

Künstliche neuronale Netze und Abstraktion in der Bilderkennung

Künstliche neuronale Netze sind längst Experten in der Erkennung von Objekten und Tätigkeiten in Fotos und Videos. Deshalb haben Informatiker*innen den nächsten Meilenstein ins Visier genommen: die Abstraktion. Künstliche neuronale Netze sollen aus dem, was sie sehen, allgemeine Schlussfolgerungen ziehen. Dafür nutzen Forscher*innen die hierarchischen Beziehungen, die in den Bedeutungen von Wörtern eingebettet sind und verknüpfen sie mit der Bilderkennung.
In Intelligenztests wird häufig ein Test benutzt, der die Testperson auffordert, Gemeinsamkeiten zu finden, z. B.: Von fünf Wörtern sind vier in einer gewissen Weise einander ähnlich. Finde das fünfte Wort heraus, das nicht in diese Reihe passt. a) Tisch b) Sessel c) Schrank d) Bett e) Taube
Menschen können wissen, dass die Wörter a) – d) etwas gemeinsam haben. Es sind Bezeichnungen für Möbel. Das Wort e) jedoch bezeichnet ein Tier. Dieses Wissen haben Menschen irgendwann erlernt und ihrem Langzeitgedächtnis gespeichert. Wie dieses Wissen gespeichert wird, dazu entwickelte der Sprachwissenschaftler Ross Quilian 1969 die folgende Hypothese: Wissen über Worte und ihre Bedeutung wird als hierarchisches Netzwerk von Begriffen und ihren Beziehungen (Relationen) dargestellt, das semantische Netz.
Wie wird Abstraktion in einem semantischen Netz umgesetzt? Durch eine Abstraktionsrelation. Die Abstraktionsrelation ist eine hierarchische Relation zwischen zwei Begriffen, von denen der untergeordnete Begriff (Unterbegriff) alle Merkmale des übergeordneten Begriffs (Oberbegriff) besitzt und zusätzlich mindestens ein weiteres spezifizierendes Merkmal. Ein Beispiel: Oberbegriff Tier, Unterbegriff Vogel. Meist wird ein semantisches Netz durch einen Graph repräsentiert. Die Knoten des Graphen stellen dabei die Begriffe dar. Beziehungen zwischen den Begriffen werden durch die Kanten des Graphen realisiert.
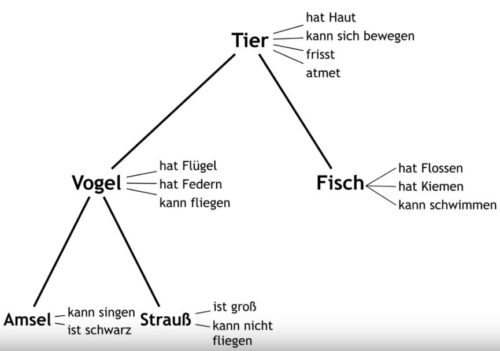
Allgemein gilt, dass Expert*innen auf ihrem Gebiet differenziertere und umfangreichere semantische Netze als Menschen, die unkundig auf dem Gebiet sind. Zoolog*innen haben differenziertere und umfangreichere semantische Netze zum Thema Tiere als unkundige Menschen. Sie kennen mehr Tiere und sie kennen mehr Merkmale zu einzelnen Tieren.
Wie die Nervenzellen des menschlichen Gehirns können auch künstliche neuronale Netze (KNN) durch Deep Learning, einer speziellen Form des maschinellen Lernens, semantische Netze bilden. Die Informatiker*innen Camilo Fosco, Alex Andonian, Mathew Monfort und Aude Oliva vom MIT, IBM und der Columbia Universität in den USA haben in einem Deep Learning-Modell (DLM) Bilderkennung mit einem semantischen Netz kombiniert und das DLM trainiert, einen Abstraktionstest für Tätigkeiten zu lösen [1]. In diesem Abstraktionstest zeigen die Forscher*innen dem DLM Videos, in denen Menschen, Tiere oder Maschinen verschiedene Dinge tun. In jedem Video wird nur eine Tätigkeit gezeigt.
