsent gewesen. Noch im Bett las ich dann über die neue Songsuche von Google – selbstverständlich Künstliche Intelligenz, besser gesagt: Deep Learning. Hätte ich da die neuronale Maschine nicht gleich an meinem Ohrwurm testen sollen? Diesen Ohrwurm verrate ich Ihnen am Ende dieses Beitrags.
Zuerst beschäftige ich mich etwas mit dieser neuen Erweiterung der neuronalen Songsuche von Google: Das Modell aus künstlichen neuronalen Netzen konnte meinem furchtbaren Brummen tatsächlich den „Fingerabdruck“ eines Songs entreißen. Mit diesem “Fingerabdruck” fand die Maschine den Song, der zu dem Fingerabdruck gehörte. Nicht immer, aber immer besser. Auch mein Summen wurde ja mit dem zunehmenden Training besser. Nicht erträglicher – wie die Schläge der Nachbarin auf unsere gemeinsame Wand und ihre gedämpften Schreie zeigten: „Es ist Sonntag, verdammt!“ Etwas besser aber schon!
Zumindest fand Google immer besser den „Fingerabdruck“ eines Songs in meinem Brummen. Was ist aber ein solcher Fingerabdruck? Kurz gesagt: Die Repräsentation einer Melodie. Allgemein gesagt: Die Repräsentation einer Klasse von Objekten, Sachen, Texten, Melodien oder von was auch immer. Der Begriff „Repräsentation“ ist in Deep Learning sehr wichtig. In meinem Buch über KI “Ist das intelligent oder kann das weg?” beschäftige ich mich damit anhand einiger Beispiele:

Generell ist eine Repräsentation die Vertretung einer Gesamtheit durch eine Gruppe. Die deutsche Fußballmannschaft stellt unsere Repräsentation bei der Fußball-WM dar. So wie die besten Fußballer ganz Deutschland repräsentieren, wird eine Datensatzklasse in einem tief lernenden neuronalen Netz (KNN – künstliches neuronales Netz) durch ihre besten (wichtigsten) Merkmale repräsentiert. Diese Merkmale lernt das KNN während seines Trainings. Sie definieren eben nur die Daten (bzw. Objekte, Texte usw.) dieser bestimmten Klasse. Auch wir Menschen erkennen Angehörige bestimmter Klassen nach ihren gemeinsamen Merkmalen:
Zum Beispiel ordnen wir ein Haustier mit kleinen spitzen Ohren und Schnurrhaaren der Klasse „Katzen“ zu. Dafür brauchen wir nur diese drei Merkmale: Haustier, spitze Ohren, Schnurrhaare. Schon diese drei Merkmale repräsentieren für uns die Klasse „Katzen“. Es gibt selbstverständlich noch mehr für uns erkennbare Merkmale, nach denen wir eine Katze erkennen. Uns reichen jedoch meist diese drei. Ein KNN lernt bei seinem Training mit Unmengen von Daten (Tausenden Katzenbildern) viele solche Merkmale. Nur sind diese Merkmale für uns viel schwieriger zu erkennen als die besagten spitzen Ohren oder Schnurhaare.
Die Merkmale eines KNNs sind Zahlen, die in der ersten verdeckten Schicht eines KNN-Modells winzige Striche in bestimmten Winkeln darstellen. Bei der Bilderkennung eines Elefanten zum Beispiel werden diese Striche in der zweiten verdeckten Schicht zu etwas größeren Linien und Kurven kombiniert. In der dritten verdeckten Schicht setzen sich diese zu noch abstrakteren Gebilden zusammen: Wie zu den großen Ohren eines Elefanten, an denen auch wir Menschen einen Elefanten erkennen würden. Bis die letzte Schicht des KNN-Modells den ganzen Elefanten zusammenlegt. So arbeitet auch unser visuelles System – hierarchisch. Für diese Entdeckung haben 1981 Torsten Wiesel und David Hummel den Nobelpreis bekommen.
