

Der Nutzen elektronischer Patientenakten
BLOG: Bierologie

Ob die Nazis, die Stasi oder doch die Résistance sich über Google Street View oder Facebook gefreut hätten? Wer weiß. Gegen das traditionelle Mantra des Datenschutzes stellt sich seit einigen Wochen die datenschutzkritische Spackeria (der Name nimmt eine Äußerung von Constanze Kurz – Sprecherin des Chaos Computer Club – auf den Arm. Sie bezeichnete jene, die ihrem Bild von Datenschutz nicht folgen, als „Post-Privacy-Spackos“). Wieso ein Schutz von privaten Daten, so sie erstmal im Internet sind, praktisch unmöglich ist, hatten wir hier schon mal am Beispiel des Fotodiensts Flickr gesehen. Aber anstatt auch hier nur auf die Risiken von elektronischen Daten einzugehen, möchte ich mal auf 2 schöne Beispiele für die Chancen eingehen. Nämlich darauf, was man praktisches mit elektronischen Patientenakten anstellen kann.
Bei ScienceLife bin ich auf das „NorthShore University Health System“ gestossen. Die Einrichtung führt ihre Patientenakten nun seit fast 8 Jahren in elektronischer Form und pfiffige Leute haben praktische Wege gefunden, wie man diese Daten zum Wohl der Patienten remixen kann.
Das erste Beispiel ist eine Übersicht über die Körpertemperatur von Patienten nach Operationen. Der Begriff Fieber wurde von Carl Reinhold August Wunderlich im Jahr 1871 eingeführt. Dazu hat Wunderlich die Temperatur von um die 25000 Menschen gemessen und daraus dann die Eckpunkte für Normaltemperatur und Fieber definiert. Seitdem wurde allerdings erstaunlich wenig an der Definition gerüttelt. Dabei wäre es durchaus spannend, zu wissen, welche Körpertemperaturen nach einer OP normal sind und welche vielleicht Anlass zur Sorge sein könnten.
Und genau das hat man mit den Daten aus NorthShore jetzt gemacht. Die elektronisch vorliegenden Temperaturmessungen hat man ausgewertet und daraus Kurven zur Temperaturverteilung, bei den bereits bekannten Patienten, erstellt. Damit kann ein Arzt dann schauen ob sein aktueller Patient eine höhere oder niedrigere Temperatur hat, als der Grossteil der früheren Patienten. Und da ja genug Daten vorhanden sind, kann man das sogar noch schön Aufteilen. Die Kurven werden nach Art der OP, Anzahl der Tage die seit der OP vergangen sind, Alter des Patientens und (je nach Art der OP) eventuell sogar nach Geschlecht getrennt erzeugt. Das so entstandene Tool — Project Wunderlich getauft — findet man online und steht so weltweit jedem Arzt mit einem Zugang zum Internet zur Verfügung.
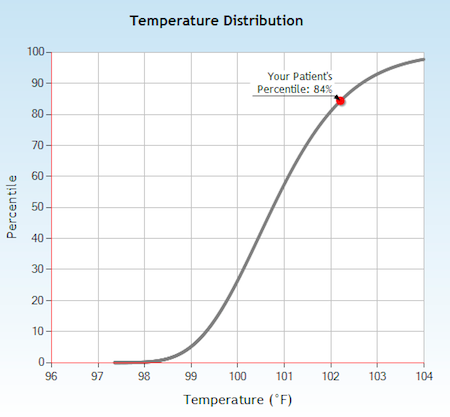
Darüber hinaus lernt das System mit der Zeit sogar dazu, bzw. seine Kurven werden besser: Jede Nacht werden die neusten Patientendaten in das System eingepflegt, die Kurven besser (Also ähnlich wie ein SPAM-Filter, der mit jeder empfangenen und kategorisierten Mail dazulernt). Das ist schon ein ziemlich cooles Projekt, was man aus solchen Daten umgesetzt hat. Und wer weiß: Vielleicht nutzen ja bald auch andere Krankenhäuser solche Methoden. Oder vernetzen sich gleich, um eine größere Datenbasis zu schaffen.
Das andere, bemerkenswerte, Projekt wurde ebenfalls mit NorthShore-Daten umgesetzt: Das Erkennen von MRSA-Patienten. MRSA steht für “methicillin-resistant Staphylococcus aureus” und so bezeichnet man eine Bakterienart die auf dieses Antibiotikum nicht mehr anspricht. Das ist nicht nur für davon betroffene Patienten problematisch, sondern vor allem für Krankenhäuser wo sich auf recht engem Raum viele Menschen, viele davon bereits gesundheitlich angeschlagen, befinden. Dementsprechend ist es für Krankenhäuser wichtig, dass betroffene Patienten frühzeitig erkannt und gegebenenfalls isoliert werden können. Denn so kann man die anderen Patienten ganz gut schützen.