Die Videos stammten aus zwei Datensätzen zum Training von Künstlichen Intelligenz (KI)-Systemen für die Handlungserkennung (Action Recognition): MIT’s Multi-Moments in Time und DeepMind’s Kinetics. Ihr Modell schnitt bei zwei Arten von visuellen Schlussfolgerungen genauso gut oder sogar besser ab als Menschen – das Video auszuwählen, das konzeptionell am besten zu der Menge passt, die Vervollständigungsaufgabe und das Video auszuwählen, das nicht passt, die Aussortierungsaufgabe. Wurden beispielsweise Videos eines bellenden Hundes und eines heulenden Mannes neben seinem Hund gezeigt, wählte das Modell bei der Vervollständigungsaufgabe aus einem Satz von fünf Videos das weinende Baby aus.

“Begriffe ermöglichen es uns, Kontextinformationen, die wir aus Textdatenbanken gelernt haben, in die Bilderkennung zu integrieren”, sagt Co-Autor Mathew Monfort, Forscher am Computer Science and Artificial Intelligence Laboratory (CSAIL) des MIT. “Wörter wie ‘Laufen’, ‘Heben’ und ‘Boxen’ haben einige gemeinsame Merkmale, die sie zum Beispiel enger mit dem Konzept ‘trainieren’ bündeln als ‘fahren’.”
Es gab auch ein bißchen unerwartete Ergebnisse. In der Vervollständigungsaufgabe schlug das Modell, nachdem es ein Video sah, in dem jemand ein Geschenk einpackt und ein Video, in dem jemand einen Gegenstand mit Klebeband abdeckt, ein Video vor, in dem jemand am Strand jemand anderen im Sand vergräbt. “Konzeptionell passt es, aber ich musste darüber nachdenken, da die Videos noch andere visuelle Merkmale zeigten.”, sagt Camilo Fosco, ein Doktorand am MIT, der zusammen mit dem Doktoranden Alex Andonian Erstautor der Studie ist. Das Modell hat die Tendenz, einige Merkmale überzubetonen. In einem Fall schlug es vor, eine Reihe von Sportvideos mit einem Video von einem Baby und einem Ball zu vervollständigen, da Bälle offenbar mit Bewegung und Wettbewerb assoziiert werden.
Die Wissenschaftler*innen hoffen: Ein Modell, das abstrahieren kann, wird genauere, logische Vorhersagen machen und für die Entscheidungsfindung nützlicher sein. Zusätzlich wird es vielleicht weniger Daten zum Lernen brauchen. “Ein Kennzeichen der menschlichen Kognition ist unsere Fähigkeit, etwas in Relation zu etwas anderem zu beschreiben – zu vergleichen und zu kontrastieren”, sagt Aude Oliva, Leiterin der Studie. “Es ist eine reichhaltige und effiziente Art zu lernen, die schließlich zu maschinellen Lernmodellen führen könnte, die Analogien verstehen können und so viel näher daran sind, intelligent mit uns zu kommunizieren.”
Weiterführende Literatur
Sprachenlernen und die Evolution des menschlichen Gehirns
Plato und die Papageien: Zur Naturgeschichte des Geistes
Ja, Daten in der „richtigen“ Art miteinander zu verknüpfen, auch begrifflich, ist etwas was der Mensch ständig tut, was aber nicht zu den eingeborenen Fähigkeiten von neuronalen Netzen gehört.
Erst jetzt beginnen AI-Forscher sich um solches Beziehungswissen zu kümmern. Dazu gehört auch die Multimodalität, also etwa die Fähigkeit Worte mit Bildern in Verbindung zu bringen oder das Erkennen von Handlungsabläufen und Handlungsabsichten oder die Fähigkeit, vorauszusagen, was als Nächstes passiert. All diese Fähigkeiten fehlen bisher KI-Anwendungen weitgehend und damit fehlt ihnen auch das tiefere Verständnis für diese Welt. Ich denke die fehlende Fähigkeit, Beziehungen zwischen Objekten zu erkennen ist auch mit ein Grund, dass heutige Anwendungen der künstlichen Intelligenz nicht kausal denken können, sie also Ursache und Wirkung von etwas weder kennen noch erkennen.