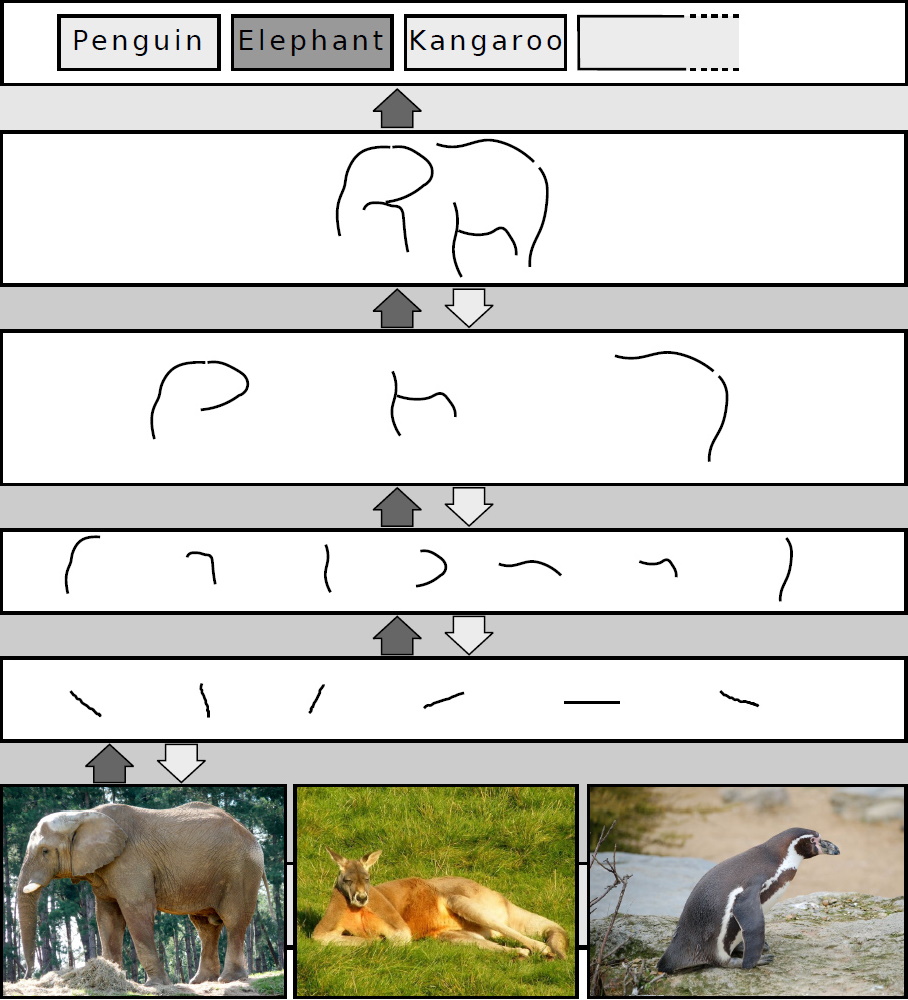
So hierarchisch lernt ein mehrschichtiges neuronales Netz Merkmale eines Elefanten: Je tiefer die Schicht des KNN-Modells, umso abstraktere Merkmale repräsentiert sie. Quelle: Wikimedia Commons/Sven Behnke (Bild geändert), CC BY-SA 4.0; https://commons.wikimedia.org/wiki/File:Deep_Learning.jpg
Somit ist ein tief lernendes neuronales Netz (deep learning neural network) ein universeller Klassifizierer. Es kann sehr komplizierte Abhängigkeiten der Ausgabewerte von seinen Eingaben finden. Je tiefer das Netz ist, je mehr verdeckte Schichten es also hat, desto komplexere Probleme kann es lösen.
Der altchinesische Philosoph Tschuang-Tse verglich das menschliche Denken mit einer sprudelnden Quelle: Je tiefer man grabe, desto frischer fließe sie. Ähnliches kann man über künstliche neuronale Netze sagen: Je tiefer sie sind, desto bessere Repräsentationen für bestimmte Klassen finden sie. Die Tiefe macht’s! Wenn es eine innere Repräsentation für einen Haufen Daten gibt, dann wird sie von einem tief lernenden neuronalen Netz gefunden: Diese Repräsentation ist das, was Äpfel zu Äpfeln macht, Krebstumore zu Krebstumoren, Sprache zur Sprache.
Genauso wie Bilder kann man Audiosignale von Songs in Zahlen zerlegen und ihre typischen Merkmale von einem KNN-Modell finden lassen – ihre Repräsentation eben. Und das ist der „Fingerabdruck“ eines Songs, den Googles neuronale Maschine bei ihrer Songsuche aus unserem Summen und Brummen herausfiltert. Mit diesen Merkmalen, dem „Fingerabdruck“ des Songs, vergleicht sie die „Fingerabdrücke“ von tausenden Songs, mit denen sie trainiert wurde. Dann sagt sie mir den Titel meines Ohrwurms: „All You Need Is Love.“ Leider kann damit meine Nachbarin nichts anfangen. Sie braucht am Sonntag ihre Ruhe.
Viel Spaß auf der Jagd nach dem Titel Ihres Ohrwurms!
willkommen auf meinem SciLogs-Blog "Gehirn & KI".
