

AlphaFold und die Wissenschaft der Jäger und Sammler
BLOG: Gehirn & KI

Haben Sie vor kurzem den Knall gehört? Mit ihrem Program AlphaFold hat die Google-Firma DeepMind eine Bombe gezündet und ließ es in der Molekularbiologie ganz schön krachen. Vielleicht wurde da aber keine Bombe gezündet, sondern eine Rakete, die uns in ein neues Zeitalter der Naturwissenschaften fliegt:
Deep Minds AlphaFold – ein Modell aus künstlichen neuronalen Netzen – errang vor kurzem den ersten Platz der renommierten Bewertung von Programmen zur Proteinstruktur-Vorhersage (CASP – Critical Assessment of Structure Prediction). Bereits zum 13ten Mal fand das CASP-Biennale statt. 98 Programmen wurden von CASP bewertet. AlphaFold konnte 25 von 43 Proteinstrukturen richtig voraussagen. Das zweitplatzierte Programm sagte nur drei Proteinstrukturen richtig voraus. Eine solche Distanz zwischen dem Erst- und Zweitplatzierten ist bei CASP beispiellos.
Warum ist das so wichtig? Die 3-D-Struktur eines Proteins ist der Heilige Gral der Molekularbiologie und der Bioinformatik: Wenn wir wissen, welche Gensequenzen zu welchen Proteinstrukturen führen, können wir besser die Biologie der Organismen verstehen und viele Krankheiten heilen. Doch nicht nur das! Dann können wir auch gezielt Protein-Werkzeuge für zahlreiche andere Anwendungen bauen: Richtig entworfene Proteine zerlegen Plastik und Öl. Was würden solche Werkzeuge für den Klimaschutz bedeuten?
Dass künstliche neuronale Netze so effizient die Molekularbiologie vorantreiben können, hat aber auch eine symbolische Bedeutung für alle anderen Forschungsgebiete: Indem AlphaFold ein großes wissenschaftliches Problem meisterte, hat das Programm das Tor zum Gralstempel jeder Wissenschaft breit geöffnet: Das wissenschaftliche Werkzeug der Zukunft ist das künstliche neuronale Netz. Warum kam ich dann bei dieser schönen Aussicht gleich mit einer Bombe? Das erkläre ich auch. Wenn Sie mir etwas Geduld schenken, um die ganze Geschichte abzuwickeln.
DeepMinds AlphaTiere

Wenn ich über eine neue Errungenschaft der Google-Firma DeepMind erfahre, fällt mir oft der Spruch des Mitentdeckers der DNA-Doppelhelix und Nobelpreisträgers Francis Crick ein:
„So etwas wie Glück gibt es nicht, sonst würden es nicht immer dieselben Leute haben.“
DeepMind scheint eine Menge Glück zu haben. Seine AlphaTiere unter den künstlichen neuronalen Netzen leiten uns so schnell in neue Zeiten, dass manchen die Puste wegbleibt: Das erste Programm der Alpha-Reihe, AlphaGo, schlug weltbeste Spieler des hoch intuitiven chinesischen Spiels Go, indem es Go aus Tausenden menschlichen Go-Partien gelernt hatte. Das Folgeprogramm AlphaGo Zero brauchte keine menschlichen Partien mehr, sondern spielte Go so lange gegen sich selbst, bis es seinen Vorgänger AlphaGo bei jedem Spiel besiegte. Das dritte Programm der Reihe AlphaZero schlug nicht nur seinen Vorgänger AlphaGo Zero im Go, sondern auch weltbeste Schachprogramme, gegen die menschliche Schachweltmeister schon seit Jahren keine Chance haben. Und jetzt hat AlphaFold alle anderen Programme alt aussehen lassen, mit deren Hilfe Bioinformatiker und Molekularbiologen seit über 50 Jahren das Geheimnis der Proteinfaltung ergründen wollen. DeepMind, eine Google-Firma, die noch vor kurzem mit Biochemie nichts am Hut hatte, bewältigte nach nur zwei Jahren Arbeit am Alpha-Fold-Projekt ein wichtiges Problem der Biochemie. Und das viel besser als akademische Biochemieinstitute auf der ganzen Welt nach 50 Jahren Forschung.
Nukleinsäuren → Proteine → Leben
Bevor wir uns aber mit AlphaFold auseinandersetzen, sollten wir ein wenig in die Molekularbiologie tauchen: Proteine (Eiweiße) sind die funktionellen Einheiten der Zellen, ihre Geräte und Maschinen: Sie transportieren Stoffe, als Rezeptoren vermitteln sie die Übertragung von Signalmolekülen, sie katalysieren chemische Reaktionen, erkennen als Antikörper Schadstoffe, schneiden und verbinden DNA- und RNA-Ketten, als Strukturproteine sind sie die wesentlichen Bausteine von Zellen, als Chaperone helfen sie bei der Faltung anderer Proteine. In irgendeiner Form sind Proteine an jedem biologischen Vorgang beteiligt. Dabei führen viele „falsch“ gefaltete Proteine zu schweren Krankheiten, wie zu Alzheimerdemenz oder Morbus Parkinson. Wenn wir das Geheimnis der Proteinstruktur und deren Funktion in Organismen entschlüsseln, können wir maßgeschneiderte Medikamente für den ganzen Körper entwickeln.
Im Grunde sind Proteine lange Ketten von aneinander gebundenen Aminosäuren. Diese Aminosäuren sind in der DNA kodiert – in unseren Genen. Die DNA ist eine Folge von vier Nukleotiden (siehe folgendes Bild). Jeweils ein Nukleotid-Triplett (ein Codon) kodiert eine kanonische Aminosäure. Bei 4 möglichen unterschiedlichen Nukleotiden auf 3 Plätzen (Triplett) gibt es 64 verschiedene Codone (43 = 64), die Aminosäuren kodieren können. Da wir aber nur 20 kanonische Aminosäuren haben, die durch den genetischen Code kodiert sind, geht bei der Übersetzung eines Gens in ein Protein Information verloren: Ein Alphabet aus 64 Einheiten (Codonen) wird in ein Alphabet aus 20 Einheiten (Aminosäuren) übersetzt. Somit wird jeweils eine Aminosäure durch mehrere Codone kodiert. Die 21te Aminosäure, die in vielen Organismen auftritt, Selenocystein, ist eine Ausnahme. Selenocystein ist nicht direkt im genetischen Code kodiert, sondern wird manchmal durch ein sogenanntes Stop-Codon bestimmt, bei dem der Transkriptionsvorgang normalerweise unterbrochen wird.

Kodierung eines Proteins im Doppelstrang der DNA: Ein Strang kodiert ein Gen, der andere Strang ist aufgrund der Nukleotid-Paarung komplementär, hat also (meist) keine Kodierungsfunktion, und „deckelt“ nur. Jeweils einem Nukleotid-Triplett der DNA wird eine Aminosäure eines Proteins (unten) zugeordnet: G (Guanin), C (Cytosin), A (Adenin), T (Thymin). Proteinkette aus Aminosäuren: Ala (Alanin), Arg (Arginin), Asp (Asparaginsäure), Asn (Asparagin), Cys (Cystein). Quelle: Public Domain – Wikimedia Commons.
Bei der Transkription und Translation eines Gens in ein Protein (über die Boten-RNA und Transfer-RNA) bildet sich also eine Kette aus Aminosäuren. Wenn Molekularbiologen nur aufgrund einfacher Aminosäuren-Ketten Medikamente zimmern könnten, bedürfte es keines AlphaFolds. Solche geraden Proteinketten würden jedoch keine Aufgaben erfüllen können. Sie entsprechen nur den aneinander gereihten Ersatzteilen eines Autos. Erst wenn die Ersatzteile zu einer funktionellen Einheit zusammengeschraubt werden, kann das Auto fahren.
Zu einer “biologischen Maschine” muss sich ein Protein erst falten – in seine komplexe dreidimensionale Struktur mit Taschen, Fallen, Andockstellen, chemischen Scheren u. a. funktionellen Einheiten. Eine Proteinstruktur als „Schloss“ beim Schlüssel-Schloss-Prinzip einer enzymatischen Reaktion ist ein bekanntes Beispiel dafür:
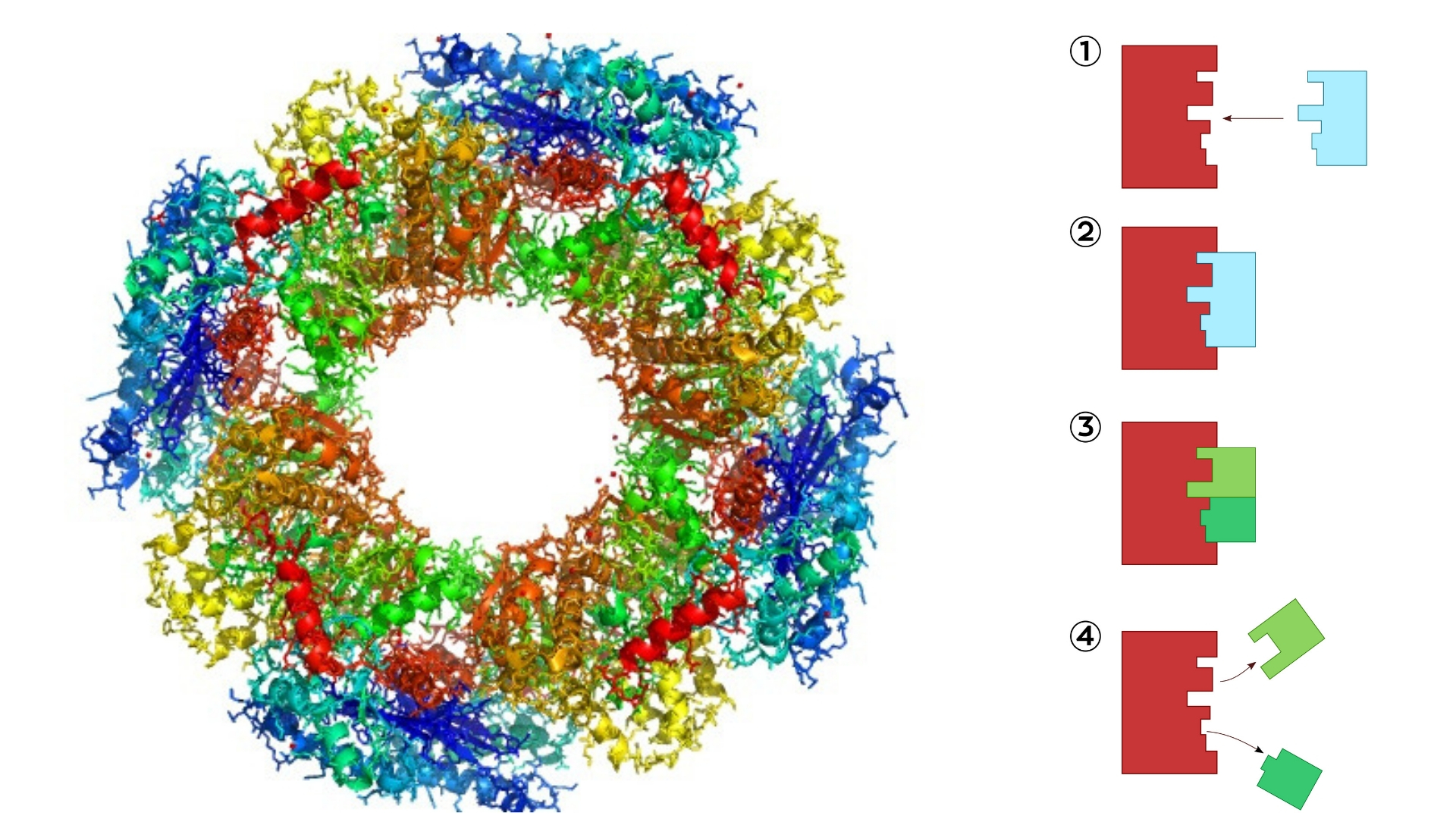
Links: 3-D-Struktur – Protein/Enzym Butyrat Kinase. Quelle: Wikimedia Commons. Autor: Awapuhi Lee. Rechts: Das Schlüssel-Schloss-Prinzip einer enzymatischen Reaktion: Ein Enzym ist (meist) ein Protein, das biochemische Reaktionen ermöglicht und beschleunigt (katalysiert). Das zu reagierende Molekül (Substrat – Schlüssel) dockt an der Oberfläche einer Proteinstruktur (Schloss) an (1, 2), reagiert zu neuen Substraten (3), die von diesem Protein (Enzym) wieder freigesetzt werden (4). Quelle: Wikimedia CommonsAutor: domdomegg.
{kind=link}
Während seiner Faltung strebt ein Protein seinen niedrigsten energetischen Zustand an. So wie ein gespanntes Gummiband. Erst nach dem Loslassen rollt es sich zusammen. Nur gibt es in einer Proteinkette zahlreiche Stellen – Aminosäuren. Sie wechselwirken bei der Faltung zusammen, ziehen sich an bzw. stoßen sich ab. Im wässrigen Milieu einer Zelle wird die Faltung eines Proteins außerdem durch die Abkehr seiner Bereiche mit wasserabstoßenden (hydrophoben) Aminosäuren ins Innere des gefalteten Proteins angetrieben.