Leider ist der Nachweis von MRSA-Infizierten Patienten nicht nur relativ aufwändig (Der Nachweis erfolgt in der Regel wohl per PCR) sondern auch vergleichsweise teuer. Mal abgesehen davon, dass falsch-positive Ergebnisse (Der Test sagt, dass der Patient von MRSA infiziert ist, obwohl dem nicht so ist) dazu führen, dass die falschen Patienten isoliert werden. In Zeiten von geringem Budget und geringer Personaldecke sind Krankenhäuser also interessiert daran Risikogruppen für MRSA-Infektionen zu erkennen. Damit kann man die Anzahl der Tests so gering wie möglich und die Gesundheit der Patienten gleichzeitig hoch halten. Mit Hilfe der elektronischen Patientenakte hat man bei NorthShore so ein „Frühwarnsystem” entwickelt. Das NorthShore University Health System betreibt insgesamt 4 Krankenhäuser in Chicago und in einem der Krankenhäuser hat man die Daten von, auf MRSA positiv bzw. negativ getesteten, Patienten genommen um daraus Modelle zur Vorhersage des MRSA-Risikos geschaffen.
In der Patientenakte wurde neben demographischen Eckdaten wie das Alter auch die vorherige Krankengeschichte betrachtet: Wie oft war ein Patient zuvor im Krankenhaus? Musste er in die Notaufnahme eingeliefert werden? An welchen Krankheiten leidet er akut? Ausserdem wurden die Laborwerte, die am ersten Tag der Einlieferung ins Krankenhaus gewonnen wurden, ebenfalls in die Analyse mit einbezogen.
Aus all diesen Parametern, genommen von Patienten aus dem einen Krankenhaus, wurden dann statistische Modelle zur Vorhersage des MRSA-Risikos für Patienten entwickelt. Getestet wurden diese Modelle mit Patienten aus 2 anderen Krankenhäusern des NorthShore University Health Systems. Und die Ergebnisse sind recht vielversprechend: Mit ihren Modellen können sie, wenn sie nur jene 30 % der Patienten, die das höchste Risiko haben, testen bereits 60 % der MRSA-Infektionen identifizieren. Das klingt jetzt vielleicht nicht so richtig beeindruckend. Dabei sollte man aber im Auge behalten: Nur 4 % der Patienten die ins Krankenhaus kommen, sind überhaupt von einer MRSA-Infektion betroffen. Gleichzeitig konnten sie 40 % der Patienten identifizieren, die ein Infektionsrisiko von 2 % oder weniger haben. Damit liessen sich die Kosten im Zusammenhang mit MRSA-Infektionen bereits halbieren.
Dabei haben diese Modelle sicherlich noch Luft nach oben. Denn zugunsten der Verständlichkeit haben sie sich, so weit ich das verstanden habe, auf vergleichsweise einfache Modellierungen beschränkt. Ich fände es ja ganz spannend, wenn man bei diesen Modellierungen genauso mit Bayes arbeiten würde, wie im SPAM-Filter-Beispiel: Jeder neue Patient ist ein neuer Datenpunkt und die Ergebnisse seiner Kategorisierung und eventueller Falsch-Identifizierung könnten dann dazu genutzt werden, um die Modelle weiter zu optimieren. In wie weit man die Kontrolle über seine Modelle in so einem sensiblen Bereich an Algorithmen abgeben möchte (ich glaube, dass passende Algorithmen die lernfähig sind, starren Modellen überlegen wären, aber die Angst davor solche Diagnosen an Maschinen abzugeben muss man berücksichtigen) ist sicherlich von vielen Faktoren abhängig.
Was man an diesen beiden Beispielen aber auf jeden Fall sehen kann ist die Tatsache, dass eine ausführliche Erhebung von Daten eben nicht nur (Missbrauchs-)Risiken mit sich bringt, sondern auch Chancen im (klinischen) Alltag hat. Wer jetzt einwenden will, dass die Daten dort anonymisiert verarbeitet werden und das ja keine personenbezogenen Daten seien: Zum einen sollte man aus der Fülle der Parameter gute Profile der einzelnen Patienten errechnen können (immerhin basiert das MRSA-System genau darauf). Und zum anderen müssen von jedem Patienten all diese Daten erhoben werden, damit es funktionieren kann.