Ich möchte hier über alle möglichen Aspekte der Künstliche-Intelligenz-Forschung schreiben. Über jeden Kommentar und jede Diskussion dazu freue ich mich sehr, denn wie meine Mutter oft sagte:
"Solange die Sprache lebt, ist der Mensch nicht tot."
Neues über künstliche Intelligenz, künstliche neuronale Netze und maschinelles Lernen poste ich häufig auf meiner Facebook-Seite: Maschinenlernen
Hier etwas zu meiner Laufbahn: ich studierte Chemie an der TU München und promovierte anschließend am Lehrstuhl für Theoretische Chemie der TU über die Entstehung des genetischen Codes und die Doppelstrang-Kodierung in den Nukleinsäuren.
Nach der Promotion forschte ich dort einige Jahre lang weiter über den genetischen Code und die komplementäre Kodierung auf beiden Strängen der Nukleinsäuren:
Neutral adaptation of the genetic code to double-strand coding.
Stichworte zu meinen wissenschaftlichen Arbeiten: Molekulare Evolution, theoretische Molekularbiologie, Bioinformatik, Informationstheorie, genetische Codierung.
Zur Zeit bin ich Fachdozent für Künstliche Intelligenz an der SRH Fernhochshule und der Spiegelakademie, KI-Keynote-Speaker, Schriftsteller, Bühnenliterat und Wissenschaftskommunikator. Auf YouTube kümmere ich mich um die Videoreihe unserer SRH Fernhochschule "K.I. Krimis" über ungelöste Probleme und Rätsel der Künstlichen Intelligenz.
U. a. bin ich zweifacher Vizemeister der Deutschsprachigen Poetry Slam Meisterschaften.
Mein Buch „Doktorspiele“ wurde von der 20th Century FOX verfilmt und lief 2014 erfolgreich in den deutschen Kinos. Die Neuausgabe des Buches erschien bei Digital Publishers.
Mein Sachbuch über Künstliche Intelligenz "Ist das intelligent oder kann das weg?" erschien im Oktober 2020.
Im Tessloff-Verlag erscheinen meine von Marek Blaha wunderschön illustrierten Kinderkrimis "Datendetektive" mit viel Bezug zu KI, Robotern und digitalen Welten.
Viel Spaß mit meinem Blog und all den Diskussionen hier :-).
Jaromir
Zustimmung, künstliche und natürliche neuronale Netze (unser visueller Cortex beispielsweise) arbeiten bei der reinen Erkennung/Identifizierung von Objekten ähnlich: es werden von Neuronenschicht zu Neuronenschicht komplexere Muster herausgearbeitet bis schliesslich ein Gesamtmuster entsteht, das das Objekt identifiziert. Doch hier, also unmittelbar nach der Identifizierung des Objekts (beispielsweise einer Katze) beginnt der Unterschied. Für die meisten künstlichen neuronalen Netze ist mit dem Erkennen und Kategorisieren die Aufgabe erledigt, während wir Menschen eine erkannte Katze beispielsweise nun im physikalischen und Erlebnisraum animieren. Wir wissen beispielsweise, dass eine Katze ein 4-beiniges Tier ist, das sich bewegen kann und das einen bestimmten Bereich im 3D-Raum einnimmt. Wir wissen das nicht nur, wir ziehen auch unmittelbar Schlüsse daraus und schliessen etwa auf den Bewegungszustand der Katze, auf ihre Beziehung zur Umgebung und vieles mehr. Mit anderen Worten: mit dem unmittelbaren Erkennen des Objekts als Katze beginnt für uns die „Arbeit“ erst. Das Erkennen stösst Erinnerungen an und lässt uns Modellierungen vornehmen und so fort und so fort. Und ja, bei diesem Prozess wenden wir unbewusst auch Regeln an, wir bilden zudem eine Gedächtnisspur und verknüpfen das Erkannte mit früher Erlebtem.
Das sind lauter Dinge, bei denen heutige künstliche neuronale Netze Mühe haben oder sogar passen müssen.
Irgendwann werden diese komplexen Folgeprozesse nach dem Erkennen wohl auch von Systemen künstlicher Intelligenz durchlaufen. Doch jetzt liegt das bei den meisten KIs noch im Dunklen bezugsweise ist Gegenstand von Experimenten und Vermutungen.