Levinthal’s Paradox
Schon während meiner Forschung über die genetische Kodierung in den 90ern am Lehrstuhl für Theoretische Chemie der TU München haben wir oft über Proteinfaltung nachgedacht und diskutiert: Wie könnte man aus der Nukleotiden-Sequenz eines Gens die dreidimensionale Struktur des durch dieses Gen kodierten Proteins voraussagen?
Die Schwierigkeit dieser Aufgabe veranschaulicht das Levinthal-Paradox, ein Gedankenexperiment, das Cyrus Levinthal im Jahr 1969 aufstellte: Auch bei der Annahme, eine Aminosäure einer Proteinkette könne nur zwei verschiedene Positionen im Raum einnehmen, stellt die Proteinfaltung ein ausuferndes kombinatorisches Problem dar: Schon bei einer Kette von 200 Aminosäuren könnte das Protein 2200 mögliche verschiedene Konformationen (Strukturen) einnehmen, bevor es in der energetisch günstigsten landen würde.
Dieses Energie-Tal des Proteins kann man sich wie ein Murmelloch in einem leicht schiefen Boden vorstellen. Je höher die Kugel liegt, umso mehr Energie hat sie. Sollte die Kugel in einer kleinen Senke landen, rollt sie sofort weiter nach unten, wenn man sie wieder anschiebt. Dank der Gravitationskraft ist die Kugel bestrebt, den Zustand ihrer niedrigsten Energie zu erreichen – den Boden des Murmellochs. So wie ein Protein sein „Energietal“ zu erreichen versucht, nicht aber durch die Kraft der Gravitation, sondern aufgrund diverser molekularer Kräfte in seiner Kette.
Auch wenn das Protein nur 2-13 Sekunden für das „energetische Ausprobieren“ einer Struktur brauchen würde, wären für alle mögliche Strukturen insgesamt 2200 x 2-13 Sekunden notwendig. Das heißt 2200 x 10-13 / (60 x 60 x 24 x 365) Jahre. Das macht etwa 4,5 x 1024 Jahre aus – so lange lebt keine Zelle, nicht einmal das Universum ist so alt. Wieso liegt ein Protein trotzdem innerhalb kürzester Zeit nach seiner Herstellung in der Zelle in seiner funktionellen dreidimensionalen Struktur vor? Wie konnte es so schnell seinen energetisch niedrigsten Zustand einnehmen, wenn diese Aufgabe zeitlich nicht zu bewältigen ist?
Die Lösung des Rätsels ist relativ einfach: Das Protein faltet sich sofort bei seiner Herstellung in der ribosomalen Fabrik der Zelle: Mit jeder neuen zugefügten Aminosäure sucht das Molekül nach seiner energetisch niedrigsten Konformation. Es muss also nicht alle möglichen Strukturen des gesamten Proteins durchlaufen, sondern geht durch lokale Energie-Täler durch. Wenn ein solches lokales Minimum tief genug ist, so dass keine molekularen Kräfte dieses Protein aus diesem Minimum hinaushieven können, bleibt das Protein in dieser Struktur gefaltet. Dieser Vorgang der Faltung findet in der Zelle mit Hilfe der oben erwähnten Chaperone statt. Sie helfen anderen Proteinen, eine funktionierende Struktur im Zustand niedrigster Energie zu bilden. Sie spielen für das Protein den Zeigefinger, der die Murmel anschiebt.
CASP und das Rennen um die Trophäe
Die Proteinfaltung ist ein komplexer Vorgang, bei dem eine Menge Parameter eine Rolle spielt. Proteinstrukturen wurden in den letzten 50 Jahren mit Hilfe von kostspieligen und zeitaufwändigen experimentellen und spektroskopischen Methoden ermittelt. Diese erfordern viel mühsame Arbeit – vieles davon nach dem „Trial & Error“-Prinzip – und sind teuer: Große Maschinen, viel Aufwand. Hier mussten Programme her.
Damit bei der internationalen Bewertung der besten Voraussagen von Protein-3D-Strukturen CASP nicht geschummelt wird, müssen die wetteifernden Programme 3-D-Proteinstrukturen bestimmen, die kurz vor ihrer experimentellen Ermittlung stehen. Die Struktur-Vorhersagen werden von den Teams eingereicht, bevor die Strukturen veröffentlicht werden.
Viele Proteinfaltungs-Programme verwenden sogenannte Templates (Vorlagen): Protein-Strukturelemente von bekannten 3-D-Strukturen. An diesen Vorlagen richten die Programme die Strukturelemente des Proteins aus, dessen Gesamtstruktur ermittelt werden soll. Beim Homologie-Verfahren bedient man sich bekannter Strukturen von homologen Proteinen. Sie haben eine ähnliche Aminosäuresequenz wie das zu erforschende Protein. Hier kann man sich über die verschiedenen Methoden informieren.
Der Königsweg wäre selbstverständlich, die Struktur eines Proteins direkt aus seiner Aminosäuresequenz und der physikalischen Eigenschaften dieser Aminosäuren zu berechnen. Das heißt, die Struktur der minimalen freien Energie des Moleküls aufgrund seiner physikalischen Eigenschaften zu suchen. Dieser Königsweg ist aber so rechenintensiv und komplex, dass ihm mit einem Brutforce-Verfahren nicht beizukommen ist. Den Königsweg kann nur ein Modell aus künstlichen neuronalen Netzen nehmen, das sich die wichtigen Merkmale in den vielen Daten selbst sucht, mit denen es rechnen muss.
Trotzdem passierte in den letzten Jahren in der Proteinfaltung-Vorhersage einiges: Schon den Fortschritt bei dem vorvorletzten CASP11 und dem vorletzten CASP12 bezeichnet Mohammed AlQuraishi von der Harvard Medical School, einer der CASP13-Teilnehmer im Dezember 2018, als substantiell. Und das dank der Anwendung der koevolutionären Algorithmen, zu deren Klasse auch genetische Algorithmen gehören – nach Jahren der Stagnation.
Die Grundlage der koevolutionären Methoden bilden phylogenetische Vergleiche von Proteinsequenzen aus verschiedenen Organismen – Multi-Sequence-Alignments (MSA). Dabei nimmt man an: Wenn Mutationen in einer Proteinsequenz stattfinden, müssen sie mit anderen Mutationen kompensiert werden, damit die entsprechende funktionelle Proteinstruktur erhalten bleibt. Sonst würde der gegebene Organismus die Funktionalität dieser Struktur verlieren und eventuell aussterben.
Eine Aminosäure A bildet zum Beispiel ein Strukturelement mit einer Aminosäure B, weil beide Aminosäuren sich anziehen. Wegen einer evolutionären Mutation wird die Aminosäure A dieses Paars durch die Aminosäure C ersetzt. Sollte die Aminosäure C sich mit der Aminosäure B nicht anziehen, geht das Strukturelement kaputt. Die Funktionalität dieses Proteins bleibt nur dann erhalten, wenn auch die Aminosäure B zu einer Aminosäure D mutiert, die sich mit C anzieht.
Nachdem in den koevolutionären Methoden tief lernende neuronale Netzen implementiert worden waren, steigerte sich die Effizienz der Proteinfaltungsprogramme noch mehr. Bei dem letzten CASP13 im Dezember 2018 hat sich dieser Fortschritt dank AlphaFold sogar verdoppelt. Mit einem so großen Abstand des Siegers AlphaFold zu den anderen Programmen, dass sich die akademische Proteinfaltung-Gemeinde regelrecht überfahren fühlte. „What just happened?“, fragte Mohammed AlQuraishi in seinem Blog. Bevor wir aber überlegen, von was genau hier die akademische Wissenschaft so kalt erwischt wurde, sehen wir uns die Funktion von AlphaFold an.
AlphaFold und sein Königsweg
Bei AlphaFold kamen zwei neuronale Netze zum Einsatz, deren Namenungetüme ich mir jetzt einfach aus dem Englischen ins Deutsche übersetzen traue: Tiefe residuale konvolutionelle neuronale Netze (deep residual convolutional neural networks – DR-CNN). Konvolutionelle neuronale Netze (CNN – convolutional neural networks), von Yan LeCun entwickelt, werden erfolgreich in der Bilderkennung angewendet. Residuale neuronale Netze (Deep residual Networks – ResNets) wurden in der Microsoft-Forschung entwickelt. Sie sind ein Spezialfall der LSTM-Netze (LSTM-Netze ohne „gates“), die von Jürgen Schmidhuber erfunden wurden, die wiederum eine Weiterentwicklung von rekurrenten neuronalen Netzen (RNN – recurrent neural networks) darstellen.
RNN können mit Sequenzen rechnen, weil sie eine Art „Gedächtnis“ haben – dabei kann die Ausgabe der einzelnen Einheiten im Netz (Neuronen) wieder als ihre Eingabe dienen oder zu den benachbarten Neuronen derselben Schicht geleitet werden. Wegen ihres „Memory“-Effekts werden RNN bzw. LSTM-Netze beim Rechnen mit zeitlichen Datenfolgen oder bei der maschinellen Verarbeitung der natürlichen Sprache verwendet – Wörter und Sätze sind ja auch Sequenzen. Genauso wie Proteine! DR-CNNs kann man sich als eine Mischung aus konvolutionellen und residualen Modellen vorstellen.
Das erste neuronale Netz von AlphaFold lernte anhand von Daten aus den bekannten koevolutionären Methoden (MSA – siehe oben), die räumlichen Distanzen zwischen den Aminosäuren eines Proteins vorherzusagen, und die Winkel, die die Bindungen einer Aminosäure zu benachbarten Aminosäuren bilden. Mit diesen Werten wurde ein zweites neuronales Netz gespeist, das dann die Struktur der niedrigsten Energie des gegebenen Proteins ermitteln konnte. Konkreter wurde eine Distanzmatrix aus den Abständen zwischen den Aminosäuren im gefalteten Protein so optimiert, damit die zu berechnende Proteinstruktur den Zustand des Minimums ihrer freien Energie erreichte.
Als Ausgabe lieferte also das erste neuronale Netz von AlphaFold eine Matrix mit den wahrscheinlichsten räumlichen Abständen zwischen den einzelnen Aminosäurenresten der gefalteten Proteinkette. Das war übrigens der innovative Beitrag von DeepMind – die anderen neuronalen Netze in der Proteinfaltung-Gemeinde rechneten mit direkten Kontakten der Aminosäurereste, also nicht mit ihren räumlichen Entfernungen.
Das oben Beschriebene ist nur eine sehr vereinfachte Darstellung von AlphaFold und seiner Funktion. Wer sich darüber tiefer informieren will, sollte den Blog-Beitrag von DeepMind und DeepMinds Artikel zu AlphaFold lesen (Link am Ende des Blogbeitrags von DeepMind).
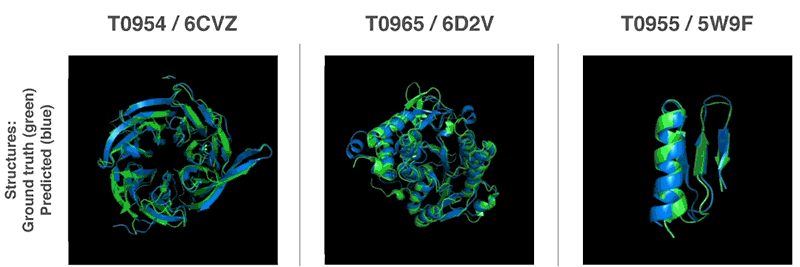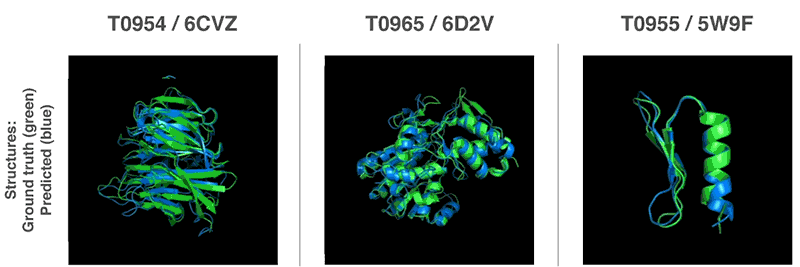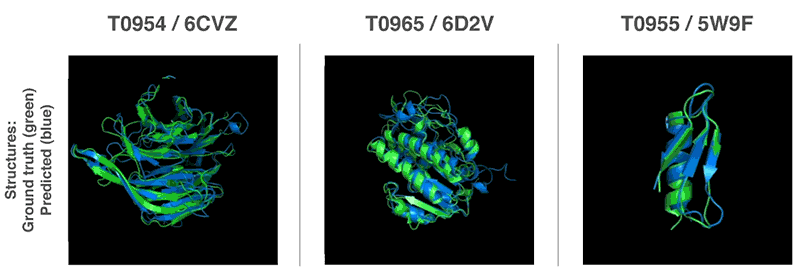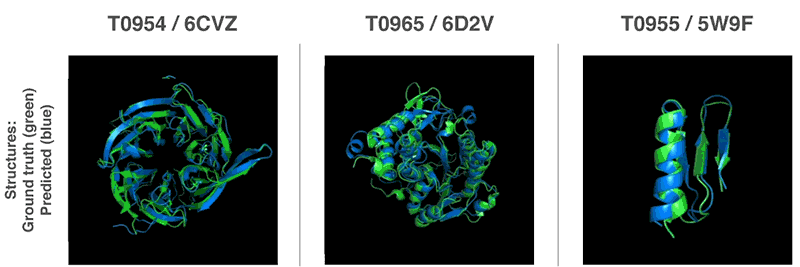
3-D-Strukturen von drei von AlphaFold gefalteten Proteine. Grün – die experimentell bestimmte Struktur. Blau – die von AlphaFold vorhergesagte Struktur. Quelle: DeepMind.
