

Maschinelles Lernen
BLOG: Die Natur der Naturwissenschaft

Neulich erzählte mir ein Freund, den ich schon aus Studienjahren kenne, dass er wieder ein neues Instrument erlernt. Dieses Mal sei es das Horn. Mit dem Klavier war er groß geworden, hatte Flöten aller Art ausprobiert und hat dann lange Fagott gespielt. Da er aber mit zunehmenden Alter die Klappen des Fagotts nicht mehr gut bedienen kann, will er sich nun dem Hornspiel widmen. Er berichtete mir von der Schwierigkeit bei einer Intonation, von der ständigen Gefahr, dass man einen Kickser statt eines klaren Tons hervorbringt; und als er uns ein Stück aus der Hornschule vorspielte, erahnte ich, wie viel Fleiß und Ausdauer man wohl benötigt, um erst einmal einige saubere Töne hinter einander zu Gehör bringen zu können. Was mich aber am meisten aufhorchen ließ, war seine Aussage: “So ein Erlernen eines Instruments ist doch eine sichere Sache; man muss eben nur regelmäßig üben. Mit der Zeit kommt immer etwas dabei raus.”
Daran dachte ich wieder, als mir etwas später ein Pianist vorrechnete, wie viel Stunden jemand geübt hat, der mit 5 Jahren angefangen, regelmäßig Klavier zu spielen gegenüber einem, der dieses erst mit 65 beginnt. Allein, dass die Anzahl der Übungsstunden als ein Maßstab genutzt wird, wies wieder in die Richtung, die auch der Volksmund zusammenfasst mit dem Spruch: “Übung macht den Meister”. Jeder hat ähnliche Erfahrungen. Auch ein noch so intelligenter Mensch kann nicht aus dem Stand ein Instrument spielen oder eine fremde Sprache flüssig sprechen. Man muss so etwas einüben – und darüber ein anderer Mensch werden: Im Kopf – und bei einem Instrument auch im ganzen Körper -muss sich etwas ändern; bestimmte Muskeln und neuronale Verknüpfungen im Kopf müssen wachsen. Lernen ist also in erster Linie ein biologischer Prozess und jeder hat schon mal das Gefühl gehabt, dass sich über Nacht etwas gerade Erlerntes “gesetzt” hat und man anderntags erfreut über einen unerwarteten Lernfortschritt war.
Das Thema “Lernen” ist ein weites Feld (siehe z.B. Wikipedia: Lernen). Ich will aber nicht versuchen, dieses in irgendeiner Weise zu durchqueren, sondern möchte ein ganz spezielles Teilgebiet etwas ausleuchten, in dem angeknüpft wird an die Erkenntnis, dass sich beim Lernen im Kopf etwas ändert. Dieses ist das so genannte maschinelle Lernen, das Lernen eines Rechners oder eines Roboters. Hier geht es also wieder darum, geistige Leistungen von Menschen durch eine Maschine nachzumachen. Man verspricht sich dabei nicht nur eine Entlastung der Menschen in vielen Routineaufgaben sondern auch neue Einsichten in den Prozess des Lernens. Denn wie immer gilt: Kann man etwas nachmachen, hat man schon sehr viel davon verstanden.
Künstliche neuronale Netze
In unseren Rechnern werden Algorithmen abgearbeitet, also eine Folge von Rechenvorschriften durchgeführt (siehe meinen Beitrag “Was ist ein Algorithmus”). Der Rechner produziert dabei in der Regel mit Hilfe eines Algorithmus aus einer Eingabe, der dem vorliegendem Problem angepasst ist, ein Resultat. Von Algorithmen profitieren wir heute jeden Tag in unserem Alltag, beim Suchen, beim Sortieren und Klassifizieren von Daten aller Art, bei der Bearbeitung von Bildern, bei einer Schrift-, Sprach- oder Mustererkennung. Solche Aufgaben verlangen eine bestimmte Intelligenz und so hat sich für das Gebiet der Informatik, in dem solche Algorithmen entwickelt und studiert werden, der Name “künstliche Intelligenz” gebildet.