Modelle aus künstlichen neuronalen Netzen (KNN) haben eben keinen gesunden Menschenverstand. Und darüber freuen sich viele. 🙂 Warum sollten Maschinen den gesunden Menschenverstand haben? Ich speziell bin ich mir nicht sicher, ob ich mich nach starker (allgemeiner) künstlicher Intelligenz sehne. Wir haben schon ein paar mal darüber diskutiert: KNN-Modelle verrichten viele Aufgaben mit übermenschlicher Performance. Das finde ich schon erstaunlich und GUT genug.
Hier gibt es aber eine andere Frage: Ist unser gesunder Menschenverstand nur das Ergebnis von im Laufe der Evolution perfekt angepassten neuronalen Netzen? Diese fangen gleich nach der Geburt aufgrund ihrer Verkörperung (ihres Embodiments) und unserer Sinne an, sich zu entwickeln. Unsere Sinne fluten ja diese Netze während unseres Lebens ununterbrochen mit Reizen aus der Umwelt. Dieses “Training” lässt unseren Wissensschatz, unsere Erfahrung und unseren gesunden Menschenverstand wachsen. Nur sind unsere Gehirnzellen (Neurone) keine Punkte in einem künstlichen neuronalen Netz, sondern funktionelle Einheiten, die selbst in ihren dendritischen Fortsätzen neuronale Netze bilden und eine erstaunliche Aktivität entfalten. Um solche Modelle künstlich zu bauen, brauchen wir noch ein paar Jahre. 🙂 Ob es aber erstrebenswert ist, künstliche Modelle zu erschaffen, die gscheiter sind als wir, ist dann noch eine andere Frage.
Na, ja, Angst habe ich nicht davor. Wie der KI-Pionier Yann LeCun sagte:
“Das Verlangen, die Weltherrschaft zu übernehmen, steht allerdings in keinem Zusammenhang mit Intelligenz, es hängt vom Testosteron ab. In der amerikanischen Politik gibt es heutzutage eine Menge Beispiele, die eindeutig zeigen, dass es keinen Zusammenhang zwischen Machtstreben und Intelligenz gibt.” 🙂
Intelligenz, Weltwissen, Weltverständnis, Wissen wie die Dinge funktionieren und wie sie sich Abläufe und Ereignisse beeinflussen, gar steuern lassen sind einfach Voraussetzungen für höhere Aufgaben wie Planung oder das Formen und Verfolgen eigener Ziele. Warum aber sollte das Endziel einer Kreatur, die die Welt, die Dinge und Menschen versteht, Macht bis hin zur Weltherrschaft sein? Zu diesem Schluss kommt man in der Tat nur aus einer mennschlich/evolutiven Perspektive.
In meinen Augen brauchen wir echt intelligente künstliche Intelligenz damit KI nicht nur den Konzernen/Regierungen helfen kann, die uns eh schon mit ihren Daten über uns manipulieren. Echt intelligente Assistenten dagegen könnten wie Freunde für jeden Einzelnen von uns sein und uns in jeder Lage helfen.
Für Josch Bach, den Vertreter der kognitiven Intelligenz, der sich beseelte Maschinen vorstellen kann, ist Intelligenz die Fähigkeit Modelle zu bilden und Bewusstsein ist die Fähigkeit das Bilden von Modellen nachvollziehen zu können und die Aufmerksamkeit auf interessierende Aspekte zu fokussieren.
Es stimmt aber, dass Deep Learning in all seinen Varianten auch heute schon Prozesse und den Erkenntnisgewinn in Gesellschaft, Wissenschaft und Technik beschleunigt. Beispielsweise über die Vorhersage von Materialegenschaften aus chemischen Formeln oder gar die Konstruktion von chemischen Formeln für Materialien mit gewünschten Eigenschaften. Was früher ganze Karrieren von Chemikern beanspruchte macht ein Deep Learning Netz heute quasi über Nacht.
Doch es gibt auch Projekte in die unzählige Arbeitsstunden gesteckt werden und die an den Beschränkungen von Deep Learning zu scheitern drohen. Dazu gehört beispielsweise das Bemühen selbstfahrende Autos zu schaffen. Denn Perzeption und Klassifizierung genügen dabei nicht. Zudem machen heutige KI-Systeme beim Erkennen von Objekten hin und wieder Fehler, die Menschen nie unterlaufen würden und die ihre Einsatzfähigkeit in Frage stellen.
Normalerweise höre ich jeden Abend Musik. In meinem Telefonspeicher befindet sich eine Liste mit MP3-Musik, um Offline-Musik zu hören. Ich benutze es als Klingelton (着信ー音) auf meinem Smartphone.