Was den Einsatz der tiefen neuronalen Netze in der Proteinfaltung angeht, haben Jinbo Qu von Toyota Technological Institute und der Universität in Chicago und sein Team Innovatives geleistet. Bei Quora erklärt Jinbo Qu den Zugang von AlphaFold zum Problem. Wer noch tiefer in die Materie „Deep Learning und Proteinfaltung“ tauchen will, sollte sich die zwei dort verlinkten Artikel vornehmen.
Der AlphaFold-Schock
Wie oben geschrieben wurden die Entwickler der anderen Proteinfaltungsprogramme bei CASP13 über den mit Abstand großen Erfolg von AlphaFold geschockt. Das drückt auch Mohammed AlQuaraishis Blog-Titel aus: „What just happened?“ AlQuaraishi schreibt sogar vom Gefühl der „existentiellen Angst“. Diese packte die Forscher bei CASP13, als sie sahen, wie AlphaFold ihren Programmen davonlief:
„In einer Art köstliche Ironie müssen wir, Menschen, die ihre Karriere darauf ausgerichtet haben, Kristallographen überflüssig zu machen, uns jetzt sorgen, ob wir selbst nicht überflüssig geworden sind“, schrieb Mohammed AlQuaraishi.
Stellt dieses Ereignis auch eine Anklage der akademischen Wissenschaft dar?, fragt sich der Autor und zitiert Marc Kirschner, der die akademische Wissenschaft als eine Jäger-Sammler-Gesellschaft bezeichnete. Hunderte von Forschern hätten seit Jahren über die Proteinfaltung geforscht. Die etwa 10 Entwickler von DeepMind hätten jetzt die kleine Effizienz der akademischen Forschung entlarvt. Hier sei es nicht darum gegangen, wie man Go spiele, sondern um ein zentrales Thema der Biochemie. Wie könne ein System funktionieren, in dem Jäger und Sammler ihr Jagd- und Sammelgebiet um jeden Preis verteidigen müssen? Wissenschaft sei ein gemeinsames Unternehmen. Wir alle würden davon profitieren, wenn wir kooperieren und unser Wissen teilen würden, statt uns in einem starken Konkurrenzkampf ständig behaupten zu müssen. Etwas Konkurrenz sei sicher notwendig, schreibt der Autor, doch solle sie nicht die Stimmung in den Akademien vergiften, wie es heute der Fall sei.
Auch die Pharmaindustrie und ihre kleinmütige Forschung knüpft sich Mohammed AlQuaraishi vor: Wieso werden Pharmafirmen jetzt in ihrem ureigenen Gebiet von Tech-Firmen geschlagen?
Auch mir ist während meiner Forschung in den 90ern die akademische Wissenschaft wie die Jagd nach Drittmitteln und Anerkennung vorgekommen: Der Jäger musste zeigen, dass seine „Beute“ (seine Forschung) die größte und beste und saftigste von allen sei. Wenn ich zwei Professoren erlebte, die sich bei einem wissenschaftlichen Seminar wegen der Bedeutung ihrer Arbeit wie kleine Kinder fetzten, staunte ich und dachte mit Wehmut an die großen Entdecker: Einstein, Bohr, Heisenberg … Oder waren diese Größen auch so wie diese zwei kleinlichen Streithähne? Mit dem Leitsatz: Das was ich mache, ist Gold, was der andere macht, taugt nichts.
Ich hatte Glück mit meinen Kollegen und dem Leiter meines Lehrstuhls, doch als er in die Rente ging und unser Lehrstuhl aufgelöst wurde, suchte ich nicht mehr nach einem neuen Job als Forscher, trotz eines Suma-cum-laude-Doktortitels, jahrelanger Forschung und hübscher Veröffentlichungen, und wurde Bühnenliterat und freier Schriftsteller. In der Poetry-Slam-Szene fühlte ich mich besser aufgehoben – dort herrscht zwar genauso Konkurrenz, jedoch mit Sportgeist. 😊
Das Problem ist hier auch unser veraltetes Schulsystem des Paukens und Leistens. Was bringt uns die Leistung, wenn Maschinen alles Automatisierbare besser leisten können als wir? Warum fördern wir in unseren Kindern nicht ihre Innovationslust und Kreativität? Mit Panik denke ich immer noch an die Hunderte „Aufgabenblätter“ meiner Söhne schon in der Grundschule. Jeden Tag brachten sie diese Blätter nach Hause, um sie auswendig zu lernen. In der 4. Klasse sagte mir die Klassenlehrerin meines Sohnes wörtlich: „Er muss Leistung bringen! Ich kann mich nicht auf seine Eigenarten einlassen.“ In der Wissenschaft sollte es aber um Freude am Wissen und Entdecken gehen, auch gemeinsam mit den anderen, nicht gegen sie, nicht um Leistungsdruck und Geltungssucht. Wissenschaftler mit “Eigenarten” und einem originellen Zugang zum Thema machen die größten Entdeckungen.
Wohl schreckt vor allem dieses starke Konkurrenzprinzip und der ewige Kampf um Forschungsgelder viele Frauen vor naturwissenschaftlichen Karrieren ab. Zum Glück ändert sich jetzt Einiges in der Welt der Naturwissenschaften. Immer mehr kluge Beiträge über Natur- und Computerwissenschaften im Quanta magazine oder in den Medium-Blogs schreiben junge Frauen.
Leider sucht man im deutschsprachigen Raum vergeblich nach einer Entsprechung der englischsprachigen Blogplattform Medium. Dort wird mit viel Enthusiasmus über künstliche neuronale Netze gebloggt und diskutiert. Von jungen Leuten! Warum gibt es hier keine wahrnehmbare Begeisterung für das Neue, das gerade unser Leben ändert? Einige deutschsprachige Medien berichteten über AlphaFold. Den tatsächlichen Knall dieser Wissenschaftsbombe haben jedoch nur wenige vernommen. Christian Stöcker im Spiegel gehört zu den wenigen. Schon im Titel seines Artikels bringt er unsere Trägheit in Sachen künstliche neuronale Netze auf den Punkt: “Deutschlands Zukunft – Bier allein wird uns nicht retten.“
An der Entwicklung von AlphaFold waren Molekularbiologen, Physiker und Maschinenlernen-Experten beteiligt. Spätestens jetzt sollte jede wissenschaftliche Fakultät einen Experten für künstliche neuronale Netze und fürs Maschinenlernen anheuern. Kooperation ist das Gebot der Stunde! Damit die Wissenschaft der Zukunft beginnen kann. Damit es uns allen und unserem Planeten besser geht.
willkommen auf meinem SciLogs-Blog "Gehirn & KI".
Ich möchte hier über alle möglichen Aspekte der Künstliche-Intelligenz-Forschung schreiben. Über jeden Kommentar und jede Diskussion dazu freue ich mich sehr, denn wie meine Mutter oft sagte:
"Solange die Sprache lebt, ist der Mensch nicht tot."
Neues über künstliche Intelligenz, künstliche neuronale Netze und maschinelles Lernen poste ich häufig auf meiner Facebook-Seite: Maschinenlernen
Hier etwas zu meiner Laufbahn: ich studierte Chemie an der TU München und promovierte anschließend am Lehrstuhl für Theoretische Chemie der TU über die Entstehung des genetischen Codes und die Doppelstrang-Kodierung in den Nukleinsäuren.
Nach der Promotion forschte ich dort einige Jahre lang weiter über den genetischen Code und die komplementäre Kodierung auf beiden Strängen der Nukleinsäuren:
Neutral adaptation of the genetic code to double-strand coding.
Stichworte zu meinen wissenschaftlichen Arbeiten: Molekulare Evolution, theoretische Molekularbiologie, Bioinformatik, Informationstheorie, genetische Codierung.
Zur Zeit bin ich Fachdozent für Künstliche Intelligenz an der SRH Fernhochshule und der Spiegelakademie, KI-Keynote-Speaker, Schriftsteller, Bühnenliterat und Wissenschaftskommunikator. Auf YouTube kümmere ich mich um die Videoreihe unserer SRH Fernhochschule "K.I. Krimis" über ungelöste Probleme und Rätsel der Künstlichen Intelligenz.
U. a. bin ich zweifacher Vizemeister der Deutschsprachigen Poetry Slam Meisterschaften.
Mein Buch „Doktorspiele“ wurde von der 20th Century FOX verfilmt und lief 2014 erfolgreich in den deutschen Kinos. Die Neuausgabe des Buches erschien bei Digital Publishers.
Mein Sachbuch über Künstliche Intelligenz "Ist das intelligent oder kann das weg?" erschien im Oktober 2020.
Im Tessloff-Verlag erscheinen meine von Marek Blaha wunderschön illustrierten Kinderkrimis "Datendetektive" mit viel Bezug zu KI, Robotern und digitalen Welten.
Viel Spaß mit meinem Blog und all den Diskussionen hier :-).
Jaromir
Schöner Text – und “Brutforce” ist sicherlich eine Nachwirkung des Anstoßens zum Jahreswechsel, oder? ;•)
Alphafold => Livefold => Evolution++
Ja, das Geheimnis des Lebens ist das Geheimnis eines symphonischen Zusammenwirkens subtiler molekularer und intramolekularer Kräfte, die etwas Hochorganisiertes aus dem Feuer des Chaos und der fast unbeherrschbaren Komplexität entstehen lassen. Gefaltete Proteine sind diese hochorganisierten Bausteine, die das Unmögliche realisieren, das Unmögliche, Unfassbare, welches darin besteht, Ketten aus nur 20 verschiedener Kleinmoleküle (Aminosären) zu einer ganzen, letztlich unbeschränkten Kollektion von höchst unterschiedlichen Materialien und hochspezifischer Katalysatoren zu formen. Das biologische Leben arbeitet also mit generischen Methoden und schafft aus einfachen Bausteinen über hochdelikate Wechselwirkungen zwischen diesen Bausteinen (den Benachbarten und Gruppen von weniger benachbarten) immer wieder etwas ganz Neues.
Und ja, solche generischen Prozesse, welche aus starken Wechselwirkungen zwischen direkten Nachbarn und schwächeren zwischen Entfernteren etwas Neues schaffen, die gibt es auch in der biologischen und kulturellen Evolution.
Was aber macht AlphaFold? Alphafold ist ein Orakel, welches erahnt oder gar weiss welches Endprodukt aus diesen komplexen Wechselwirkungen resultiert. Damit wir Alphafold irgendwann auch zu einem Evolutionsprediktor werden – inklusive der kulturellen Evolution und politischer Entwicklungen und eine generische Version oder eine auf Politprozesse spezialisierte Version von Alphafold wird besser voraussagen können als Menschen, wann die nächste Rezession oder der nächste Krieg droht.
Das Wahrscheinlichste in einer scheinbar undurchsichtigen Situation zu erkennen, das war bisher den Wenigen vorbehalten, die viel wussten und ein gutes Vorstellungsvermögen hatten.
Ab jetzt könnten zukünftige Versionen von Alphafold besser abschneiden. Das Orakel von Delphi wird also durch das Orakel fortgeschrittener Deep Learning Systeme abgelöst.
Martin Holzherr: “Alphafold ist ein Orakel …”
Jaromir: Diese Metapher finde ich ganz schön poetisch und, ja, passend, auch wenn sie viele dazu verführt, starke künstliche Intelligenz (die es nicht gibt und vielleicht nie geben wird) mit künstlichen neuronalen Netzen (wie AlphaFold) zu verwechseln, die wunderbare Optimierungsverfahren sind. 🙂
MH
das biologische Leben einer Blaualge unterscheidet sich doch gewaltig von der Spezies Mensch. Der Mensch ist schöpferisch tätig und kann etwas erschaffen, was es vorher auf der Erde noch nicht gab.
Alphafold ist ein Computerprogramm, ein menschliches Produkt, das hat keine schöpferischen Kräfte.
Alles nur Werberummel !
bote 19: “Alphafold ist ein Computerprogramm, ein menschliches Produkt, das hat keine schöpferischen Kräfte.
Alles nur Werberummel.”