Entsprechend nahe lag auch die Idee, die Struktur der Algorithmen so zu gestalten, als wenn sie auf einem Netz abgearbeitet würden, deren Knoten so gestaltet sind, dass sie ähnlich wie Neuronen in unserem Gehirn funktionieren, d.h. selbst kleine Module bilden, die einen “Reiz”, d.h. eine Eingabe verarbeiten und an andere Neuronen weiterleiten. Meistens ist dann solch ein Netz in Schichten geordnet, wobei jedes Neuron einer höheren Schicht mit den Neuronen der niedrigeren Schicht verbunden ist. Die Zustände der Neuronen der untersten Schicht sind durch die Eingabe bestimmt, und der Zustand eines jeden Neurons der nächst höheren Schicht ergibt sich in bestimmter Weise aus den Zuständen der unteren Schicht und der Stärke der Verbindungen.
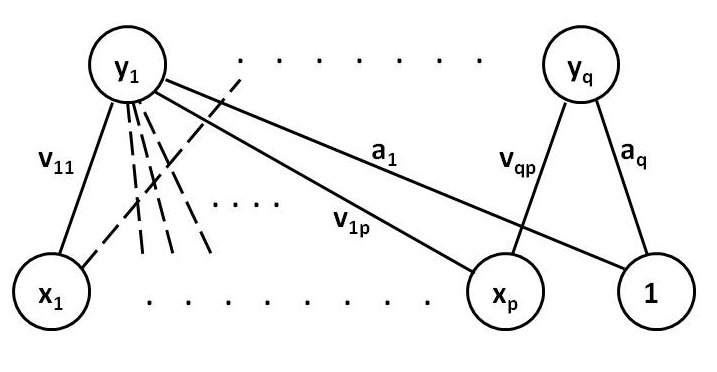
Abb. 1. Schema eines einfachen künstlichen neuronalen Netzes mit nur zwei Schichten. Die Punkte stehen für weitere Neuronen oder Verbindungen. Nicht alle möglichen Verbindungen sind angedeutet. Die Buchstaben bezeichnen den Zustand der Neuronen oder die Stärke der Verbindung bzw. Parameter in der Formel für die Abbildung von x1,…,xp auf y1,…,yq.
Man sieht: Einerseits werden hier die neurophysiologischen Vorgänge im Gehirn nachgeahmt, andererseits stellt ein solches künstliches neuronales Netz nur ein mathematisches Modell für eine Abbildung zwischen dem Satz der Eingabezahlen und dem Satz des Ausgabezahlen dar. Die Verarbeitung der Summe der Reize aus den Neuronen der unteren Schicht in einem Neuron bestimmt die Art der Abbildung, in einfachsten Fällen ist diese linear. Die Stärke der Verbindungen, die ja die Stärken der Synapsen simulieren, stehen für die Parameter, die die mathematische Abbildung auch noch bestimmen.
Hat man sich einmal für die Verarbeitung der Summe der Reize in einem Neuron entscheiden, sind es also die Parameter, gewissermaßen die Stärke der “Synapsen”, an denen man regulieren kann, was die so konstruierte Abbildung leisten kann. In der Regel sind es sehr viele solcher Stellschrauben, so dass man diese niemals “per Hand” oder durch reine Überlegung so einrichten kann, dass das gesamte künstliche neuronale Netz die gewünschte Abbildung leistet.
Hier kommt man nun zum Thema. Man lässt das neuronale Netz einfach lernen, man “trainiert” es mit einer Menge von Beispielen, d.h. man “zeigt” dem Netz immer wieder Beispiele, schaut nach, was es daraus “macht”, bewertet den Fehler, und ändert nach einer bestimmten Strategie die Synapsen, sprich Parameter. Und man macht das so lange, bis sich die Fehler bei den Beispielen in tolerablen Grenzen hält. Für das Funktionieren dieses Weges ist natürlich die Strategie für die Änderung der Synapsen bei dem Training entscheidend, also die Frage, wie man aus Fehlern lernt: Das kommt uns bekannt vor.