Diesen “Fingerabdruck” können sie nur über die Sinne wahrnehmen, unserem Tor zur Außenwelt. Künstliche Netze haben keine Sinne, also keine Bewertung der Außenwelt. Der Begriff Finger-Abdruck beinhaltet einen “Fühler” und eine Sinneswahrnehmung, nämlich den Ab-Druck. Ihr Ohrwurm benötigt ein Ohr und den Wurm, nämlich ihr neuronales Netz was gerade für diesen Song sensibilisiert wurde . Es besteht also ein kausaler Zusammenhang zwischen Wahrnehmung und Sensibilisierung. Neuronale Netze können auch ein Menschengesicht erstellen aber das, was ein solches Gesicht geprägt hat, nämlich ein LEBEN voller positiver und negativer Ereignisse, kann nicht nachvollzogen werden. Ansonsten halte ich den Zusammenhang zwischen Testosteron und Weltherrschaft für sehr weit hergeholt. Trump ist nicht nur ein Produkt seines Testosteronspiegels sondern auch des Kapitalismus mit seinem maßlosen die Umwelt zerstörenden Profitdenken. Die (Umwelt)Katastrophe findet also in den neuronalen Netzen statt, die von diesem Denken geprägt wurden.
Doch: die Bewertung der Sinneswahrnehmung geschieht in künstlichen neuronalen Netzen durch das Training. Im Training werden die bei der Sinnesverarbeitung auftauchenden Muster einem bestimmten Objekt zugeordnet. Etwas, was aus Blech, Glas und Rädern besteht wird so als Auto erkannt.
KI-Systeme beispielsweise in einem selbstfahrenden Auto haben Kameras, Radar und Sonar als Sinnesorgane und die Muster, die beispielsweise das Bild eines entgegenkommenden Autos in den aufeinanderfolgenden Schichten eines neuronalen Netzwerks erzeugt, werden dann aufgrund früher gelernter Bewertungen in Trainingsläufen dazu benutzt das entgegenkommende Fahrzeug beispielsweise als Lastwagen, gewöhnliches Auto oder Motorrad mit Seitenwagen zu erkennen. Der „Fingerabdruck“ um einen Lastwagen zu erkennen könnte beispielsweise die Kombination von hoher Front mit grossen Rädern sein.
Klar weiss das künstliche neuronale Netz im Prinzip praktisch nichts über die Aussenwelt. Es kann nur wiedererkennen wofür es trainiert wurde und das Training besteht einfach darin, dass man ihm x Beispiele etwa von Fahrzeugen oder von Songs zur Verarbeitung gibt. Wenn man will, dass das künstliche Netz etwa den Song „All You Need Is Love.“ auch dann erkennt, wenn er ganz fürchterlich gekräht wird, dann muss man ihm eben auch ganz fürchterliche Versionen von „All you need is Love“ vorspielen.
Training nur mit allzu perfekten Trainigsbeispielen führt zum sogenannten Overfitting. Es bedeutet, dass das KI-Programm erwartet, dass einfach alles stimmen muss. Beim Song „ All you need is Love“ etwa die Tonhöhe, das Timbre und Vieles mehr. Umgekehrt können allzu verwaschene Trainigsbeispiele bewirken, dass das Programm verschiedene Songs nicht auseinanderhalten kann.
Bewertung gibt es bei KI also durchaus. Das Training bestimmt was ein menschliches Gesicht ist oder nicht. Ein KI-Programm weiss nur gerade was ihm per Training beigebracht wurde. Ansonsten sind KIs Tabula rasa, „blank sheets of paper“.
Martin Holzherr: “Training nur mit allzu perfekten Trainigsbeispielen führt zum sogenannten Overfitting.”
Jaromir: Lieber Herr Holzherr, das ist gerade umgekehrt. “Zu komplexe” KNN-Modelle mit sehr vielen Parametern erleiden “Overfitting” vor allem dann, wenn sie mit verrauschten Datensätzen trainiert werden. Sie erkennen nun mal Merkmale (Features), wo es diese nicht gibt, und können nach dem Training nur die Daten memorieren, mit denen sie trainiert wurden. An Testbeispielen versagen sie – sie können nicht verallgemeinern. Dem kann man begegnen, indem man den Datensatz erweitert, oder das Modell mit Dropout u. a. Methoden weniger komplex macht.
Martin Holzherr: “Beim Song „All you need is Love“ etwa die Tonhöhe, das Timbre und Vieles mehr. Umgekehrt können allzu verwaschene Trainigsbeispiele bewirken, dass das Programm verschiedene Songs nicht auseinanderhalten kann.”