Jaromir: Hier behauptet wohl niemand, dass AlphaFold oder ein anderes künstliches neuronales Netz schöpferische Kräfte besitzt. Ich habe in diesen Blogtexten ja öfter geschrieben, dass künstliche neuronale Netze Optimierungsverfahren sind, die in sehr großen Datensätzen wunderbar Muster erkennen und Sachen unterscheiden können. Äpfel von Birnen zum Beispiel. Auch ganz ähnliche Äpfel und Birnen, die wir Menschen ständig vergleichen, weil wir sie nun mal nicht unterscheiden können.
Zuerst wusste ich nicht, was Sie mit dem Werberummel meinen. Dank Ihren späteren Kommentaren weiß ich das. Dass künstliche neuronale Netze aber kein “Werberummel” sind, erfährt man sofort, wenn man bei Google “künstliche neuronale Netze” oder “artificial neural networks” oder “deep learning neural networks” eintippt und die Werbung ausschaltet – 🙂 – das mit der Werbung war nur ein Witz – bitte um Verzeihung.
AlphaFold sagt Proteinfaltungen voraus und die CERN-Physiker wollen nun neuronale Netzwerke einsetzen um im LHC neue Partikel zu entdecken. Deep Learning wurde gar bereits eingesetzt um aus der Stringtheorie diejenigen Stringwelten zu extrahieren, zu identifizieren, die mit unserer realen Welt kompatibel sind, denn die Stringtheorie erlaubt fast unendlich viele Welten von denen aber nur wenige Ähnlichkeit mit unserer eigenen Welt haben.
Die Elon Musks dieser Welt, die eine Übernahme des Kommandos über diese Welt durch AI erwarten, werden also enttäuscht. Statt dessen öffnet AI, öffnen neuronale Netze den Blick auf bisher Verborgenes, auf Dinge, die durch komplexe Wechselwirkungen gekennzeichnet sind. Das sind Dinge in denen selbst der Mensch und seine Programme bisher schlecht abschnitten. Deep-Learning Systemen fehlt bis jetzt noch das kausale, konzeptionelle Denken des Menschen, doch auch so leisten sie übermenschliches.
Lieber Herr Holzherr, ich glaube, wir haben die gleiche Schule besucht. 🙂
@bote 19: AlphaFold ist ein Werkzeug um komplexeste Beziehungen aufzuschlüsseln und Voraussagen zu machen, die keinem Menschen und keinem Tool bisher gelangen. Allein als Tool sind neuronale Netze und ist Deep Learning also bereits sehr wertvoll. Zudem gibt es unendlich viele weitere Anwendungsmöglichkeiten in Bereichen wo komplexe Wechselwirkungen eine Rolle spielen – und das ist die gesamte natürliche und auch die vom Menschen geschaffene Welt. Der Mensch versteht heute das Atom besser als die Gesellschaft in der er lebt und die er selbst geschaffen hat. Analytische Werkzeuge à la AlphaFold können mithelfen das zu ändern und Zusammenhänge aufzudecken, die uns bisher verschlossen blieben.
Es stimmt aber, dass sie, bote 19, nur einer von vielen sind, die in den neuen Errungenschaften der künstlichen Intelligenz vor allem einen potenziellen Konkurrenten des Menschen sehen und Leute wie Elon Musk, die vor einer Machtübernahme durch Systeme künstlicher Intelligenz warnen, haben mitgeholfen dieses Bild zu schaffen. Davon sind wir aber noch weit entfernt, denn eine menschenähnliche Intelligenz ist nicht ohne kausales (auch kontrafaktisches Denken) und konzeptionelles Denken möglich. Die Fähigkeit kontrafaktisch zu denken ist sogar so charakteristisch für den Menschen, dass man ruhig sagen kann, dass ein System, das dazu nicht in der Lage ist, keine echte Gefahr für den Menschen darstellt. Kontrafaktisch denken bedeutet konkret, dass man das was ist und was sich entwickelt hat mit dem vergleichen kann, was wäre, wenn man sich zu einem früheren Zeitpunkt anders entschieden hätte. Dazu gehören Aussagen wie: „hättest du mir früher zugespielt, hätten wir das Spiel gewonnen“. KI kann das heute noch nicht oder nur sehr eingeschränkt, aber es lässt sich nicht auschliessen, dass es das später einmal kann.
@Jaromir Konecny (Zitat): Die etwa 10 Entwickler von DeepMind hätten jetzt die kleine Effizienz der akademischen Forschung entlarvt.
In Zukunft könnten einige tausend Deep Learning/KI – Entwickler weltweit Millionen von heutigen Programmieren und ebenso viele Leute aus anderen Berufen ersetzen. Immer weniger Höchstqualifizierte ersetzen also immer mehr weniger Qualifizierte. Zuerst wurden die Niedrigqualifizierten ersetzt, jetzt sind die gut Qualifizierten dran, denn es gibt ein pasr noch höher Qualifizierte, die ihre Arbeit überflüssig machen.
Wo ist der Ausweg. Hier liest man dazu: „Warum fördern wir in unseren Kindern nicht ihre Innovationslust und Kreativität?“ Doch damit schafft man noch keine Deep Learning Forscher und gibt den Kindern keine erhöhte Chancen auf eine Stelle oder einen interessanten Beruf – es sei denn die Arbeitswelt wandle sich vollständig und Menschen seien in Zukunft vor allem in kreativen Bereichen tätig. Davon sind wir aber noch weit entfernt. Sogar die neuen Hightech-Firmen, die alles aufmischen schaffen nur wenige hochqualifizierte Stellen und viel mehr niedrigqualifizierte wie etwa Lageristen und Einpacker bei Amazon
Martin Holzherr: “In Zukunft könnten einige tausend Deep Learning/KI – Entwickler weltweit Millionen von heutigen Programmieren und ebenso viele Leute aus anderen Berufen ersetzen. Immer weniger Höchstqualifizierte ersetzen also immer mehr weniger Qualifizierte. Zuerst wurden die Niedrigqualifizierten ersetzt, jetzt sind die gut Qualifizierten dran, denn es gibt ein pasr noch höher Qualifizierte, die ihre Arbeit überflüssig machen.”
Jaromir: Im Grunde gebe ich Ihnen recht. Nur in diesem Spezialfall wurden Hochqualifizierte Experten in der Proteinfaltung durch weniger qualifizierte in diesem Gebiet ersetzt. DeepMind ist eine Tech-Firma, keine Akademie, die seit 50 Jahren über die Proteinfaltung forscht. Das ist eben das Paradoxe an den Sachen, die gerade passieren. Viele Institute aber auch Firmen haben sich nun mal zu lange auf den Lorbeeren ausgeruht. Das was vor 20 Jahren Kodak passierte, als Kodak pleite ging, weil Kodak die Revolution in der Digitalfotografie verpasst hatte, passiert jetzt noch massiver vielen wissenschaftlichen Instituten und Firmen.
Speziell Deutschland ist hier massiv gefährdet in seinem Dornröschen-Schlaf, viele seine Automobilfirmen zum Beispiel, aber auch Pharmafirmen und die chemische Industrie – alle Industrie eigentlich. Die Politik reagiert jetzt zwar, doch irgendwie behäbig. Immer wieder sehen wir, dass man sich hier mit künstlichen neuronalen Netzen nicht auseinandersetzen will, obwohl sie gerade dabei sind, die Welt zu ändern.
Auch ich kann sagen: Wenn man in Sachen künstliche neuronale Netze (KNN) Aufklärung betreibt, bekommt man vor allem Widerspruch. Man sagt: “Ein KNN kann an Tumorbildern Krebsarten bestimmen und sogar, welche DNA-Nukleotidfolgen zu diesem Krebs führen.”
Und der Mitdiskuttant sagt: “Diese Netze können bei weitem nicht denken wie der Mensch.”
Das kommt mir manchmal so vor, als ob ich sagen würde: “Ich habe das Rad erfunden.” Und man sagt mir: “Wozu ein Rad? Allein laufen wie der Mensch kann es sowieso nicht.”
Zitat Martin Holzherr: “Wo ist der Ausweg. Hier liest man dazu: „Warum fördern wir in unseren Kindern nicht ihre Innovationslust und Kreativität?“ Doch damit schafft man noch keine Deep Learning Forscher und gibt den Kindern keine erhöhte Chancen auf eine Stelle oder einen interessanten Beruf – es sei denn die Arbeitswelt wandle sich vollständig und Menschen seien in Zukunft vor allem in kreativen Bereichen tätig. Davon sind wir aber noch weit entfernt“.
.
Von diesem Zustand waren wir aber in der Geschichte überall in der Welt öfter mal nicht weit entfernt, sogar in abscheulicher Weise voll drin: Das war der Zustand der Sklaverei in einer Gesellschaft. Eine Mehrheit von Menschen wurde versklavt, um die schweren und unqualifizierten Arbeiten für eine Minderheit von Menschen zu erledigen, die sich dann in kreativen und kulturellen Bereichen betätigen konnten. Man braucht aber keine ethischen Bedenken zu haben, Maschinen zu versklaven. 🙂 So wie Sie, Herr Holzherr, und auch Herr Konecny, die Revolution von Deep Learning erklären, bin ich davon total begeistert und habe keine Angst um die Zukunft. Es wird fantastisch sein, und ich freue mich darüber, auch wenn ich diese Zukunft altersbedingt nicht erleben wird, die Zuversicht reicht mir. 🙂
Ich kann mich errinnern, das mir vor vielen Jahren eine wissenschaftliche Webseite zum Thema Proteinfaltung begegnet ist, wo es darum ging, dass Menschen (jeder, der wollte) onliner Proteine falten konnte, wie es ihm beliebt (oder nach irgendeiner Vorgabe eben, die mir heute nicht mehr in Erinnerung ist).
Hat das neue Projekt von Google irgendwas mit diesen damals erstellten Programm online und daraus angefallenen Daten zu tun?
Wurden Daten von dieser Seite für dieses Projekt verwendet?
Etwa die Auswertung der Intuition der mitmachenden Menschen, die dazu verwendet wurden, intuitive “Wahrscheinlichkeiten” auszuwerten und vorherzusagen, was technisch “Berechnen” meint?
Nach dem Vorbild der Citizen Science gibt es ja viele Programme online. Etwa Wetterdaten, die vor hundert Jahren analog aufgezeichnet wurden, vom Faximile ins Digitale zu übertragen. Einfach die Langeweile (und ein wenig Interresse) der Menschen produktiv ausnutzen.
Und dabei hinter die Mechanismen der Intuition kommen. Zumindest der statistischen Wahrheiten, die zu erstaunlich verlässlichen Vorhersagen führen können, wenn man die Daten intelligent auswertet und in Beziehung setzt.
.
MH
noch nirgends habe ich ein Beispiel eines neuronalen Netzwerkes gefunden. Noch nirgends habe ich einen Bauplan (technisch) für ein neuronales Netzwerk gefunden.
Die Fähigkeiten von neuronalen Netzwerken werden gepriesen. Erst wenn ich ein praktisches Beispiel gezeigt bekomme, werde ich meine Meinung ändern.
Zitat Martin Holzherr: “Das Wahrscheinlichste in einer scheinbar undurchsichtigen Situation zu erkennen, das war bisher den Wenigen vorbehalten, die viel wussten und ein gutes Vorstellungsvermögen hatten. Ab jetzt könnten zukünftige Versionen von Alphafold besser abschneiden. Das Orakel von Delphi wird also durch das Orakel fortgeschrittener Deep Learning Systeme abgelöst.”
.
Die Analogie mit einem menschlichen Orakel finde ich nicht zutreffend, denn kein Mensch ist in der Lage, kein einziger Mensch auf der Welt, das Wahrscheinlichste in einer undurchsichtigen Situation zu erkennen. Wie Sie es auch geschrieben haben, musste man dafür in der Lage sein, “komplexeste Beziehungen aufzuschlüsseln wo komplexe Wechselwirkungen eine Rolle spielen – und das ist die gesamte natürliche und auch die von Menschen geschaffene Welt“. Genau, das ist die gesamte Welt!
Ein menschliches Orakel entschlüsselt keine komplexsten Beziehungen, es ist dazu nicht in der Lage. Ein Mensch kann meistens eine Kausalität für ein Ereignis sicher erkennen, höchstens zwei (oft jedoch gar keine…). Ab 3 Kausalitäten muss er schon passen. Bei den unendlich vielen Ketten von Kausalitäten, woraus jedes einfachste Ereignis besteht, ist es absolut hoffnungslos, die Kombination von so vielen Wechselwirkungen kann er nicht verarbeiten, auch wenn er die Informationen dazu lückenlos zur Verfügung hätte. Ein Orakel entschlüsselt nichts, es geht nach dem „Trial & Error“-Prinzip bei einer 50/50 Wahrscheinlichkeitssituation vor: Entweder gewinn diese Fußballmannschaft das Spiel, oder die andere, entweder gibt es Krieg, oder nicht. Bei einer viel niedrigeren Wahrscheinlichkeitssituation ist die Prognose so gut wie unmöglich: Entweder fällt ein Ziegelstein vom Dach auf einen Passant, oder nicht.