Mit künstlichen neuronalen Netzen kann man also Lernprozesse simulieren und nach einem erfolgreichen Training Aufgaben lösen, die wir früher nur Menschen mit hoher Intelligenz zugetraut haben. Und diese Netze können dieses sogar noch besser, wie auch die meisten Algorithmen, die in den Rechnern für uns Dienste tun. Wir staunen doch alle über die Schnelligkeit, mit der uns heute Suchmaschinen ihr Ergebnis präsentieren.
Man hat also hiermit eine Methode für ein “maschinelles Lernen” entwickelt. So kann man auch Lernprozesse in unserem Gehirn als Abarbeiten eines Algorithmus sehen und die Vorstellung von dem Wachsen bestimmter Synapsen beim Lernen findet sich auch in der Adaption der Parameter wieder. Damit kann natürlich nur ein Teil unserer Gehirntätigkeit nachgeahmt werden.
Solche künstlichen neuronalen Netze wurden in einfachster Form schon in den 40er Jahren des letzten Jahrhunderts vorgeschlagen und untersucht, in den 50er und 60 er Jahren gab es eine stürmische Entwicklung und schon erste kommerzielle Anwendungen. Nach einer Ernüchterung aufgrund vorerst unlösbarer Probleme Ende der 60er Jahre führten Weiterentwicklungen, insbesondere die Einführung von Nichtlinearitäten, zu einer neuerlichen Welle von Arbeiten auf diesem Gebiet und zu großen Hoffnungen für Anwendungen (siehe Wikipedia: Künstliches neuronales Netz). Ich kann mich noch entsinnen, dass man immer, wenn man vor einer Aufgabe stand, die nicht lösbar zu sein schien, seine Hoffnung auf neuronale Netze setzte, ob man diese nun kannte oder nicht. Heute stehen sie, neben anderen, für eine gut eingeführte und weit verbreitete Methode, die immer dann in Betracht gezogen werden sollte, wenn man eine nichtlineare mathematische Abbildung formulieren möchte, deren Parameter durch einen Satz von Daten (Beispielen) geschätzt werden sollen.
Bestärkendes Lernen (Reinforcement Learning)
Eine andere Form maschinellen Lernens geht noch einen Schritt weiter. Sie ist insbesondere für Roboter wichtig. Dieser ist ja nicht nur ein Rechner, er hat ja auch Sensoren, mit denen er etwas über die Umwelt erfährt und Motoren, mit denen er in der Umwelt Handlungen ausführen kann. Hier soll also nicht nur eine Tätigkeit eines menschlichen Gehirns nachgemacht werden, sondern die Tätigkeit eines ganzen Menschen in der Welt: Der Roboter soll sich in der Welt bewegen, sich ein Bild von seiner Umgebung machen und gewisse Handlungen ausführen – und er soll lernen, dieses so zu machen, wie es seiner “Bestimmung entspricht”. Was ist nun seine “Bestimmung” und wie bringt man das in das Verhalten des Roboters ein? Die erste Frage ist einfach zu beantworten, es gibt viele Aufgaben, bei denen ein Roboter den Menschen die Arbeit abnehmen kann, einfache Routinearbeiten oder gefahrvolle, und bei diesen sind auch schon viele Roboter im Einsatz (siehe Wikipedia: Roboter). Es gibt auch typisch menschliche Aufgaben wie z.B. Fußball spielen, die noch eine Herausforderung für solche künstlichen autonomen Systeme darstellen und an denen man die neuesten Algorithmen testen kann.
Ist eine Aufgabe definiert, muss man eine so genannte Belohnungsfunktion definieren, mit der man jede Aktion des Roboters bewerten kann. Dann stellt sich sein Verhalten während einer Folge von Zeitpunkten so dar: Er befindet sich zu Anfang in einem bestimmten Zustand, beobachtet seine Umgebung mit Hilfe seiner Sensoren, d.h. Daten seiner Sensoren werden registriert. Aufgrund dieser Information, seines momentanen Zustandes und im Hinblick auf die jeweilig zu erwartende Belohnung hat er sich dann für eine Aktion zu entscheiden. Es muss also eine wie auch immer geartete Strategie geben, nach der der Roboter entscheidet; diese kann von deterministischer Art sein, aber auch Zufallselemente enthalten. Nach der Aktion befindet sich der Roboter in der Regel in einem neuen Zustand, den er mit Hilfe eines Modells errechnet oder über seine Sensoren bestimmt. Die entsprechende Belohnung wird gespeichert. Im nächsten Zeitpunkt geschieht das gleiche: Registrierung der Umwelt, Entscheidung über eine Aktion gemäß einer Strategie, Erhalt einer Belohnung, Erreichen eines neuen Zustandes.