Doch das soll sich jetzt ändern. Es gibt zunehmend KI-Forschung, die versucht, abstraktere Konzepte in Bildern und Videos zu erkennen. Ein Beispiel dafür ist der Artikel GROUNDING PHYSICAL CONCEPTS OF OBJECTS AND EVENTS THROUGH DYNAMIC VISUAL REASONING vom 31.3.2021. Hier wird versucht, aus Videos visuelle Konzepte zu extrahieren und Fragen zum gegenseitigen Verhältnis von bewegten Objekten zu beantworten. Der dabei implementierte Visual Concept Learner kann dann auf die Frage „Was passiert als Nächstes“ etwa bei einem Video, das bewegte Objekte zeigt, folgendes antworten: Die blaue Kugel und das gelbe Objekt kollidieren.
Menschen scheint das eine leichte Aufgabe, für KI-Programme ist das aber bis heute kaum zu bewältigen. Die Forscher mussten dem Visual Concept Learner unter anderem die Fähigkeit geben, Objekte über längere Strecken eines Videos zu verfolgen, zu tracken und ihre weitere Bahn vorauszusagen. .
KI wird tatsächlich immer besser. Irgendwann wird sie von einer Kuriosität zu einem Alltagsphänomen werden und KI-Assistenten werden die Welt und sogar uns nicht nur mit ihren übermenschlichen Leistungen beeindrucken, sondern sie werden uns sogar verstehen.
Stellen Sie sich vielleicht vor, Herr “Holzherr”, die doppelten Anführungszeichen nur deswegen weil Sie nicht so heißen und ein als solches unerkennbares Pseudonym verwenden, dass “AI” über viele, viele Kameras einen Planeten beobachtet, vielleicht den Mond, um dann selbst anzufangen Objekte zu erkennen und Regeln zu bilden.
Korrekt, ein wenig “Spielmaterial” muss bereit stehen, wir lassen einfach für die gedachten Zwecke ein paar robotische Freunde auf dem Mond Fußball spielen, gedacht wiederum.
Dann könnte “AI” Regeln entwickeln und gerne auch auf eine Art und Weise dem gewohnten erkennenden Subjekt verfügbar machen, geeignete Schnittstellen vorausgesetzt, auch geeignete Sprachlichkeit, und vielleicht würde dann bspw. ein Gravitationsgesetz entwickelt werden können, vielleicht würden dann auch bessere und schlechtere “Moves” unserer robotischen Freunde von der “AI” erkannt werden können, insbesondere nachdem erkannt worden ist, dass das “Runde” ins “Eckige” muss?
Dies hier – ‘dass heutige Anwendungen der künstlichen Intelligenz nicht kausal denken können’ – ist Bull, natürlich kann sozusagen kausal auch von einer oder der “AI” gedacht bzw. entwickelt werden.
Bonusfrage : Was ist Kausalität? Mehr als (empirisch adäquate) Feststellung von (scheinbaren) Regeln, die in der Natur vorkommen, vorzukommen scheinen?
Mit freundlichen Grüßen
Dr. Webbaer
Korrekt, kollekt sozuagen, der Mond ist kein Planet.
Er könnte abär so sein!
Namen und Konstrukte, die Konzepte meinen, werden letztlich wahlfrei vergeben.