Sogar die Zukuntsforscher, deren Job es ist Entwicklungen bei komplexen Systemen vorauszusagen, sind nicht in der Lage, zuverlässige Analysen zu liefern – das würden wir ja wissen. 😉
@Andromed (Zitat): “Ich kann mich errinnern, das mir vor vielen Jahren eine wissenschaftliche Webseite zum Thema Proteinfaltung begegnet ist, wo es darum ging, dass Menschen (jeder, der wollte) onliner Proteine falten konnte, wie es ihm beliebt “. Ja, daran kann ich mich auch erinnern.
Es gibt aber jedenfalls Folding@home, womit jeder seinen eigenen PC für Faltungsberechnungen der Universität Stanford zur Verfügung stellen kann. In der Wikipedia liest man dazu: Insgesamt wurden bis jetzt 155 Publikationen als direktes Ergebnis von Folding@home veröffentlicht.[8] Einige Daten stehen jedem kostenlos zur freien Verfügung
Das Computer-Game Foldit kommt am ehesten an das von ihnen, Andromed, beschriebene menschliche Erraten des gefalteten Zustands heran (Zitat): Ziel des Spieles ist es, ein möglichst gut „gefaltetes“ Protein zu erhalten, d. h. ein Modell des Proteins im Zustand des Energieminimums. Das ist die Form, in der es in der Natur vorkommt. Dazu sind allerdings keinerlei Vorkenntnisse nötig, die Bewertung erledigt das Programm. ..Foldit ist der Versuch, die natürlichen menschlichen 3-D-Mustererkennungsfähigkeiten auf dieses Problem anzusetzen. Gegenwärtige Puzzles basieren auf gut verstandenen Proteinen.
Und tatsächlich scheinen einige FoldIt-Spieler gut drauf gewesen zu sein, liest man doch zu den Resultaten: Im Januar 2012 wurde bekannt gegeben, dass Foldit-Spielern die Neugestaltung eines Proteins mit einer 18-fach höheren Aktivität als dem Original gelang. Das Protein ist ein computergeschaffenes Enzym, das die Diels-Alder-Reaktion katalysiert. Die Foldit-Spieler überarbeiteten das Enzym durch Zugabe von 13 Aminosäuren und erhöhten somit seine Aktivität um das 18-fache.
Die Realität ist die beste Simulation der Realität
Eine Proteinfaltung zu berechnen, zu simulieren, bringt jedes noch so mächtige Computersystem an die Grenzen seiner Leistungsfähigkeit. Aber nur schon die Berechnung der Masse des Protons aus den Eigenschaften der Bestandteile des Protons, also Quarks und Gluonen, hat Supercomputer monatelang beschäftigt.
Folgerung 1: Wer unsere Realität als Simulation interpretiert, die auf einem Computer einer fremden Intelligenz läuft, der muss annehmen, die fremde Intelligenz verfüge über Computer praktisch unbeschränkter Leistungsfähigkeit, ja solch gewaltiger Leistungsfähigkeit, dass diese fremde Intelligenz in einer Realität ganz anderen Kalibers leben muss, einer Realität wo völlig andere physikalischen Gesetze gelten.
Folgerung 2: Keine noch so detaillierte virtuelle Welt kommt bis auf Weiteres auch nur ansatzweise an unsere reale Welt heran. Ratschlag: Besser mal aus dem (realen) Fenster schauen als immer nur ins Bildschirm-Fenster blicken. In der realen Welt passiert nämlich mehr und es ist erst noch “echter”.
@bote 19(Zitat: noch nirgends habe ich ein Beispiel eines neuronalen Netzwerkes gefunden. ): Ausprobieren kann man “Spielzeugversionen” von neuronalen Netzen online, nämlich auf ConvNetJS: Deep Learning in your browser
Einigermassen überschaubar ist die erste “Übung”: Classify MNIST digits with a Convolutional Neural Network Sobald man den Link angeklickt hat, startet das Training des neuronalen Netzes und wenn man ganz nach unten scrollt, kann man in den Example predictions on Test set erkennen welche Ziffern das System den handgeschriebenen Zeichen zuordnet während man ganz oben Statistiken zum Lernerfolg erhält. Man muss das System ziemlich lange laufen lassen bis es genügen trainiert ist und dann die Ziffern mit mehr als 90%-iger Wahrscheinlichkeit erkennt.
Das ist es:
https://de.wikipedia.org/wiki/Folding@home
https://foldingathome.org/
MH
danke für den Link. Wie so ein Programm abläuft kann ich mir schon vorstellen.
Aber warum heißt es neuronales Netzwerk. Wir da ein computer mit einem biologischen Hirn verknüpft ?
@Bote 19 (Zitat: „Aber warum heißt es neuronales Netzwerk. „)
„Neuronales Netzwerk“ heisst es, weil es aus Knoten besteht, wobei jeder Knoten mehrere Eingangsleitungen hat und er nach dem Verrechnen der Sinale in den Eingangsleitungen ein Ausgangssignal erzeugt, sobald ein dem Knoten (Neuron) zugeordneter Schwellwert überschritten wird. Das Ausgangssignal wird dabei typischerweise einem Knoten, einem „Neuron“ in der nächsten Schicht zugeschickt. Je weiter die Schichten von der Inputschicht (z.B. Bild) entfernt sind umso komplexere Muster erkennen sie. Die letzte Schicht, die Outputschicht, gibt dann nur noch wenige Kategorien wieder, beispielsweise ein Signal, das einer der Ziffern 0 bis 9 entspricht.
Ganz entfernt arbeitet auch unser Nervensystem so – mindestens in gewissen einfachen Fällen.
Im Gegensatz von zum Beispiel der Proteinfaltung oder der Wettervorhersage werden die wirtschaftlichen und die politischen Entwicklungen von einem bewussten Konkurrenzkampf destabilisiert.
Jedes Programm von zum Beispiel der Vorhersage von Börsenkursen wird gerade durch sein Vorhandensein nutzlos.
Das ist so ähnlich, wie wenn zwei AlphaGoZeros gegen einander spielen würden.
Die Proteinfaltung und das Wetter sind keine bewussten Gegner, und sie halten sich an starre Regeln.
Natürlich kann man immer noch hoffen, dass der wirtschaftliche oder politische Gegner ein schwächeres Computersystem verwendet als man selbst.
@ Karl Bednarik: „Natürlich kann man immer noch hoffen, dass der wirtschaftliche oder politische Gegner ein schwächeres Computersystem verwendet als man selbst.“
.
So wie ich es verstanden habe, baut die KI kein menschliches Gehirn nach (sie kann es nicht und wird es auch nie können, davon bin ich überzeugt), sondern nur ein einziges, eingeschränktes Merkmal der menschlichen Intelligenz, und zwar das Merkmal des abstrakten logischen Schlussfolgern. Dabei sind also alle Emotionen Gefühle, Bestrebungen und individuelle psychische Gegebenheiten und Zustände außen vor. Die KI ist bei ihrer Entschlüsselung der Wechselwirkungen und der Kausalitäten wertfrei, genauso wie die Natur selbst wertfrei ist. Das ist eindrucksvoll mit der Faltung von Proteinen dokumentiert.
Die Gefahr eine durch politische oder wirtschaftliche Interesse gesteuerte Programmierung liegt einzig an die Informationen, womit der Programmierer sein Programm futtert. Die Gefahr der Fütterung mit selektiven und subjektiven Informationen oder gar mit Fake-Informationen besteht wohl auch bei der KI bei wirtschaftlichen oder politischen Vorhersagen, aber meiner Meinung nach auch bei einigen Naturwissenschaften wie zum Beispiel Klimaforschung. Oder?
Künstliche Neuronale Netze für andere und bessere Lösungen
In den News spricht man selten über konkrete Anwendungen neuronaler Netze und noch weniger wird exploriert, wem sie konkret helfen könnten. Statt dessen überwiegt der Kontext “Digitalisierung” und Künstliche Intelligenz als Jobfresser und Helfer von Google, Facebook, Microsoft, Apple und Tesla.
Umfragen bei Kleinen und Mittleren Unternehmen in Deutschland ergeben dann kaum verwunderlich, dass nur wenige sie einsetzen oder einzusetzen gedenken. Das ist schade, denn damit werden Chancen vergeben, Probleme ganz anders anzugehen als bisher. Anstatt zu Programmieren um eine bestimmte Aufgabe zu bewältigen könnte man nun in einigen wichtigen Anwendungsbereichen mit Training von neuronalen Netzwerken nicht nur auf das manuelle Programmieren verzichten sondern sogar noch wesentlich flexiblere Lösungen erreichen. Natürlich muss die Firma, die Anwendungen durch Training von neuronalen Netzen erstellt, sich diese Technologie aneignen und sich die nötigen Datensätze beschaffen. Doch gewinnen kann sie dadurch sehr viel, auch darum, weil sich mit der Erfahrung eine ganz neue Sichtweise auf Probleme und deren Lösung ergibt. Zudem gibt es Anwendungsbereiche, wo es bereits standardisierte Verfahren mit geringem Versagensrisiko gibt, etwa die Bildanalyse mittels Convolutional Neural Networks (CNNs)
Heutige CNNs können Bilder aus wichtigen Anwendungsbereichen oft sogar besser analysieren als selbst Fachleute – vorausgesetzt das Trainingsset ist gross genug. Ein Beispiel für die Überlegenheit con CNNs über Fachleute ist die Diagnose einer diabetischen Retinopathie allein aufrund eines Bildes der Netzhaut wie der Artikel Saving sight: Using AI to diagnose diabetic eye disease zeigt.
@Karl Bednarik: wirtschaftlicher und politischer Konkurrenzkampf und Künstliche Intelligenz
Ein gegenseitiges Hochrüsten gibt es auf vielen Bereichen – und nicht nur in der menschlichen Sphäre. Das Immunsystem aller höheren Tiere (selbst Bakerien haben einfache Formen) kann etwa als flexibles Abwehrsystem aufgefasst werden, welches sich immer wieder neuen Herausforderungen stellen muss und das sich bei Bedarf anpasst oder gar neu erfindet (?).
KI erweitert lediglich das Repertoire (z.B. über DeepFakes) der Mittel und Methoden um andere auszutricksen oder um zu besseren Informationen zu kommen als der Wettbewerber/Gegner.
KI hilft aber auch Täuschungen aufzudecken und Generative Adversarial Networks ( kompetitive neuronale Netzwerke) arbeiten sogar mit der Methode der gegenseitigen Konkurrenz und sie können damit Täuschungen immer weiter verbessern aber auch aufdecken.
Fazit: KI als Macht- und Täuschungsmittel ist nichts grundsätzich neues. Allerdings haben sie recht, dass in diesem Spiel, in diesem Kampf um die Vorherrschaft am Schluss KI-Systeme direkt gegen KI-Systeme antreten könnten – einfach weil der Mensch zu langsam ist um ihn noch sinnvoll dazwischenzuschalten.
Wie heute die besten Athleten um olympische Medaillen kämpfen könnten in Zukunft KI-Systeme im Dienste von Firmen, Ländern, Privaten oder gar im Dienste eines von der KI selbst gesetzten Zieles gegeinander antreten und Menschen würden dann nur noch die Rolle von Statisten und Zuschauern spielen.
AI besser verstehen bedeutet auch AI’s Schwächen, AI’s Unvermögen besser zu erkennen
Ein AI-System, das etwa gesprochene Sätze versteht oder mit dem man gar debattieren kann, wird von Menschen gern als intelligent, verständig usw. taxiert – obwohl das fast immer nicht stimmt und das System lediglich ein Verständnis vortäuscht oder das Verständnis auf einer ganz oberflächlichen Ebene besteht (es weiss z.B. welches Produkt ich kaufen will).
Der MIT-Review- Aritkel This AI program could beat you in an argument—but it doesn’t know what it’s saying erklärt, dass das IBM-System Projekt Debattierer, welches in Debatten zwischen Mensch und Maschine, Menschen oft argumentativ schlägt, trotzdem nicht versteht, was es sagt (Zitat, übersetzt von DeepL): Der Projektdebatteur versucht nicht, ein Argument aufzubauen, das auf dem Verständnis des jeweiligen Themas basiert. Stattdessen konstruiert es einfach eines, indem es Elemente früherer Argumente mit relevanten Informationspunkten aus Wikipedia kombiniert.
Ranit Aharonov, eine Forscherin hinter dem Projekt mit Sitz in Israel, erkennt an, dass es begrenzt ist. “Es ist noch ein langer Weg, um die Sprache zu beherrschen”, sagt sie. Aharonov ist jedoch der Ansicht, dass die Technologie eine Reihe von praktischen Anwendungen haben könnte. Es könnte jemandem helfen, eine kritische Entscheidung zu treffen, indem es beispielsweise eine Reihe von “Für”- und “Gegen”-Argumenten anbietet.