Jaromir: Ein Fingerabdruck ist ein Fingerabdruck :-). Sein Muster bleibt gleich, auch wenn die Hände schmutzig oder die Finger verletzt sind. Den “Fingerabdruck” eines Songs (einer Melodie), den ein KNN-Modell aufdeckt, bilden viel feinere Merkmale, als dass der Mensch sie definieren könnte. Deswegen können gut trainierte KNN-Modelle auch Songs erkennen, wenn diese falsch gesungen werden.
@Jaromir Konecny: Was für ein Fingerabdruck entsteht hängt meiner Ansicht vom Trainingsset ab (und von ein paar weiteren Faktoren). Von Overfitting (zu sensibel) und Underfitting können Fingerabdrücke geplagt sein, wenn das Trainingsset nicht repräsentativ für die Aufgabe ist. Der Fingerabdruck wird vom KNN tatsächlich selbst erstellt – basierend auf den Trainingsdaten und ein paar Hyperparametern.
Der Begriff “Fingerabdruck” wird hier symbolisch für ein Muster verwendet, das einer Klasse eigen ist und diese Klasse spezifisch kennzeichnet: Hier die Klasse aller wie auch immer gesummten, gesungenen und anderswie dargebrachten Arten eines bestimmten Songs. Ich glaube, hier muss man nicht weiter philosophieren. 🙂
@Konecny – off topic
Neuronale Netze fangen beim Menschen nicht erst ab der Geburt an, sich zu entwickeln – sondern sind schon beim Fetus aktiv.
z.B. reagiert ein Fetus auf identische Geräuschreize weniger stark, wenn er sie öfter hört. Dieser Effekt heisst ´Habituation´. Offenbar speichert er neue Reizmuster im Gedächtnis – und wenn der gleiche Laut nochmals kommt, dann kennt er ihn bereits.
Unsere physikalischen Sinne Tastsinn, Hörsinn, Sehsinn werden durch physikalische Reize stimuliert (Wärme/Druck, Schalwellen, Licht). Erlebnisse ab dem 5. Schwangerschaftsmonat sind lebenslang dem bewussten Erinnern zugänglich – wobei deutlich die Reihenfolge der Entwicklung der physikalischen Sinne erkennbar ist.
Auch dies deutet darauf hin, dass neuronale Netze schon beim Fetus aktiv arbeiten.
Ja, da haben Sie recht. Das war von mir falsch ausgedrückt. Selbstverständlich gibt es auch beim Fötus neuronale Netze. Schon ein paar Gehirnzellen bilden einen Neuronenverband, der dann an Reizen weiter trainiert und entwickelt wird, die der Fötus aus seiner Umwelt erfährt – dem Bauch seiner Mutter. Bei diesem Training und bei dieser Entwicklung gibt es außerdem ein komplexes Zusammenspiel mit dem Genom des Fötus, also mit allen Genen und allen Steuerelementen in seiner DNA, die der Fötus in seinen Chromosomen geerbt hat und die schon jetzt im Mutterleib exprimiert werden und funktionell sind. Auf jeden Fall handelt es sich hier um ein komplexes sich selbst organisierendes System, das jedes noch so große künstliche neuronale Netz als eben das erscheinen lässt, was es ist – ein mathematisches Optimierungsverfahren.
Wenn Perzeption Kognition erfordert
Einfache KI-Systeme erkennen Objekte in Bildern allein aufgrund ihres „Finerabdrucks“, eines Musters, das das Objekt charakterisiert. Doch das kann in die Irre führen. Ein Bild von Sarkozy auf einem vor mir fahrenden Lastwagen ist beispielsweise kein Fussgänger, auf den das selbst fahrende Auto Rücksicht nehmen muss. Und dass der Schatten, der von meinen Fahrrad gerade auf den Boden geworfen wird, kein Objekt ist auf das ich Rücksicht nehmen muss, das weiss ich, aber scheinbar weiss das der Tesla-Fahrassistent nicht immer. Der Tesla-Fahrassistent macht hin und wieder Phantom-Stopps wegen Schatten auf der Strasse oder weil die Strassenfarbe plötzlich von grau auf schwarz wechselt.
@Holzherr
Um die beschriebenen Probleme des Tesla-Fahrassistenten zu lösen, braucht es keine Kognition – sondern nur geeignete Sensoren. Schatten oder Farbwechsel kann man z.B. mit Radar von realen Objekten unterscheiden – weil damit erkannt werden kann, ob auch die Dimension ´Höhe´ vorhanden ist.