Betrifft Vergleich semantisches Gedächtnis : Tisch, Sessel, Schrank, Bett, Taube…
Ich verstehe zwar ihre Interpretation dieser “Logik”, kann/muss aber auch anders assoziieren. Versetzen sie sich in eine größere Menschenrunde(Stammtisch etc.) und verfolgen sie diese wilden Assoziationsketten. Da kann diese mit der Taube durchaus einen Sinn bekommen wenn Person A auf einen Sessel zu sprechen bekommt , worauf Person B unmittelbar eine Taube assoziiert die letztens erst auf seinen Sessel im Garten geschissen hat. Die Logik ist hier das persönliche Erlebnis bzw. die persönliche Erfahrung die ihr semantisches Netz unlogisch machen. Künstliche Intelligenz wird den Ärger von Person A mit der Taube incl. Reinigungskosten nicht nachvollziehen können da es nach objektiven Mustern assoziiert und dementsprechend “objektive “Gedanken entwickelt, was bei Menschen ,wo jeder seinen persönlich erlebten Taubenschiss hat, nicht möglich ist.
@Golzower (Zitat):
KI hat keine objektiven Gedanken, sondern es hat als Basis ein Trainingsset und alle Vorurteile, Rassismen und Sexismen, die beispielsweise in den Trainigstexten vorkommen, die werden von der künstlichen Intelligenz übernommen. Sie können sicher sein, dass Sprachgeneratoren und Chatbots nicht in Verlegenheit kommen, wenn man ihnen einen sexistischen Witz vorsetzt, denn in ihrem Trainingsset (oft fast das ganze Internet) kommt das zur Genüge vor. „Objektive“ Gedanken gibt es insoweit gar nicht, denn heutige künstliche Intelligenzen haben gar keine wirklich eigenen Gedanken. Sie lernen vielmehr Sprache ähnlich wie sie ein Computerspiel erlernen: durch Ausprobieren und geschicktes Kombinieren von bereits vorgefundenen Elementen.
Folgerung: Wenn die KI-Anwendung über die hier Joe Dramiga berichtet, in der Liste Tisch, Sessel, Schrank, Bett, Taube die Taube als nicht passend einstuft, dann, weil sich dies aus ihrem Training so ergibt.
Hier haben sie recht: die KI weiss nicht warum das Trainingsset so aufgebaut ist wie es aufgebaut ist, denn die KI lernt die Welt nur über das Trainingsset kennen und ist heute noch nicht in der Lage über das nachzudenken womit sie gefüttert wird – geschweige denn darüber nachzudenken wie Assoziationen zustande kommen.. Sie kann also nicht ihre eigene Basis analysieren. Ihr fehlt die Selbstkritik und die Fähigkeit über sich selbst nachzudenken.
Nun ja, das fehlt ja auch vielen Menschen.
Es geht hier ja nicht um Assoziationen, die von persönlichen Erlebnissen inspiriert sind, sondern um Merkmale, die ein Objekt oder eine Tätigkeit charakterisieren bzw. definieren. Diese Merkmale sind kulturell tradiert sowohl vertikal von Eltern zu Kindern als auch horizontal zwischen verschiedenen Gruppen der Gesellschaft und ermöglichen uns so miteinander zu kommunizieren.
Im Kern ordnet das hier vorgestellte Videoanalyseprogramm Modeling Semantic Relational Set Abstractions in Videos jedem Video einen Platz in Wordnet zu. Wordnet ist eine grosse Wortdatenbank und gruppiert englische Wörter/Begriffe zu Synonymgruppen (Synsets), welche dann untereinander verlinkt sind über die Oberbegriff-/Unterbegriffrelation. Beispiel: Automobil, Wagen und Personenkraftwagen gehören in eine Synonymgruppe und diese hat als Oberbegriff Fahrzeug. Auch Fahrzeug hat einen Oberbegriff und irgendwann landet man beim Aufsteigen bei Entität/Objekt. Auch Barak Obama kommt in Wordnet vor, nämlich als Instanz eines US-Präsidenten/Expräsidenten (Joe Dramiga wäre dann eine Instanz von was?). Auch eine Teil-/Ganzes Relation wird in Wordnet unterhalten und Wagenrad und Steuerrad würden wohl in einer Synonymgruppe landen, die einen Link zum Automobil besitzt.