Trotzdem erklären menschliche Schiedsrichter oft das IBM-System zum Gewinner der Debatte. Klar: Wer sich die Argumente bei Wikipedia holt und diese Argumente geschickt verknüpft, der macht wohl an und für sich schon einen guten Eindruck – auch wenn er überhaupt nichts von der Sache versteht.
@ Karl Bednarik und Martin Holzherr:
Ich verstehe aus Ihren Ausführungen, dass wir zu Problemlösungen in der Gesellschaft, in der globalen Wirtschaft und in der Politik nicht besser aufgehoben werden würden mit KI als “zu Fuß” mit eigenem Gehirn. 😉
Zu wertfreien Erkenntnisgewinnen über die Welt, könnte es jedoch entscheidende Fortschritte geben, wie wir es am Beispiel der Proteinfaltung sehen. Herr Holzherr, Sie führen an, dass KI bessere Leistungen bringt als Fachleute bei der Bildanalyse. Ein Sache würde mich interessieren zu erfahren, und zwar, ob KI folgendes leisten könnte: Ist es denkbar, dass ein KI-Programm zuverlässig erkennen bzw. simulieren könnte, wie zum Beispiel Tiere die Welt sehen? Wie sieht eine Katze, ein Hund, ein Vogel, ein Krokodil oder eine Biene die Welt? Was sehen sie – und vor allem was sehen sie, was wir nicht sehen können? Das wäre doch total spannend es zu wissen, da wir mit den anderen Lebensformen mit der Sprache nicht kommunizieren können, oder?
@Jocelyne Lopez (Zitat: Ist es denkbar, dass ein KI-Programm zuverlässig erkennen bzw. simulieren könnte, wie zum Beispiel Tiere die Welt sehen? )
Eine Herangehensweise an dieses Problem beispielsweise beim Sehen der Biene mittels ihrer Facettenaugen könnte es sein, die Bilder, die die Facettenaugen erzeugen als Eingabe für ein neuronales Netz zu verwenden und das neuronale Netz müsste dann erkennen was in den Bildern dargestellt wird. Damit könnte man zum Beispiel herausfinden welche Details eine Biene gerade noch erkennen kann. Wie gut die Biene sieht hängt nämlich nicht nur von den optischen Eigenschaften ihrer Facettenaugen ab, sondern auch von der Verarbeitung und dem Zusammenrechnen der vielen Einzelfactettenbilder.
Heute kann man aber das Bienenauge und Bienennervernsystem (Hirn) auch direkt untersuchen (mit Elektroden, die die Nerzenzellaktivität ableiten). Darüber wird in Honey bees have sharper eyesight than we thought berichtet. Dort liest man (übersetzt von DeepL):
Dr. Rigosi sagt: “Wir haben festgestellt, dass Honigbienen im vorderen Teil des Auges, wo die Auflösung maximiert wird, deutlich Objekte sehen können, die nur 1,9° klein sind – das ist ungefähr die Breite Ihres Daumens, wenn Sie Ihren Arm vor Ihnen ausstrecken.
“Das ist 30% mehr Sehvermögen als bisher”, sagt se.
“Bezogen auf das kleinste Objekt, das eine Biene erkennen kann, aber nicht eindeutig, ergibt sich ein Wert von etwa 0,6° – das ist ein Drittel der Daumenbreite bei Armlänge. Das ist etwa ein Drittel dessen, was Bienen deutlich sehen können, und fünfmal kleiner als das, was bisher in Verhaltensexperimenten nachgewiesen wurde.
Kooperation statt Konkurrenz zwischen Wissenschaftlern?
In diesem Beitrag wird der Erfolg von AlphaFold über die bisherigen Ansätze zur Bestimmung der Proteinfaltung zum Anlass genommen, die heutige Arbeitsweise der Wissenschaft in Frage zu stellen (Zitat): Wie könne ein System funktionieren, in dem Jäger und Sammler ihr Jagd- und Sammelgebiet um jeden Preis verteidigen müssen? Wissenschaft sei ein gemeinsames Unternehmen. Wir alle würden davon profitieren, wenn wir kooperieren und unser Wissen teilen würden, statt uns in einem starken Konkurrenzkampf ständig behaupten zu müssen.
Doch trifft diese Kritik überhaupt zu? Mir scheint Wissenschaftler arbeiten allein dadurch schon kooperativ, dass sie ihre Arbeiten öffentlich machen und publizieren.
Keine Zusammenarbeit hätte das Debakel für die bisherigen Ansätze durch AlphaFold beheben können, denn Zusammenarbeit allein bringt noch nichts neues hervor und AlphaFold entstand eben gerade ausserhalb der bisherigen Zusammenarbeit durch einen ganz neuen Ansatz. Dieses Debakel für die fleissigen Wissenschaftsbienchen, die nach altem Modell arbeiteten hat es übrigens schon mehrmals gegeben – beispielsweise beim Human Genom Projekt, wo Craig Venter eine viel schnellere neue Sequenziermethode einführte und damit monatelange manuelle Arbeit durch das Laufenlassen eines Supercomputers ersetzte. Ja, das kann (fast) jedem, der sich bemüht passieren: Dass sein Arbeit obsolet wird, weil es mit neuer Technologie nun viel schneller geht.
In dem “kursiven” Absatz, den Sie zitieren, zitiere ich eigentlich selbst einen der CASP-Teilnehmer, Mohammed AlQuraishi von der Harvard Medical School, das Kursive sind nicht meine Worte, deswegen sind die Sätze ja im Konjunktiv. Ich habe dann etwas aus meiner Erfahrung aus den 90ern hinzugefügt: Darüber, wie man sich als Forscher selbst “verkaufen” und “preisen” muss, um an Drittmitteln zu kommen usw.
Publiziert wird aber erst dann, wenn alles stichfest ist, vor allem auch um das Primat in diesem Forschungsgebiet zu behaupten. Mohammed AlQuraishi bemängelt die Geheimniskrämerei und schwache Kooperation der akademischen Gruppen in der Zeit, wenn nach den Ergebnissen der Forschung “gejagt” wird.
Ich sehe aber durch das neuere Open-Acces-Prinzip auch große Fortschritte in der Öffnung der Wissenschaften für ein breites Publikum. Zum Beispiel arXiv als DIE Quelle von wissenschaftlichen Artikeln, die jedem schnell zugänglich sind, ist wunderbar. Früher brauchte jede wiss. Veröffentlichung durch die ganzen Prüfverfahren bei angesehen wiss. Magazinen eine Menge Zeit, bis sie veröffentlicht wurde. Danach mussten wir Wissenschaftler bei den veröffentlichenden Kollegen Preprints anfordern. Später einen Artikel für 50 Euro bei dem Magazin erwerben oder in Bibliotheken zu kopieren versuchen. Jetzt sind die ganzen Artikel oft noch vor der Veröffentlichung bei arXiv oder bioArxiv für jeden abrufbar.
Uups, nein, ich habe den AlphaFold-Knall nicht gehört—aber Gottseidank habe ich das Echo hier auf dem Blog vernommen. Vielen Dank dafür!
Eine Frage hätte ich zu folgender Angabe:
»AlphaFold konnte 25 von 43 Proteinstrukturen richtig voraussagen. «
Was genau ist oder umfasst eine (1) Proteinstruktur?
Denn in den gezeigten 3-D-Strukturen sind jeweils nur Teilbereiche eines Proteins grün oder blau eingefärbt.
🙂 Danke! Ich wollte die ganzen Kommentare der Reihe nach abarbeiten, eine Frage verdient aber eine sofortige Antwort:
Mit einer Proteinstruktur meine ich im Blog die gesamte dreidimensionale Struktur eines Proteins. Einzelne Stücke des Proteins bezeichne ich als Strukturelemente. Wenn ich die 3-D-Bilder richtig deute, deckt sich die von AlphaFold vorhergesagte Struktur (blau) weitgehend mit der wahren experimentell ermittelten Struktur des Proteins (grün), auch wenn sich kleine Stücke davon etwas unterscheiden. Wenn man die sich drehenden Strukturen sehr aufmerksam beobachtet, sieht man eigentlich, dass es zwei verschiedene Gesamtstrukturen sind (nicht nur Teilbereiche): eine grüne und eine blaue. Meiner Meinung nach ist das Gefühl von einzelnen blauen bzw. grünen Stücken nur eine optische Täuschung. Ich hoffe, ich irre mich nicht. Ich hatte zuerst ein ähnliches Problem damit gehabt wie Sie, habe dann aber akzeptieren können, dass es durchgehende Strukturen sind.
Ja, danke, Jaromir Konecny, jetzt sehe ich es auch (nachdem ich Ihrem Link zu DeepMind gefolgt bin): es sind jeweils zwei aufeinander- oder übereinanderliegende, komplette Proteinstrukturen.
Dann wurden also tatsächlich die Strukturen von 25 Proteinen aus einer Menge von 43 hinreichend genau errechnet. Das ist in der Tat phänomenal!
AlphaFold ist eine von vielen Anwendungen von Deep Learning für wissenschaftliche Anwendungen.
A look at deep learning for science gibt weitere Anwendungsbeispiele, darunter etwa
– Galaxieformmodellierung mit probabilistischen Auto-Encodern
– Extreme Wetterereignisse in Klimasimulationen finden
– Erkennen von Mustern in kosmologischen Massenkarten
– Dekodierung von Sprache aus menschlichen neuronalen Aufzeichnungen
– Klassifizierung neuer physikalischer Ereignisse am Large Hadron Collider
Wobei etwas die “Dekodierung von Sprache aus menschlichen neuronalen Aufzeichnungen” bald einmal sehr praktische Auswirkungen haben könnte, indem etwa allein aus “Hirnwellen” (Enzephalogramm) oder mittels Hirnimplantantat, welches Neuronenaktivitäten aufzeichnet, ein Transkript gedachter Sprache erstellt wird. In Zukunft könnte man damit eventuell die Tastatur ersetzen.
Fazit: Es gibt selbst in der Wissenschaft wichtige Anwendungsmöglichkeiten für Deep Learning. Selbst wenn Deep Learning allein noch keine wirkliche Intelligenz realisiert und vorerst nicht zu autonomen Systemen führt, bietet Deep Learning ganz neue Analysemöglichkeiten und öffnet für Wissenschaft und Technik Welten, die ihr bisher verschlossen blieben, weil die jetzt von Deep Learning “dekodierten” Daten so komplex und polymorph sind, dass bisher weder von Menschen noch von Programmen verarbeitet werden konnten
Deep Learning ermöglicht Software zu trainieren anstatt sie zu programmieren und Deep Learning eröffnet den Zugang zu komplexen, polymorphen und verrauschten Daten. Doch Deep Learning ist noch nicht bei den KMU’s, noch nicht bei Schulen und Studenten angekommen. Dabei könnte man sich vorstellen, dass auch KMU’s, Schüler, Studenten und Hobbyisten mit Deep-Learning Methoden Probleme bewältigen, Semesterarbeiten erstellen oder persönliche Projekte unterstützen. Es gibt mehrere Gründe warum dies noch nicht passiert. Darunter etwa
1) Neuronale Netzwerke müssen für jede Anwnendung individuell parametrisiert werden, was sehr viel Erfahrung und geschichtes Ausprobieren nötig machen kann
2) Es gibt wenig öffentlich zugängliche Deep Learning-Software, die vom naiven Benutzer auf einfache Art und Weise für eigene Zwechke anpepasst werden könnte
3) Die Daten, welche für das Training nötig wäre ist nicht vorhanden oder zu kleinvolumig
4) Die Hardware, welche für das Training nötig wäre ist zu teuer.
Immerhin ist Punkt 4) gelöst, wenn man die Google-Cloud Lösungen benutzt.
Zitat @ Konecny: „Auch mir ist während meiner Forschung in den 90ern die akademische Wissenschaft wie die Jagd nach Drittmitteln und Anerkennung vorgekommen: Der Jäger musste zeigen, dass seine „Beute“ (seine Forschung) die größte und beste und saftigste von allen sei. Wenn ich zwei Professoren erlebte, die sich bei einem wissenschaftlichen Seminar wegen der Bedeutung ihrer Arbeit wie kleine Kinder fetzten, staunte ich und dachte mit Wehmut an die großen Entdecker: Einstein, Bohr, Heisenberg … Oder waren diese Größen auch so wie diese zwei kleinlichen Streithähne? Mit dem Leitsatz: Das was ich mache, ist Gold, was der andere macht, taugt nichts.“
Was Sie da ansprechen ist ein grundsätzliches immer größer werdendes Problem nicht nur in der Wissenschaft.
Die Kommunisten ehemals hatten keinen realistischen Markt und mussten die Preisrelationen z.B. zwischen Russischen Gas und Polnischen Obst aushandeln. Genau aus den Gründen die Sie oben angeführt haben, entarteten die Verhandlungen, so dass die verrücktesten Argumente vorgebracht wurden die es jemals auf der Welt gab. Folge war, dass der Comecon zusammengekracht ist und mit ihm der Kommunismus russischer Prägung.