Dem ist so, und deswegen konnte Waymo jetzt seine autonomen Fahrzeuge ohne Sicherheitsfahrer auf die Menschheit loslassen:
https://blog.waymo.com/2020/10/waymo-is-opening-its-fully-driverless.html
Ich bin sicher, dass in zehn Jahren die meisten Autos dank “Deep Learning” autonom fahren. Obwohl ihre Steuerungsprogramme keinen gesunden Menschenverstand haben. 🙂
@Jaromir Konecny: Wenn sie Waymo mehr Chancen beim Rennen zum selbstfahrenden Fahrzeug geben als Tesla, dann fehlt auch ihnen das Vertrauen in die Kombination von Kamera und Deep Learning, auf die Tesla vertraut. Zurecht. Elon Musk hat zwar in einem Punkt recht: Dem Menschen genügen Augen 👀 zum fahren. Er hat aber unrecht, wenn er glaubt auch dem selbstfahrenden Auto genüge das. Der Artikel AAA testing finds driver-assistance tech is ‘far from reliable’ berichtet über Tests mehrer Fahrzeugassistenten mit dem Resultat, dass sie unzuverlässig sind und oft nicht einmal bremsen, wenn vor ihnen ein defektes Fahrzeug einfach auf der Strasse steht. Zitat:
Allen, die einmal sehen wollen wie schwierig Autofahren ist, empfehle ich folgendes Video, welches einen britischen Teslafahrer mit eingeschaltetem Fahrassistenten auf britischen Strassen zeigt: Can Full Self Driving BETA fix all these issues ?
Die interessanten Stellen sind hier mit den Zeitpunkten im Video aufgelistet:
Das Video 75 Minutes of Autonomous Driving with Kyle Soft and Sam Altman zeigt ein autonomes Auto in San Franzisko, welches sehr schwierige Situationen meistert und beinahe menschliches Niveau erreicht. Das Resultat jahrelanger ständiger Verbesserung.
Das hier gezeigte System arbeitet mit mehreren Lidars.
Deep Learning und selbstfahrende Fahrzeuge
Sowohl bei Tesla wie bei Waymo spielt Deep Learning in ihren selbstfahrenden Fahrzeugen eine wichtige Rolle, vor allem bei der Perception/Klassifikation, aber es gibt auch manuell erstellten Code und andere Softwaremodelle als nur Deep Learning in Teslas und Waymos Software, denn Deep Learning allein kann die Komplexität des Autofahrens bis jetzt nicht bewältigen.
Wenn @KRichard weiter unten schreibt, eine 1 cm dicke Schneedecke habe ein selbstfahrendes Auto schon versagen lassen, zeigt das ein wichtiges Problem: die Vielfalt der Situationen, Variationen die sich mit wechselndem Wetter, den Jahres- und Tageszeiten (Tag und Nacht) ergeben. Dieses Problem kann auf der Deep Learning Seite einfach mit mehr Trainingsdaten (teil-)gelöst werden. Tesla behauptet diesbezüglich im Vorteil zu sein, weil es viele Milliarden von Fahrkilometern aufgezeichnet hat.
Nicht alles beim autonomen Fahren kann aber Deep Learning erledigen. Dazu gehört etwa das Beherrschen der Verkehrsregeln.
Wie im Artikel Why deep learning won’t give us level 5 self-driving cars argumentiert wird besitzt der Mensch aber über eine Vielzahl von Fähigkeiten, die von Deep Learning Systemen nur schwer emuliert werden können. Das intuitive Physikverständnis des Menschen lässt uns etwa mit Schnee auf der Strasse auch dann umgehen, wenn sich dadurch Situationen ergeben, die wir noch nie gesehen haben, wie etwa eingeschneite Verkehrszeichen. Während Deep Learning in einer solchen Lage verloren wäre, kann. ein Mensch etwa allein aus der Tatsache, dass ein eingeschneites Verkehrszeichen am Ortseingang steht, schliessen, dass es eine Gescheindigkeitsbeschränkung sein muss. Folgender Satz aus dem verlinkten Artikel fasst das zusammen:
Fazit: Selbst fahrende Autos werden noch lange nicht die Fahrkompetenz eines professionellen, voll konzentrierten Fahrers erreichen. Trotzdem können sie besser als der Durchschnittsfahrer sein, allein schin weil sie nicht betrunken oder abgelenkt sind.
Warum Deep Learning Inferenz schnell aber speicherhungrig ist
Das Trainieren einer anspruchsvollen Deep Learning Anwendung kann soviel Strom brauchen wie eine kleine Stadt in einigen Tagen verbraucht.
Ist die Deep Learning Anwendung aber einmal trainiert kann sie Objekte blitzschnell erkennen – vorausgesetzt sie verfügt über genügend schnellen Speicher.