Allerdings wollten die Autoren des hier besprochenen Programms nicht Objekte in Videos erkennen, sondern Tätigkeiten/Ereignisse wie etwa Laufen, Gewichteheben, Boxen, etc. Aber auch das kommt in Wordnet vor und hätte als Oberbegriff in diesem Fall Trainieren/Sport treiben. Doch die Autoren haben Wordnet trotzdem etwas erweitert/angepasst um alles was in den Videos vorkommt, begrifflich zu erfassen.
Wenn ein Video einmal einem oder auch mehreren Begriffen/Konzepten in Wordnet zugeordnet ist, dann kann das Programm nun Fragen zur Einordnung des Videos (hey, ist es ein Sportvideo?) einfach dadurch beantworten, dass es im zugehörigen Wordnet-Graphen navigiert. Auch Fragen zur Ähnlichkeit von zwei Videos können so beantwortet werden. Dazu steigt man einfach bei beiden Videos zu den Oberbegriffen auf bis man zum gleichen Oberbegriff kommt. Auch die Frage welches Video nicht zu einer Gruppe von Videos passt, kann man so beantworten: hier wird man beim fraglichen Ausreisser auf einen anderen Oberbegriff stossen als bei den anderen Videos oder man muss sehr viel weiter Aufsteigen um zum gleichen Oberbegriff zu kommen.
So simpel ist das. Und so nützlich.
Und wer macht die Hauptarbeit: Wordnet wohl und das Videoanalyseprogramm, das beispielsweise erkennt, dass geboxt wird im Video.
Beurteilung: Die konzeptionelle Einordnung eines visuell erkannten Objekts/Ereignisses ist mit Sicherheit nötig, damit ein Programm anschliessend logische Schlussfolgerungen ziehen und das Gesehene in Relation zu Anderem setzen kann. Beispiel: Bild zeigt Zahnbürste neben Computermonitor. Schlussfolgerung: Dahin gehört eine Zahnbürste aber nicht!. Denn: in WordNet ist die Zahnbürste Teil des Badezimmers und nicht Teil des Computerarbeitsplatzes.
Doch es braucht sicher noch mehr um Künstlicher Intelligenz visuelles Denken beizubringen. Dazu später mehr.
KI-Programme wie das hier im Artikel (in Modeling Semantic Relational Set Abstractions ) vorgestellte Videoanalyseprogramm sind nicht im menschlichen Sinne intelligent, denn ihnen fehlt die menschliche Flexibilität, es fehlt ihnen der Hintergrund (jeder Mensch hat einen kognitiven „Hintergrund“), das Allgemeinwissen, der gesunde Menschenverstand und die Fähigkeit dazuzulernen.
Typischerweise greifen KI-Programme, die etwa sprachliche Aufgaben zu bewältigen haben auf Wörterbücher zurück welche die Wörter gemäss ihrer Verwandtschaft/Ähnlichkeit anordnen, so dass man jedem Wort schliesslich ein Set von Zahlen zuordnen kann welches es ermöglicht mit dem Wort zu „rechnen“.
Im Beispiel des hier besprochenen Programms heisst dieses Wörterbuch Wordnet. Wordnet als englischsprachiges linguistisches Wörterbuch wurde seit 1985 bewusst mit dem Ziel aufgebaut, für computerlinguistische Aufgaben geeignet zu sein, also für die maschinelle Verarbeitung von Sprache (englischer Sprache, denn es gibt keine deutschsprachige Version).
.
Wordnet ist in meinen Augen mit 117 000 Synonymgruppen (Synsets) sehr gross. Doch im Prinzip ist Wordnet nur das Resultat einer grossen Fleissarbeit.
Vorschlag: Wie wärs ein KI-Programm zu bauen, das selber in der Lage ist, das Lexikon Wordnet aufzubauen und zu unterhalten. Beispielsweise durch Analysieren von Badezimmern. Dieses KI-Programm würde für diese Unteraufgabe einfach Bilder von tausenden von realen Badezimmern analysieren und die in den Badezimmer vorkommenden Objekte dann beispielsweise dem Wordnet-Eintrag für Badezimmer zuordnen und zwar in der Teile/Ganzes – Relation. Allerdings nur die Dinge, die in vielen der tausenden Badezimmern vorkommen.