Zitat Konecny (Wenn ich zwei Professoren erlebte, die sich bei einem wissenschaftlichen Seminar wegen der Bedeutung ihrer Arbeit wie kleine Kinder fetzten, staunte ich und dachte mit Wehmut an die großen Entdecker: Einstein, Bohr, Heisenberg … )
Es gibt Fotos auf denen gleichzeit Einstein, Bohr, Schrödinger, Dirac, Pauli und Heisenberg abgebildet sind. Das war eine Zeit als vielleicht 0.1 Promille der Bevölkerung Physiker waren, es also in ganz Europa nur einige tausend Physiker gab, also wohl hundert Mal weniger als heute. Wissenschaftler sein ist heute nichts Exklusives mehr, die Gründertage sind vorbei und der Kampf um (begrenzte) Ressourcen ist schon lange angebrochen.
Martin Holzherr: “Das war eine Zeit als vielleicht 0.1 Promille der Bevölkerung Physiker waren, es also in ganz Europa nur einige tausend Physiker gab, also wohl hundert Mal weniger als heute. Wissenschaftler sein ist heute nichts Exklusives mehr, die Gründertage sind vorbei und der Kampf um (begrenzte) Ressourcen ist schon lange angebrochen.”
Jaromir: Vielleicht hat man damals viel mehr diverse Naturwissenschaften studiert, weil man an ihnen interessiert war. Jetzt schreiben sich viele Studenten vor allem in Fächern ein, die ihnen gute Jobs versprechen. 🙂
Gestern hat Christian Stöcker im Spiegel über Ähnliches geschrieben wie ich in diesem Beitrag und auch Mohammed AlQuaraishis Blog zum CASP-Wettbewerb zitiert.
@ Jaromir Konecny, @ Martin Holzherr, @ Elektroniker
So wie ich es verstanden habe, basiert die Leistung von KI auf dem Merkmal des abstrakten logischen Schlußfolgern.
Könnte eine Anwendung von KI daraus bestehen, die logische Konsistenz einer Aussage bzw. einer Theorie zu prüfen?
Ich weiß aus Erfahrung, dass schon ein „normaler“ Computer stur bockt, wenn man bei einer Datenverarbeitung eine Verknüpfung eingibt, die logisch nicht möglich ist: Er liefert kein Ergebnis, sondern nur die Meldung Fehler!.
Zum Beispiel, wenn man eingibt: a>b und b>a
Als konkrete Veranschaulichung: Peter ist 10 cm größer als Paul und Paul ist 7 cm größer als Peter.
Hier liefert ein normaler Computer kein Ergebnis für den Größenunterschied zwischen Peter und Paul, sondern eben nur die Meldung: Fehler!
Wie würde hier ein KI-Computer reagieren?
Es gibt nämlich nach diesem Muster eine mehr als 100-jährige Streitigkeit in der theoretischen Physik mit der Speziellen Relativitätstheorie, die mit dem berühmten Zwillingsparadoxon veranschaulicht werden kann. Der „Erfinder“ des Zwillingsparadoxons nach den Prämissen der Speziellen Relativitätstheorie, der renommierte französische Physiker Paul Langevin, hat 1911 sein Paradoxon (und somit die Spezielle Relativitätstheorie) mit dem Satz verworfen:
„Es ist logisch und tatsächlich ausgeschlossen, dass von zwei Uhren jede gegenüber der anderen nachgeht.“
Wie würde ein KI-Computer reagieren, wenn man in einer Theorie davon ausgeht, dass die Uhr A langsamer als die Uhr B läuft und die Uhr B langsamer als die Uhr A? Würde er quantitative Ergebnisse liefern oder nur die Meldung Fehler! ?
#09:35 Ein Computer gibt das aus, was man reingesteckt hat – er ist ein gemachtes Programm.
Wenn unerlaubte Eingaben eingegeben werden – dann sagt eine Programmzeile “error”.
In der Relativitätstheorie gehen bewegte Uhren A und B gleich schnell, sonst wäre das zugrunde liegende Relativitätsprinzip ja nicht beachtet – jedes Zwillings seine Uhr geht a priori richtig.
Der Computer würde dem Herrn Langevin antworten “error – bitte die Frage korrekt stellen”.
Bevor man eine Theorie der KI übergibt, muß man sie verstehen, sonst werden die Fragen falsch.
@ Herr Senf: “Der Computer würde dem Herrn Langevin antworten “error – bitte die Frage korrekt stellen”. Bevor man eine Theorie der KI übergibt, muß man sie verstehen, sonst werden die Fragen falsch.”
.
Der Erfinder des Zwillingsparadoxons Paul Langevin stellt gar keine Frage, sondern er hat lediglich mit dem Zwillingsparadoxon die physikalische Konstellation veranschaulicht, die mit dem Postulat bzw. das Relativitätsprinzip der Speziellen Relativitätstheorie beschrieben wird. Dieses Postulat wäre also nicht als Frage, sondern als Information in einem KI-Computer einzuspeisen:
Das Relativititätsprinzip der SRT besagt, dass man bei zwei zueinander bewegten Objekten wahlweise und gleichberechtigt definieren darf, dass ein der Objekte sich bewegt und ein der Objekte ruht, und vice versa.
Bei dem Zwillingsparadoxon darf man also zugrunde legen:
– dass der reisende Zwilling B sich bewegt, und dass sein auf der Erde zurückgebliebener Bruder ruht
oder aber genauso richtig
– dass der reisende Zwilling B ruht und dass sein auf der Erde zurückgebliebener Bruder A sich bewegt.
Daraus darf man folgendes schlußfolgern:
Läuft die Uhr des als definiert bewegten Zwillings B langsamer als die Uhr des als definiert ruhenden Zwillings A, bedeutet es gemäß obigem Relativitätsprinzip, dass die Uhr des als definiert bewegten Zwillings A langsamer läuft, als die Uhr des als definiert ruhenden Zwillings B.
Und das ist die Schlußfolgerung von Paul Langevin, der wie gesagt gar keine Frage gestellt hat:
„Es ist logisch und tatsächlich ausgeschlossen, dass von zwei Uhren jede gegenüber der anderen nachgeht.“
Meine Frage hier an die KI-Experte ist: Wie würde ein KI-Computer diese Konstellation analysieren und wie würde seine Schlußfolgerung sein.
#12:45 Langevin hat ein vermeintliches Paradox zur Diskussion gestellt “… dass von zwei Uhren jede gegenüber der anderen nachgeht.” was schon nicht geht, weil die Uhren baugleich sein sollen.
Langevin hat in die SRT hineininterpretiert, was nicht zu ihren logischen Voraussetzungen gehört.
Die SRT ist konsistent, man darf ihr nur nicht prädikativ unterstellen, was sie analytisch nicht sagt.
Die “Fehler” wurden “auseinander genommen” und das falsch formulierte Paradox gelöst.
Ein Paradox ist kein Widerspruch, nur Fehlinterpretation, da gibt es für KI nichts zu entscheiden.
Ein Paradox ist für jeden durchblickenden Nachdenker lösbar, ein Computer ist dafür kein Ersatz.
Finland will möglichst viele Finnen AI-Techniken beibringen. Und zwar Nicht-Programmierern. Vorerst sollen 1% der Finnen in AI-Techologien geschult werden, also 55’000. 10’500 haben bereits eine Schulung erhalten und 250 finnische Firmen wollen ihr gesamtes Personel dafür schulen.
Dies berichtet der MIT-Review-Artikel A country’s ambitious plan to teach anyone the basics of AI. Der letzte Satz des Artikels lautet (übersetzt von DeepL): Im Prozess der Behauptung seiner Beteiligung an der globalen KI-Wirtschaft baut Finnland seine Führung also auf eine andere Weise aus: indem es anderen Ländern zeigt, wie sie die KI-Revolution integrativer [inklusiver] gestalten können. Jetzt liegt es an dem Rest der Welt zu folgen.
@ Jocelyne Lopez (Zitat: „Es ist logisch und tatsächlich ausgeschlossen, dass von zwei Uhren jede gegenüber der anderen nachgeht.“ Wie würde ein KI-Computer diese Konstellation analysieren und wie würde seine Schlußfolgerung sein.)
Es gibt tatsächlich KI-Programme, die aus Experimenten und Messungen selber Naturgesetze postulieren und so beispielsweise bereits korrekte Gleichungen für Doppelpendel aufgestellt haben. Darüber berichtet der MIT-ArtikelAn AI physicist can derive the natural laws of imagined universes
Der Forbes-Artikel Could Artificial Intelligence Solve The Problems Einstein Couldn’t? stellt dann sogar die Frage, ob der AI-Physiker sogar Einstein übertreffen könnte.
@Jocelyne Lopez (Zitat: “Es ist logisch und tatsächlich ausgeschlossen, dass von zwei Uhren jede gegenüber der anderen nachgeht.“ ) Das ist eine Antwort auf eine falsche Frage. Die richtige Frage lautet: Läuft für jemanden, der eine mit konstanter Geschwindigkeit relativ zu ihm selbst bewegte Uhr beobachtet, diese bewegte Uhr gleich schnell wie seine eigene falls beide Uhren (seine eigene und die beobachtete) genau gleich funktionieren. Die richtige Antwort dazu ist: Nein, die bewegte Uhr scheint langsamer zu laufen – allerdings nur, wenn die bewegte Uhr sich mit konstanter Geschwindigkeit relativ zum Beobachter bewegt. Es gilt nicht, wenn sich das beobachtete Objekt beschleunigt, wie der Artikel Do moving clocks always run slowly? zeigt.
Zitat Martin Holzherr: „Die richtige Frage lautet: Läuft für jemanden, der eine mit konstanter Geschwindigkeit relativ zu ihm selbst bewegte Uhr beobachtet, diese bewegte Uhr gleich schnell wie seine eigene falls beide Uhren (seine eigene und die beobachtete) genau gleich funktionieren. Die richtige Antwort dazu ist: Nein, die bewegte Uhr scheint langsamer zu laufen – allerdings nur, wenn die bewegte Uhr sich mit konstanter Geschwindigkeit relativ zum Beobachter bewegt.“ [Hervorhebung durch J. Lopez]
.
.
In Ihrer Antwort gibt es gleich eine wichtige Aussage, die einen grundlegenden Kritikpunkt der SRT darstellt und seit 100 Jahren konsequent und ungebrochen entgegengehalten wird:
“Schein“ ist nicht „Sein“ !
Eine bewegte Uhr läuft nicht langsamer, sondern „scheint“ für einen entfernten Beobachter langsamer zu laufen (logischerweise wegen verspätetem Empfang der Signalübertragung, sprich wegen Laufzeit des Lichts): Dem entfernten Zwilling B „scheint“ die Uhr seines Bruders A langsamer zu laufen als seine eigene, genauso wie dem entfernten Zwilling A die Uhr seines Bruders B langsamer zu laufen “scheint” als seine eigene. Es ist lediglich eine Wahrnehmungstäuschung, denn in Wirklichkeit laufen die Uhren weiterhin synchron gleich schnell.
Damit ist zwar in der Tat der von Paul Langevin angeführte Logikbruch gelöst, dass von zwei Uhren jede gegenüber der anderen langsamer läuft, dafür ist aber die Aussage der SRT völlig Makulatur, dass die Zeit für den reisenden Zwilling B langsamer gelaufen ist und dass er langsamer gealtert ist als sein Bruder A: Wenn die beiden Uhren bei der Wiedervereinigung wieder nebeneinander gebracht werden, wird man nämlich feststellen, dass sie gleich schnell gelaufen sind – sprich, die Zwillinge treffen sich gleichaltrig wieder! Der von der SRT vorausgesagte berühmte Effekt „Zeitdilatation“ ist Makulatur, er existiert in der Realität nicht, man soll ihn verwerfen, genauso die komplette Theorie, die darauf basiert und aufbaut. Die Zeitdilatation der SRT ist eine Illusion, sie existiert nicht in der Natur.
Läuft dieser Faden jetzt auch aus dem Ruder mit OT-Krams einer Propagandistin?
@ Jocelyne Lopez (Zitat: Wenn die beiden Uhren [vom Ruhenden und dem Sternenreisenden] bei der Wiedervereinigung wieder nebeneinander gebracht werden, wird man nämlich feststellen, dass sie gleich schnell gelaufen sind)
Beide Uhren zeigen tatsächlich die gleiche Zeit an, wenn sie zu zwei Reisenden gehören, die sich gleichzeitig von der Erde aus (als Beispiel) zu einem anderen Planeten je in entgegengesetzte Richtung auf die Reise machen und sie am Schluss wieder auf der Erde zusammenkommen. Sobald aber einer auf der Erde bleibt und nur der andere die Reise unternimmt, stimmt das nicht mehr.
Fazit: Die Asymetrie machts!
@ Martin Holzerr: “Sobald aber einer auf der Erde bleibt und nur der andere die Reise unternimmt, stimmt das nicht mehr. Fazit: Die Asymetrie machts!”
.
Genau, die Asymmetrie machts! 😉 Das Relativitätsprinzip Einsteins, das eine Symmetrie der Effekte voraussagt, ist falsch und kann keine universalen physikalischen Gesetze beschreiben – zumal es im Universum keine geradlinige, gleichförmige und kräftefreie Bewegung (“Inertialsystem”) gibt, wie er sie in seinem Postulat zugrunde gelegt hat: Alles rotiert und dreht sich im Universum, nichts ruht.