Anstatt immer nur über Risiken zu reden sollten wir auch über die Chancen, die sich so ergeben, nachdenken. Das NorthShore University Health System hat dabei schon mal einen Anfang gemacht.
Robicsek A, Beaumont JL, Wright MO, Thomson RB Jr, Kaul KL, & Peterson LR (2011). Electronic prediction rules for methicillin-resistant Staphylococcus aureus colonization. Infection control and hospital epidemiology : the official journal of the Society of Hospital Epidemiologists of America, 32 (1), 9-19 PMID: 21121818
![]()
Widerlich
Menschenrechte verachtend!!!!!! Eklig!!!!!!! So was von widerlich!!!!! Ich kotz ab!!!!!!
@0815: Dein Einwand ist mir zu kurz – warum Menschenrechte verachtend?
Aber “ich kotz ab” klau ich mir, den Satz find ich gut!
lokale vs. globale Verfügbarkeit
Hier werden zwei Sachen zusammengeworfen, die streng getrennt gehören. Natürlich ist es fein, die gesamte Krankengeschichte eines Patienten als Datensatz für die Behandlung dieses selben Patienten zur Verfügung zu haben. Für Expertensysteme ist es sogar DIE Voraussetzung. Garbage in, garbage out, sage ich nur.
Und natürlich ist es nützlich, mit vorhandenen Patientendaten retrospektive Studien durchführen zu können. Zwei caveats: informed consent (ist manchmal nach Jahren gar nicht so einfach zu erhalten, sollte aber unbedingte Voraussetzung sein). Dazu kommen noch alle statistisch begründeten Zweifel an der Aussagekraft retrospektiver Studien. Ist halt nicht die höchst Evidenzstufe.
Von diesen legitimen (bzw. legitimierten) Verwendungsweisen von Patientendaten sollte man alle Denkmodelle unterscheiden, die auf eine zentrale Serverlösung hinauslaufen, so wie es für die eCard im deutschen Gesundheitswesen ab 01.10.11 geplant ist. Das ist, mit Verlaub gesagt, total bescheuert. Mit Opt-in (na immerhin!) seinen Versicherungsstatus und, wenn gewünscht, seine wichtigsten Gesundheits- und Behandlungsdaten auf einem zentralen Server speichern zu lassen, macht doch diesen Server nur um so attraktiver für den nächsten sozial inkompetenten, pickeligen, 14-jährigen Cracker , der das Ding aus dem Jugendzimmer bei seinen lieben Eltern heraus angreift. Komme selbst in Versuchung, es als proof-of-concept zu tun …
LifeType hat gerade meinen Kommentar gefressen. Aber darunter sollst du bei der Antwort nicht leiden, ich versuch es noch mal halbwegs ausführlich zu beantworten. 🙂
1. Bei dem informed consent stimme ich dir zu, das ist wünschenswert. Allerdings sehe ich da das Problem, dass solche medizinischen Anwendungen wie die beiden Applikationen aus dem Blogpost nur funktionieren können, wenn genug Leute ihre Daten bereitstellen. (Aus wissenschaftlicher Sicht wäre es sicherlich auch spannend, ob die Leute, die sich für/gegen eine solche Datenweitergabe entscheiden clustern. Also ähnliche Krankheitsbilder etc. zeigen?)
Zur Statistischen Aussagekraft: Ich würde auch hier den Vergleich der SPAM-Filter für angemessen halten. Man trainiert die Filter erstmal mit einem bekannten Datensatz. Und dann erprobt man die Effizienz (und verbessert gleichzeitig) an echten Daten. Das dürfte auch die effizienteste Methode für die Probleme sein, die hier im Blogbeitrag angeklungen sind.
Zur eCard: Ich finde das, aus Patientensicht, total prima, wenn meine Krankendaten für jeden Arzt, der mich behandeln muss, verfügbar sind. Gerade in der Notfallmedizin ist so etwas doch ein entscheidender Vorteil. Die Urban Legend, dass Ärzte sowieso eine solche Sauklaue haben, dass ihre handschriftlichen Anweisungen niemand lesen kann mal aussen vor (http://noustuff.wordpress.com/…-bad-handwriting/). Ob man das auf einem zentralen Server haben will? Puh, was ist die alternative? Pro Krankenversicherung? Eigenes Hosting durch den Patienten? Hast du einen Vorschlag, wie man diese “elektronische Krankenakte, für Ärzte zugänglich” umsetzen könnte?