( Zwischenfrage: Was für (unanständige?) Dinge kommen in vielen Badezimmern vor und wo findet man sie?) Eine gewisse Intelligenz müsste ein solches KI-Programm entwickeln, wenn es nicht nur Teilaufgaben bewältigen muss wie die zu bestimmen, was sich in einem Badezimmer typischerweise befindet, sondern wenn es sogar selber Synonymgruppen bilden soll und selber herausfinden soll, was in einer Teil-/Ganzes – Beziehung steht.
Denn ist es nicht so: Intelligent wird man/ist man wenn man einige Dinge selber durchdacht hat und all die Fallstricke entdeckt hat, die da jeweils lauern.
Es wird vor allem bei Metaphern spannend bleiben. Auch das Gemälde “Die niederländischen Sprichwörter” von Pieter Bruegels des Älteren wird für eine KI eine Herausforderung sein. Das 1559 entstandene Werk enthält über 100 niederländische Sinnsprüche und Redewendungen.
Ich habe den Eindruck das KI-Programm das im Artikel Modeling Semantic Relational Set Abstractions vorgestellt wird, benutzt sprachliche Begriffe aus WordNet um ein Video 📺 mit sprachlichen Begriffen/Konzepten zu charakterisieren. Videos werden dann nur noch anhand der extrahierten sprachlichen Konzepte miteinander verglichen wobei ausgenutzt wird, dass die sprachlichen Konzepte eingebettet sind in eine Teil/Ganzes – Relation 🐴/🐎 und eine Unterbegriff/Oberbegriff – Hierarchie.
Es sind also gar keine wirklich visuellen Konzepte, die hier gewonnen werden, sondern rein sprachliche Konzepte und weitergearbeitet wird beim Schlussfolgern dann nur noch mit diesen sprachlichen Konzepten. Doch solche in WordNet verzeichneten allgemein-sprachliche Konzepte helfen wenig, wenn es darum geht, dass etwa ein Roboter sich in einem Raum orientieren soll. Hier hilft es weit mehr, die Lagebeziehungen der Objekte relativ zueinander und relativ zu ihm als Beobachter in seinen Überlegungen und Beobachtungen einzubeziehen. Genau das wird im Artikel Commonsense Spatial Reasoning for Visually Intelligent Agents angestrebt: ein Set von qualitativen räumlichen Objektbeziehungen so aufzubauen, dass sie sowohl eine geometrische als auch sprachliche Bedeutung haben und so, dass sie so weit als möglich unabhängig vom Standpunkt der Kamera/des Roboters sind. Elemente dieses räumlichen Objektbeziehungssets sind die 1) Distanz zwischen Objekten (wobei sich Objekte bei unterschreiten einer Minimaldistanz “berühren”, sonst aber “sich nah” oder “weit voneinander entfernt” sein können),
2) das Enthaltensein eines Objekts in einem anderen oder das sich Überschneiden von Objekten
3) die beobachterabhängigen Beziehungen “Rechts von”, “Links von”, “Unterhalb”, “Oberhalb”, “Bevor” und “Dahinter” mit den Verfeinerungen “Aufliegend” (Verfeinerung von “Oberhalb”) und “Befestigt an” (Beispiel Uhr an der Wand)
Der Artikel enthält einige Beispiele wo solche räumliche Objektbeziehungen wichtige Schlussfolgerungen zulassen, Schlussfolgerungen, die sich auch sprachlich ausdrücken lassen. Hier ein Beispiel:
Die Informationen zu den Objekten Pullover und elektrische Heizung kann der Bot aus dem Sprachmodul, aus der Wikipedia und zusätzlich vielleicht aus einer Datenbank für Allgemeinwissen beziehen. Doch nur wenn die Lagebeziehung “Pullover auf elektrischer Heizung aufliegend” erfüllt ist, erst dann besteht eine Brandgefahr. Die Lagebeziehung muss der Bot in Realzeit erkennen und dann muss er noch das Allgemeinwissen besitzen, dass die Feuergefahr umso grösser ist je näher der Pullover der Wärmequelle ist.