Jetzt habe ich eine andere Frage bzgl. der zu erwartenden Leistungen von KI.
Mit dem Beispiel des Zwillingsparadoxons bin ich davon überzeugt, dass auch ein KI-Computer sofort die Aporie erkannt und abgelehnt hätte, die im Satz von Paul Langevin moniert wurde:
„Es ist logisch und tatsächlich ausgeschlossen, dass von zwei Uhren jede gegenüber der anderen nachgeht.“
Ein KI-Computer hätte es sofort als Fehler erkannt und abgelehnt, und keine quantitative Ergebnisse geliefert, weil schon ein ganz normaler Computer es ablehnen würde: Das ist nämlich eine ganz einfache logische und mathematische Ungültigkeit der Art a<b und b<a oder 3=7.
Ich frage mich aber, ob ein KI-Computer in der Lage gewesen wäre, diese logische Unmöglichkeit zu lösen, so wie Herr Holzherr sie gelöst hat: Die Uhren gehen nicht gegenseitig langsamer, sie scheinen nur gegenseitig langsamer zu gehen.
Denn um diese Lösung zu geben, müsste der KI-Computer wie Herr Holzherr wissen, dass wir Menschen die Welt einzig mit unseren sinnlichen Wahrnehmungen erkennen. Ein KI-Computer hat aber keine sinnlichen Wahrnehmungen der Welt, er ist ja kein Mensch, er hat nur gelernt Bilder aus der Welt sicher zu erkennen, zum Beispiel ein Apfel oder eine Birne, eine Uhr und eine andere Uhr, aber er weiß nicht, dass wir Menschen in bestimmten Situationen Opfer von Wahrnehmungstäuschungen sind. Wie sollte er es wissen?
Meiner Meinung nach hätte ein KI-Computer nicht die Lösung des Zwillingsparadoxons geben können, die Herr Holzherr einfach aus der la main gegeben hat: Die Uhren gehen nicht gegenseitig langsamer, die einzige Möglichkeit ist, dass sie langsamer zu gehen scheinen. Ein KI-Computer hätte nur gesagt: Die Uhren gehen nicht gegenseitig langsamer, Punkt, fertig, aus.
Ich weiß nicht, ob ich meine Frage verständlich formuliert habe. 🙁
#15:46 “Das Relativitätsprinzip Einsteins, das eine Symmetrie der Effekte voraussagt, ist falsch … ”
Was hat den Einstein mit dem Relativitätsprinzip falsch gemacht, wenn es auf Galilei/Newton zurückgeht und seitdem in der Physik grundlegend ist und x-fach experimentell bestätigt wurde?
Er hat es 1905 nur so umgesetzt wie es vorher der bekannte Poincare 1904 modern formuliert hat:
„Das Prinzip der Relativität, nach dem die Gesetze der physikalischen Vorgänge für einen feststehenden Beobachter die gleichen sein sollen wie für einen in gleichförmiger Translation fortbewegten, so daß wir gar keine Mittel haben oder haben können, zu unterscheiden, ob wir in einer derartigen Bewegung begriffen sind oder nicht.“ Die Kommentatorin verfolgt hier ihr vordergründiges Ziel: Desinformation ala Litfaßsäule.
zur Beachtung wegen der aufgewärmten OT-Propaganda: https://scilogs.spektrum.de/menschen-bilder/zum-verhaeltnis-von-glauben-philosophie-und-naturwissenschaft/#comment-35193
Die scilogs sollten sich endlich bzgl des Mißbrauchs der “Tagebücher der Wissenschaft” positionieren.
@ Herr Senf: “Was hat den Einstein mit dem Relativitätsprinzip falsch gemacht, wenn es auf Galilei/Newton zurückgeht und seitdem in der Physik grundlegend ist und x-fach experimentell bestätigt wurde?”
.
Einstein hat falsch gemacht, dass er das kinematische Relativitätsprinzip von Galilei/Newton als dynamische Relativitätsprinzip umgewandelt hat. Er hat Kinematik und Dynamik gleichgesetzt.
Die Kinematik ist die geometrische Betrachtung einer relativen Bewegung zwischen zwei Objekten ohne Berücksichtigung von Kräften und sonstigen physikalischen Eigenschaften. Es ist zum Beispiel völlig egal zur Berechnung einer Kreisbahn, ob man kinematisch betrachtet, dass die Erde ruht und die Sonne sich um die Erde dreht, oder andersrum dass die Sonne ruht und die Erde sich um die Sonne dreht, es gilt exakte Symmetrie. Das kinematische Relativitätsprinzip Galilei/Newton ist richtig.
Die Dynamik ist die Betrachtung einer Bewegung unter Berücksichtigung von Kräften und sonstigen physikalischen Eigenschaften. Hier gilt bei einer Relativbewegung zwischen zwei Objekten das Relativitätsprinzip Galilei/Newton nicht, es gilt keine Symmetrie, sondern Asymmetrie: Man benötigt zum Beispiel eine andere Kraft um einen Zug auf eine bestimmte Geschwindigkeit zu bewegen, als um einen Bahnhof auf eine bestimmte Geschwindigkeit zu bewegen…
Und hier frage ich mich eben, ob ein KI-Computer in der Lage wäre, diesen Denkfehler Einsteins zu erkennen und abzulehnen. Daran habe ich eben Zweifel. Gut, man kann einem KI-Computer ohne weiteres die gesicherten Gesetze der Kinematik und der Dynamik beibringen, kein Problem. Aber wäre der KI-Computer in der Lage zu erkennen, dass man in einer bestimmten physikalischen Konstellation diese Gesetzen unzulässig verwechselt und vermischt hat? Dazu braucht man Analysefähigkeit und so wie ich das verstanden habe, besteht die Stärke von KI nicht aus Analysefähigkeit, sondern aus der Aufschlüsselung von komplexen kausalen Wechselwirkungen, wie zum Beispiel im Fall der Proteinfaltung.
Hallo Frau Lopez,
ich möchte Sie bitten, in diesem Blog nur über die Themen dieses Blogs zu diskutieren und diesen Blog nicht zum Leugnen einer wissenschaftlichen, theoretisch und experimentell fundierten Theorie zu missbrauchen, wie es die Relativitätstheorie ist. Dafür gibt es esoterische und andere Foren. Ich werde mit Ihnen auch nicht über einen der größten Denker der Menschheitsgeschichte Einstein diskutieren. Mit Menschen, die Tatsachen leugnen, kann man nicht diskutieren. Wenn Sie hier jedoch weiter so diskutieren wie bis jetzt, muss ich Sie hier sperren. Ich möchte uns diesen Blog nicht kaputt machen lassen.
Mit freundlichen Grüßen
Jaromir Konecny
Ich wurde mit dem Beispiel der Proteinfaltung davon überzeugt, dass KI in der Tat fantastische Leistungen bringen kann, die um ein vielfaches die menschlichen Leistungen übertreffen und außerordentliche Fortschritte in der wissenschaftlichen Forschung bringen kann.
Jedoch bin ich der Meinung, dass die Anwendung der außerordentlichen Leistungen von KI nur in bestimmten Wissenschaften sinnvoll bzw. möglich ist, und zwar in den Forschungsbereichen, wo einzig die Aufschlüsselung von wertfreien komplexen Wechselwirkungen gefordert ist. Wie zum Beispiel eben in der Genforschung, in der medizinischen, pharmazeutischen und chemischen Forschung, in der Klimaforschung oder auch zum Beispiel bei der simultanen Übersetzung von Sprachen – es wird auch bestimmt andere Forschungsbereiche geben.
Dagegen glaube ich, dass KI unbrauchbar oder sehr eingeschränkt anwendbar ist in Wissenschaften bzw. Bereichen, wo menschliche subjektive Informationen wie Sinneseindrücke, Wahrnehmungen, Emotionen, Gefühle und psychische Zustände eine wesentliche Rolle spielen, wie zum Beispiel Wirtschaft, Politik, Physik, Soziologie und sonstige gesellschaftliche Vorgängen. Das haben weiter oben die Teilnehmer Karl Bednarik und Martin Holzherr kurz angeschnitten. Denn KI kann nichts anfangen mit Sinneseindrücke, Wahrnehmungen, Gefühle und psychischen Zuständen. Ein KI-Computer kann sie auch nicht lernen, weil er dazu die gesamte Biologie und das komplette Gehirn eines Menschen haben müsste, nicht nur das Merkmal des abstrakten kausalen Denkens. KI ist kein Mensch, und wird wohl nie in der Lage sein, mit den Sinneseindrücken, Wahrnehmungen, Gefühlen und Psyche von Menschen umzugehen und hier brauchbare Leistungen zu Zukunftsprognosen und zu Problemlösungen zu bringen. Da müssen wir wohl weiterhin mit unserem eigenen Gehirn zu Problemlösungen kommen. Das wird also aus meiner Sicht sozusagen nur eine halbe Revolution, der “Supermensch” ist nicht in Sicht. 😉
@Martin Holzherr:
Solange es nicht bedeutet, das Verständnis um diese Schwächen und Unvermögen gnadenlos auszunutzen, um sie zu entfernen, ist Alles in Ordnung – andernfalls Terminator. 😀
Wir schaffen die AI nach unserem Abbild – inkl. unserem Verständnis, unseren Stärken und, was am wichtigsten ist, unseren Schwächen. (gez. Gott) 😆
Mit AI Schmerzen bei Rennpferden erkennen und ANYMal das Gehen beibringen
1)KI kann in Videos von Rennpferden Schmerzen besser erkennen als es Veterinäre kennen
2) Neuronale Netze können vierbeinigen Robotern zu schnellerem, geschickterem Laufen und zu besserem Wiederaufstehverhalten nach einem Sturz verhelfen.
Dies sind zwei aktuelle Beispiele, die wie AlphaFold zeigen, dass mit künstlichen neuronalen Netzen Aufgaben bewältigt werden können, an denen Menschen bisher gescheitert sind, gescheitert wegen dem fehlenden präzisen Blick 1) oder der hohen Komplexitität 2)
Automatisch aus Videos erkennen, dass ein Pferd Schmerzen hat
In Dynamics are Important for the Recognition of Equine Pain in Video wird über eine DeepLearning-Methode ( Convolutional LSTM) berichtet, welche aus Videos von Rennpferden bestimmt ob diese an Schmerzen leiden – und das mit besseren Resultaten als bei Befragung von Tierärzten (Yet, on average the experts perform 18.9 per-
centage points (p.p.) worse than the best C-LSTM-2). Mich verwundert das nicht: Der Mensch achtet in Videos nur auf Dinge, die er aus seiner Erfahrung kennt, während ein künstliches neuronales Netz vollkommen unvoreingenommen ist und lediglich versucht aus verifizierten Fällen von Videos, die Pferde mit Schmerzen zeigen, ein Muster zu finden welches zum Label “Pferd mit Schmerz” generell passt.
Einem vierbeinigen Roboter das Gehen, Fallen und Aufstehen beibringen
Learning agile and dynamic motor skills for legged robots berichtet detailliert, dass ein künstliches neuronales Netzwerk es viel besser schafft, einem vierbeinigen Roboter names ANYMal das Laufen, richtige Umfallen und Wiederaufstehen beizubringen, als dass selbst wochenlange Programmierbemühungen können. In diesem Beispiel wird ein Simulator benutzt um einem simulierten vierbeinigen Roboter das Gehen beizubringen und anschliessend wird das erzeugte Programm ohne Änderung in den realen Roboter geladen und ist ohne Änderung für den Realfall einsetzbar.
Dieser Bericht geht sehr detailliert auf die Schwierigkeiten der manuellen Konfiguration und Programmierung des Gehverhaltens eines vierbeinigen Roboters ein und kommt zum Schluss, dass solche Aufgaben heute eigentlich nur mit neuronalen Netzwerken optimal herauskommen. Es gibt also momentan keine Alternative zu neuronalen Netzwerken, wenn man einem Roboter das optimale Gehen und Laufen beibringen will.
Zitat Martin Holzherr: „Mit AI Schmerzen bei Rennpferden erkennen und ANYMal das Gehen beibringen
1) KI kann in Videos von Rennpferden Schmerzen besser erkennen als es Veterinäre kennen“
.
Großartig!!!!!
Das fügt sich wohl im Rahmen der besseren Leistung von KI bei medizinischen Diagnosen, die Sie weiter oben angesprochen haben.
Ich bin im Bereich der medizinischen Anwendung von KI zuversichtlich, dass hier große Fortschritte zu erwarten sind. Zum Beispiel erhoffe ich mir auch von KI das baldige Ersatz der Tierversuche, wie es sich bereits in der Forschung anzeichnet.
KI und DL können nicht Grundlagenforschung ersetzen, nur die Ergebnisse besser aus-/verwerten.
@Senf:
Unreflektierte Thesen eurer Vordenker (z.B. Einstein) aber auch nicht.