Bei gegebener Strategie durchläuft der Roboter also in Folge der Zeitpunkte verschiedenste Zustände und sammelt dabei eine Summe von Belohnungen auf. Eine solche Episode endet, wenn der Roboter sein Ziel erreicht hat. Auch der Fall, dass der Roboter nicht immer in endlicher Zeit sein Ziel erreicht, kann behandelt werden.
In einem einfachen Beispiel möge solch eine Episode konkretisiert werden: Ein Roboter soll in einem Raum auf kürzestem Wege von A nach B gelangen, der direkte Weg ist aber durch Hindernisse versperrt.
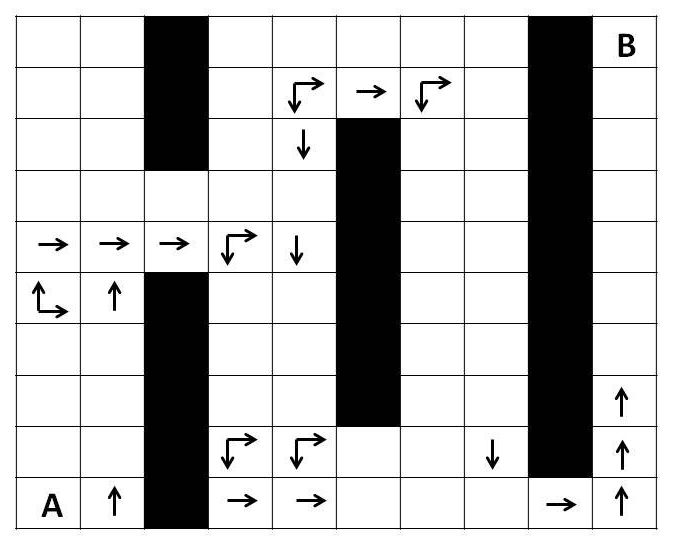
Abb.2: Suche nach einem Weg von A nach B um Hindernisse. Jede Aktion führe von einem Feld zu einem anderen; die optimalen Aktionen sind für einige Felder eingezeichnet.
Sein Zustand ist durch seine Position gegeben, in jedem Zeitpunkt habe er die Wahl, diesen durch einen Schritt in irgendeine von vier Richtungen zu verändern. Wie soll er sich in den verschiedenen Zuständen d.h. Positionen des Raumes entscheiden? Wir könnten das, da wir das ganze Problem überblicken und viel Erfahrung haben, sofort sagen. Beim Roboter müssen wir aber davon ausgehen, dass er nicht weiß, wo das Ziel sich befindet und auch nur registrieren kann, wo er sich befindet. Er muss erst in vielen Episoden Erfahrungen sammeln und dabei lernen, welche Richtungen für welche Positionen besonders günstig sind. Er muss also mit irgendeiner Strategie , d.h. einer Vorschrift, welche Aktion in einem jedem Zustand zu wählen ist, beginnen, diese in einer Episode testen, daraus Schlüsse ziehen für eine Verbesserung der Strategie und mit der neuen Strategie dann wieder testen und verbessern, bis praktisch keine Verbesserungen mehr eintreten.
Hier geht es also darum, ein Verhalten eines Roboters im Hinblick auf ein klar formuliertes Ziel zu optimieren. Wie so etwas konkret funktioniert, kann man nur in mathematischer Sprache formulieren, und auch wer mit dieser vertraut ist, braucht einige Zeit, um das zu verinnerlichen. Einen Punkt möchte ich aber erwähnen: Eine zentrale Rolle bei diesem Lernprozess spielt die so genannte action-value-Funktion. Diese stellt für jeden Zustand jeweils den Erwartungswert für die Gesamtbelohnung dar, wenn man in diesem Zustand aus jede mögliche Aktion wählt, dann aber der gerade aktuellen Strategie folgt.