Fazit: Räumliches Schlussfolgern ist eine eigene Kategorie über die wir so wenig reden, weil sie uns selbstverständlich ist. Für einen Roboter aber ist nichts selbstverständlich. Die Realität kann mit rein sprachlichen Mitteln nicht wirklich erfasst werden. Es gibt visuelles und räumliches Denken sogar ganz ohne Sprache – wobei es aber auch Worte und Wendungen in jeder Sprache für visuelle und räumliche Objekt- und Beobachterbeziehungen gibt.
Künstliche neuronale Netze allein wie sie im Deep Learning eingesetzt werden führen nur zu einer sehr eingeschränkten Form von Intelligenz, nämlich einer vorwiegend mustererkennenden Intelligenz ohne die Fähigkeit Schlussfolgerungen zu ziehen oder Ursache und Wirkung zu erkennen und ohne sich entwickelndes Gedächtnis, denn heutige Deep Learning Systeme lernen nach dem Training nichts Neues dazu.
Die meisten KI-Entwickler erforschen heute allein die Möglichkeiten des Deep Learning und erreichen damit zwar oft Systeme mit gar superhumanen Fähigkeiten – allerdings nur in einem sehr eingeschränkten Bereich.
Die Computational Cognitive Science -Gruppe beispielsweise um Josh Tenenbaum am MIT dagegen beschränkt sich nicht aufs Deep Learning, sondern benutzt auch Bayes Inference, probabilistisches Programmieren oder induktives logische Programmieren um menschenähnlichere Systeme aufzubauen. Ihr explizites Ziel ist nämlich menschliche Kognition nachzubilden wobei sie sich auf wahrnehmungspsychologische und verhaltenspsychologische Studien stützen.
Im Artikel Probabilistic Programming Bots in Intuitive Physics Game Play benutzen Josh Tenenbaum und seine Koautoren eine Kombination von Deep Learning in Form von Convolutional Neural Networks für die Bildererkennung und von probabilistischem Programmieren um damit kognitiv die intuitive Physik zu realisieren über die wir Menschen alle verfügen: Studien zeigen nämlich, dass Menschen bei vielen Aufgaben physikalische Vorgänge in ihrem Innern simulieren und aufgrund dieser inneren Simulationen dann versuchen sich physikgerecht zu verhalten, also beispielsweise einen Gegenstand im „richtigen“ Bogen in den Abfallkorb oder den Baseballkorb zu werfen. Das probalistische Programmieren generiert aufgrund eines Modells des zugrundeliegenden (physikalischen) Prozesses mehrere mögliche zukünftige Abläufe entsprechend den zugrundeliegenden Wahrscheinlichkeiten.
Im zitierten Papier werden nun mit Convolutional Neural Networks Szenen und Abläufe erkannt und dann werden mittels probabilistischem Programmieren die erkannten physikalischen Situationen in ihrem weiteren Ablauf simuliert um dann entsprechend zu handeln. Damit gelingt es den Autoren das Computerspiel Flappy Bird zu meistern, ein Spiel indem ein Vogel durch Schlitze in der Wand fliegen muss und deshalb nicht zu schnell und nicht zu langsam mit den Flügeln schlagen darf. Immerhin. Doch Space Invaders schafft ihr Programm noch nicht, dazu genügt ihre primitive Form der Physiksimulation noch nicht. Immerhin sympathisch, dass die Autoren auch offenlegen was ihr Programm nicht kann. Das kommt selten vor und Uneingeweihte haben darum nicht selten den Eindruck was für Wundermaschinen da am Werk seien. Dabei sieht die Realität der KI viel weniger phantastisch aus. Sympathisch auch, dass die Autoren einen einfachen Grund find3n und angeben, warum Menschen schlechter in Flappy Bird abschneiden als ihr Programm: Menschen sind einfach zu langsam, nicht zu schlecht. Konkret liest man dazu:
Fazit: Auch Menschen verwenden bei vielen Aufgaben eine Art innere Physiksimulation. Sie sind aber nicht sonderlich schnell dabei. Zum Glück ist das beim Autofahren nicht nötig. Dort genügt es eine gefährliche Situation zu erkennen und dann so schnell wie möglich auf die Bremse zu treten – heute mindestens noch, denn morgen macht das der Fahrassistent.