Warum ist das so? Nun, das liegt daran, dass das Gelernte in Form eines riesigen Datenbergs von Gleitkommazahlen vorliegt. Jede Gleitkommazahl bestimmt wie stark einer der Eingänge eines der Neuronen des künstlichen neuronalen Netzes gewichtet wird. Gewichtung bedeutet, wie stark die Signalstärke des Eingangs verstärkt oder abgeschwächt wird.
Selbst eine so kleine Anwendung wie ImageNet hat in der Implementation von NVIDIA 650‘000 Neuronen und 60 Millionen Gewichte (auch Parameter genannt). Würde man alle Gewichte als Gleitkommazahlen doppelter Genauigkeit speichern bräuchte ImageNet bereits 480 MegaByte an schnellem Speicher.
Anwendungen im Bereich selbstfahrender Autos benötigen aber noch viel mehr schnellen Speicher. Zudem müssen diese Daten, diese Gewichtungen, bei jedem einzelnen Bild, dass die Deep LearningAnwendung verarbeiten soll, geladen werden. Das heisst, es müssen viele Megabyte an Daten jede Zehntelssekunde vom Speicher in den Prozessor geladen werden und der Cache hilft dabei fast gar nichts, weil es zuviele Daten sind um sie im Cache zu halten.
Das ist der Grund, dass man heute überlegt, wie man das Laden der Daten vermeiden könnte. Beispielsweise indem man Speicher und Prozessor nicht mehr trennt, denn heute sind diese beiden Computerbestandteile räumlich voneinander getrennt.
Für Teslas Full Self Driving Computers Speicherzugriffsgeschwindigkeit gilt (Zitat):
Es können also bis zu 68 Milliarden Bits pro Sekunde vom Speicher geladen werden.
@Holzherr
Mit dem Hinweis auf die Datenmenge sprechen Sie ein großes Problem von KI-Anwendungen an.
Von KI-Anwendungen erwartet man, dass diese immer 100 %ig perfekt fehlerfrei funktionieren. Selbstfahrende Autos dürfen z.B. keinen einzigen Menschen übersehen und überfahren.
(Wie schlecht die menschliche Wahrnehmung funktioniert, zeigte das ´Gorilla-Experiment´ von Chabris/Simons: Dabei wurde eine als Gorilla verkleidete Person nicht ´gesehen´ – obwohl sie sich im gezeigten Film direkt vor der Kamera befand.)
Bei uns im Landkreis wurden Versuche mit einem selbstfahrenden Auto durchgeführt um Erfahrungen zu sammeln. Eine Erfahrung war, dass bereits eine Schneehöhe von 1 cm die Orientierung des Fahrzeuges lahmlegte – denn damit fehlten wichtige optisch erkennbare Oberflächenstrukturen.
Wenn der Fingerabdruck täuscht
Deep Learning erkennt Objekte ähnlich wie wir an objekttypischen Merkmalen. Ein Oval mit Augen, Nase, Mund und Ohren ist also für ein Deep Learning System ein Gesicht. Doch anders als der Mensch ist für ein Deep Learning System ein Gesicht immer noch ein Gesicht, wenn Augen und Mund vertauscht sind und die Nase ganz woanders ist. Damit sind Deep Learning Systeme zwar in der Lage beispielsweise Gesichter oder Verkehrszeichen zu erkennen, doch sie neigen auch zu Fehlerkennungen, die Menschen nie passieren würden. Darüber berichtet auch der Nature-Artikel Why deep-learning AIs are so easy to foo. Dort liest man (übersetzt von DeepL):
Wie @Jaromir Konecny oben im Artikel und den Kommentaren geschrieben hat, bestimmen Künstliche neuronale Netze den „Fingerabdruck“ eines Objekts eigenständig und anhand von eventuell ganz anderen Merkmalen als das der Mensch machen würde (Zitat): Den “Fingerabdruck” eines Songs (einer Melodie), den ein KNN-Modell aufdeckt, bilden viel feinere Merkmale, als dass der Mensch sie definieren könnte.
Doch qenau das, die Tatsache, dass KNNs Objekte nicht auf die gleiche Art und Weise erkennen wie Menschen macht ihre Anwendung auch problematisch, denn es bedeutet, dass Fehlerkennungen eines KNNs für den Menschen schwer nachvollziehbar sind. Und viele KI-Ingenieure sind der Meinung, dass dieses Problem nicht ohne weiteres korrigierbar ist (Zitat):
Fazit: Von heutigen KNNs dürfen wir keine robusten Leistungen bei der Objekterkennung erwarten. Da tröstet uns nur, dass auch Menschen Erkennungsfehler machen.