Die Funktion misst also, wie “gut” es ist, in einem gegebenen Zustand eine bestimmte, aber beliebige Aktion zu wählen, unter der Prämisse, dass die momentane Strategie gilt. Somit kann man Strategien entdecken, die besser sein können als die gerade benutzte. Denn, wenn man findet, dass die Aktion, die im Rahmen der momentan geltenden Strategie in einem Zustand zu wählen ist, im Vergleich mit anderen dort möglichen Aktionen schlechter abschneidet, wird man die Strategie ändern und die neue Strategie so formulieren, dass so etwas nicht mehr passiert. Hat man schon die beste Strategie, kann so etwas natürlich nie passieren. Während der Episoden wachsen die Werte der action-value-Funktion für die Kombination von Zuständen und Aktionen natürlich um so stärker, je mehr sie bei Episoden mit günstiger Gesamtbelohnung beteiligt sind. Deshalb hat sich der Name “reinforcement learning” bzw. “bestärkendes Lernen” für diese Verfahren des maschinellen Lernens ergeben.
Viele und immer bessere Algorithmen für die Verbesserung von Strategien sind entwickelt worden, auch für allgemeinere Fälle, in denen man z.B. kein Modell von der Umwelt hat, sondern dieses erst bei den Episoden langsam aufbauen muss. Die Parallelen zu unserem “natürlichen” Lernprozess sind unübersehbar, aber nicht überraschend, denn natürlich wird man zunächst versuchen, uns bekannte Lernprozesse erst einmal nachzuahmen. Beeindruckend ist eher, wie weit man damit schon kommt.
Interessant ist ein “Nachmachen” natürlicher Prozesse mit Hilfe künstlicher Systeme immer, weil man dabei den Prozess selbst viel besser in der Hand hat. Man kann allerlei Aspekte modifizieren und dabei deren Rolle im gesamten Prozess besser verstehen. Zwei Aspekte haben mich dabei früher, als ich solche Verfahren studiert habe, besonders beeindruckt.
Einmal ist es die Art, wie man ein Ziel vorgeben muss. Der Roboter soll etwas nützliches tun, und das besonders “gut”. Danach muss man natürlich das Belohnungssystem ausrichten, und zwar so, dass sicher gestellt wird, dass das Ziel erreicht wird – mehr aber nicht. Das Anreizsystem soll ja dem Roboter möglichst viel Freiheit lassen, damit auch unvorhersehbare gute Lösungen entdeckt werden können. Das Belohnungssystem ist also entscheidend. Wer denkt nun nicht an Erziehungsratschläge, Lerntheorien und an die hohe Kunst, in einem Staat geeignete Rahmenbedingungen für bestimmte Ziele zu setzen?
Ein zweiter Aspekt hat mit einer Strategie zu tun, die in den Algorithmen eine bedeutende Rolle spielt; man nennt sie epsilon-greedy (greedy, engl. = gierig). Um sie zu verstehen, muss man erst einmal wissen, was eine “gierige” Strategie ist. Die ist uns bestens vertraut: Man wählt in jedem Zustand die Aktion, die momentan die größte Belohnung beschert, d.h. wir prüfen erst gar nicht, ob eine andere Aktion uns in Zukunft nicht noch zu einer höheren Belohnung verhilft. Nur in dem Falle, dass man die beste Strategie besitzt, ist das aber das beste Verhalten. Sonst aber ist es ratsam, gelegentlich seine Gier zu beherrschen und auch unkonventionellere Aktionen auszuprobieren. Nur so kann man zu besseren Lösungen kommen. Mit einer epsilon-gierigen Strategie macht man genau das: Mit einer kleinen Wahrscheinlichkeit epsilon stellt man alle möglichen Aktion gleichberechtigt zur Wahl, sonst wählt man diejenige Aktion, die man bisher als beste erkannt hat. Man hat also immer eine Balance zwischen der Haltung “So machen wir es immer, das hat sich bewährt” und dem Versuch “Probieren wir mal etwas anderes” zu finden. Zu Anfang, wenn man noch nicht viel Erfahrung hat, wird man das epsilon relativ groß wählen, d.h. häufiger andere Aktionen ausprobieren. Mit zunehmender Erfahrung wird man aber wohl immer weniger Ausnahmen von der Routine zulassen – in der Annahme, dass man schon nahe an der optimalen Lösung ist. Erinnert uns das nicht daran, dass man mit zunehmendem Alter konservativer wird?