Sog. Deep Learning Systeme entwickeln Entscheidungs-Algorithmen, die neu sind, zweifellos, sie sind flexibel und sie sind der Evolution nachgebaut (!).
Denkbarerweise verfügt auch der hier gemeinte Primat “nur” über ‘eine sehr eingeschränkte Form von Intelligenz’, die ihm aber erlaubt Schlussfolgerungen zu ziehen und die Beweggründe für seine Folgerungen zu kommunizieren.
Sog. Deep Learning Systeme sind nicht von Kommunikation abgehalten, sie lernen aber stets ‘Neues hinzu’.
Insofern wird auch von Netzen geredet, die sich nicht um ein Zentrum scharen.
I.p. Erfolg ist Dr. Webbaer übrigens ebenfalls ein wenig missgelaunt oder a bisserl pessimistisch, denn so gemeinter Erfolg ist von bereit stehender Rechenleistung abhängig, von der allgemein verfügbaren “CPU-Zeit”, und hier ist das erkennende Subjekt, auch in seiner Historie und Altvordere meinend, nicht zu übertreffen, insofern ist “AI” auch nur gut, wenn das Gebiet streng umgrenzt ist, die zu verarbeitende Datenbasis (vergleichsweise) klein.
Böse formuliert kann sich die Erde samt “Biomaterial” als eine Art Super-Großrechner vorgestellt werden.
Schade für den Artikel, dass er hier unnötig die Gendersternchen einsetzt. Selten waren sie so störend für den Lesefluss wie in diesem Falle.
Freundlichst, Peter
Sieben sogenannte Gendersternchen werden doch den dankenswerterweise beigebrachten hiesigen Text unseres werten, netten Inhaltegebers nicht verhunzen können.
Ein achtes sog. Gendersternchen ist von Dr. Webbaer weiter unten zitierend beigefügt worden, andere machten also nicht mit.
Die Form bestimmt nie den Inhalt, kann ihn nur belasten, nie ihn befruchten oder irgendwie befördern.
(Schlimm ist nur, wenn an sich nicht von Problematik unfreie Texte auch noch durch Sprachlichkeit belastet werden, oder?)
Früher, vor vielleicht 40 Jahren, ist in der IT mit sog. Expertensystemen angefangen worden, vergleiche :
-> https://de.wikipedia.org/wiki/Expertensystem
Es gab seinerzeit auch (mindestens) eine Programmiersprache, mit der sich nicht wenige ein wenig beschäftigt haben, nämlich : Prolog.
Cooler ist es womöglich IT-Basiertes selbst in die Lage zu versetzen auf Grund von Mustererkennung zu katalogisieren, Logik, Sprachlichkeit, Regeln selbst zu entwickeln.
Dummerweise wird eine derartige Entitätenerkennung selbst fehleranfällig, was aber nicht gegen den Versuch spricht, gerade dann nicht, wenn CPU-Zeit en masse bereit steht.
IT-Basiertes selbst das Lernen lernen zu lassen.
Wobei sich ‘genauere, logische Vorhersagen’ (Warum eigentlich Vorhersagen? Wie steht es mit dem Blick in die Vergangenheit?) gerade nicht einstellen müssen, was aber ‘für die Entscheidungsfindung’ durch Ekenntnissubjekte auch nicht notwendig ist, wenn so ein kleiner (fehlbarer) IT-basierter Ratgeber zur Hand geht.
Mit freundlichen Grüßen
Dr. Webbaer