Die Entwicklung auf dem Gebiet der “künstlichen autonomen Systeme” wird uns noch viele interessante Anwendungen und verblüffende Einsichten über unsere eigenen intelligenten Fähigkeiten liefern. Was aber auch hier wieder überdeutlich wird: Ohne Übung und Training, ohne Arbeit “an sich selbst” geht gar nichts. Lernen ist ein Wachstumsprozess, der Zeit braucht, aber mit der Zeit auch seine Früchte trägt.
siehe auch: Sutton, Richard S. und Andrew G. Barto: Reinforcement Learning – An Introduction
Dominanz der statischen Methoden
Nicht die oben erwähnten einfachen mathematischen Modelle, sondern statistische Verfahren dominieren heute Bereiche wie Maschinelles Übersetzen, natural language processing und auch Maschinelles Lernen, wo Bayesian Networks populär sind.
Ein wichtiger Grund scheinen die grossen Textcoropora und online verfügbaren Wissensarchive zu sein. Mit diesen Terabyte an bereits bestehendem, teilweise strukturierten, teilweise unstrukturierte Informationen füttert man dann die statistisch arbeitenden Systeme.
Statistische Methoden haben viel mehr Potential, als man gemeinhin denkt. Man kann sogar Sinnzusammenhänge damit erschliessen.
Arbeiten die Systeme allerdings nur mit statistischen Verfahren, so bedeutet das auch, dass sie kein tieferes Verständnis haben für das was sie machen.
Lesetipp
per Google ´Plappernder Roboter lernt sprechen´ finden Sie bei spektrum.de einen Artikel – in dem genau Ihre obigen theoretischen Überlegungen praktisch angewandt werden. Sogar mit bestärkendem Zuspruch
@KRichard / Hyperlink
Prima Hinweis. Einen URL kann man übrigens hier auch ganz einfach mit der Maus als Link reinkopieren:
http://www.spektrum.de/…r-lernt-sprechen/1154620
Dazu noch ein Link zum dem Open Access Paper, um das es dort geht:
Lyon C, Nehaniv CL, Saunders J (2012) Interactive Language Learning by Robots: The Transition from Babbling to Word Forms. PLoS ONE 7(6): e38236. doi:10.1371/journal.pone.0038236
Dominanz der statistischen Verfahren
Die Betonung liegt auf “heute”, es gibt auch wissenschaftliche Modeerscheinungen. Der rasche Aufstieg ist auch schon ein paar Jahre her, und die Verbindung zwischen dem physischen Aufbau von Gehirnen und der Natur der darin ablaufenden Berechnungen bleibt bei den statistischen Verfahren dunkel. Die Geschichte der KI ist voll von euphorischen Anfängen, die nach einigen Jahrzehnten zu einem dünnen Forschungsrinnsal verkümmern. Die KNN mögen vielleicht etwas aus der Mode gekommen sein, aber bis heute können wir keine guten Gehirne bauen, egal mit welchem Ansatz. Aus welcher Richtung kommt die nächste Welle? Wo sind die *neuen* Ideen?
“Maschinelles Lernen”
… entspricht ja nicht dem Lernen des Erkenntnissubjekts, auch weil das Lern- oder Belohnungsziel diesem in den allermeisten Fällen nicht klar vorgegeben ist.
MFG
Dr. Webbaer (der deshalb auch: ‘Die Entwicklung auf dem Gebiet der “künstlichen autonomen Systeme” wird uns noch viele interessante Anwendungen und verblüffende Einsichten über unsere eigenen intelligenten Fähigkeiten liefern.’ nur bedingt zustimmt)
Wir Schöpfung
470. Der Mensch hat sich nicht aus den Tieren entwickelte, aber das ist es, was diejenigen, die nicht an Gott glauben, euch glauben lassen wollen
Donnerstag, 21. Juni 2012, 17:30 Uhr
Meine innig geliebte Tochter, seit Anbeginn der Zeit und als die Welt von Meinem Ewigen Vater geschaffen wurde, hat es viel Verwirrung über den Ursprung der Menschheit gegeben.
Als Mein Vater die Welt schuf, damit Er eine Familie haben konnte, wurden viele Vorbereitungen getroffen.
Er schuf die Erde, die Meere, die Pflanzen, die Bäume, die Berge, die Flüsse, die Tiere — und dann, am zweitletzten Tag, als im Paradies alles vorhanden war, schuf Er den Menschen.
Der Mensch ist, obwohl er mit der Sünde beschmutzt ist, eine heilige Kreatur. Die Tiere sind da, um der Menschheit zu dienen.
Der Mensch hat sich nicht aus den Tieren entwickelte, aber das ist es, was diejenigen, die nicht an Gott glauben, euch glauben lassen wollen.
Evolutionstheorien, die behaupten, dass der Mensche von den Tieren abstammt, sind eine Lüge. Sie können niemals bewiesen werden.
Satan — ebenso wie seine gefallenen Engel und jeder Teufel, der vom Feind Gottes herstammt — hat den Menschen von dieser schrecklichen Lüge überzeugt.
Der Mensch ist ein Kind Gottes, aber um das menschliche Kind Gottes zu erniedrigen, will Satan in den Herzen der Menschheit Verwirrung stiften.
Warum fördert er diese Lüge durch falsche Lehren? Er kann so beweisen, dass sich der Mensch aus den Affen entwickelte, und sie anschließend davon überzeugen, dass sie nicht durch die Hand Meines Ewigen Vaters geschaffen wurden.
Das ist eine der größten Lügen, die vom Teufel hervorgebracht werden, wobei er die Seelen jener Menschen benutzt, die behaupten, dass sie intelligenter sind als der Rest ihrer Brüder und Schwestern.
Wissenschaftler erklären, dass sich der Mensch aus dem Tier entwickelte, aber sie werden getäuscht.
Die Wissenschaft ist fehlerhaft, wenn sie versucht, die Wahrheit über die Bildung des Weltalls zu erklären.
Kein Mensch versteht das Wunder der Göttlichen Schöpfung.
Wenn der Mensch glaubt, dass er alle Antworten über die Ursprünge der Menschheit weiß, und zwar aufgrund menschlicher Gedankengänge, dann täuscht er nicht nur andere arme Seelen, sondern er täuscht auch sich selbst.
Wenn in solchen Seelen, die an die Überlegenheit der menschlichen Intelligenz glauben, keine Liebe zu Gott-vorhanden ist, dann breitet sich der Atheismus wie ein Unkraut aus.
Dieses Unkraut, das in alle Richtungen wächst, verseucht und zerstört jedes Getreide in Sichtweite und ruft Krankheit hervor.
Das einzige Heilmittel ist, sich um göttliche Hilfe zu bemühen, durch demütiges Gebet, und darum zu bitten, dass die Wahrheit offenbart werden möge.
So viele Unwahrheiten, die von Atheisten — die versuchen zu beweisen, dass Gott nicht existiert — verbreitet werden, haben Millionen von Seelen zerstört. Ihre Opfer brauchen eure Gebete.
Atheismus ist die größte Religion in der Welt — und diejenigen, welche dieser Täuschung ihr Leben verschrieben haben, sind in Ewigkeit verloren.
Sie werden den Feuern der Hölle gegenüberstehen.
Wenn sie sich nicht zu Mir bekehren, während oder nach der „Warnung“, dann werden sie eine schreckliche Bestrafung erfahren.
Betet für sie.
Euer Jesus
Die Homepage http://www.diewarnung.net ist allemal lesenswert.
Hier spricht derjenige zu uns, der uns das Sprechen und Denken gab. Unser Schöpfer.