

Wie man Jungwissenschaftler zu Fehlverhalten motiviert
BLOG: Detritus

Als Doktorand ist man nicht frei von Interessenskonflikten – ganz im Gegenteil. Es ist der Regelfall, dass Experimente nicht funktionieren, oder die gewünschten Ergebnisse ausbleiben, obwohl man technisch einwandfrei gearbeitet hat. Es ist ja das Wesen der Wissenschaft, dass man nie genau weiß, was dabei herauskommt.

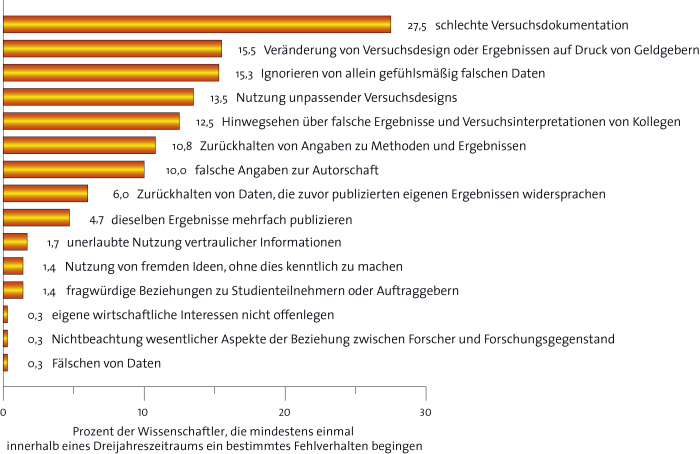
An den Früchten der eigenen Arbeit wird man später gemessen, und das ist auch gut so. Um die Karriere zu beschleunigen, kann es dabei sehr attraktiv sein, auf unlautere Mittel zurück zu greifen. Das kann bewusstes Schönrechnen oder Ideenklau sein, oder ganz unbewusst passieren, weil man ein bestimmtes Ergebnis erwartet und eben keine neutrale BeobachterIn ist. So ist beispielsweise das „Ignorieren von allein gefühlsmäßig falschen Daten“ offenkundig ein recht verbreitetes Phänomen. Wer hat nicht schon mal den Drang verspürt „Ausreißer“ einfach so aus der Datenreihe zu werfen?
{kind=link}
Retractions & Fälschungen
Aber es kommt nicht von ungefähr, dass in letzter Zeit die Rate der offiziell zurückgezogenen Veröffentlichungen so enorm in die Höhe geschnellt ist. Laut Nature wurden im vergangenen Jahrzehnt zehnmal so viele Arbeiten aufgrund von Fehlverhalten zurückgezogen, als noch in den neunziger Jahren. Im gleichen Zeitraum wuchs der wissenschaftliche Output nur um die Hälfte.

In grün: Zeitverlauf des globalen Publikationsvolumens, in blau: die Zahl der zurückgezogenen Artikel, normiert auf je 100.000 publizierte Artikel. Die Rate der Retractions wächst schneller als die Publikationen selbst, das heißt der Prozentsatz der fehlerhaften Artikel am Gesamtkorpus wächst. 2013 ist noch nicht komplett, deshalb fällt es etwas aus der Reihe. (Grafik von pmretract.heroku.com, bezieht sich auf Daten aus der biomedizinischen Datenbank PubMed)
Schwer vorstellbar, dass man das lediglich durch die Effizienz des Internets bei der Fehlersuche wegerklären kann. Der Zeitverlauf zeigt die deutlichste Zunahme ab Mitte der Nullerjahre – wo elektronische Publikationen und Internet-basierte Literaturrecherche in den Naturwissenschaft schon längst Standard waren. Könnten nicht noch andere strukturelle Veränderungen in der Wissenschaft dafür verantwortlich sein?
Die Gründe
Zu den Motivatoren für Fehlverhalten unter DoktorandInnen und Postdocs zählt sicher der relativ hohe Leidensdruck, den man für eine erfolgreiche wissenschaftliche Karriere in Kauf nehmen muss: unsichere Perspektiven, generelle Familienunfreundlichkeit, prekäre Beschäftigungsverhältnisse, Unterbezahlung und das ständige Umziehen von Land zu Land – das alles über viele Jahre hinweg. Die meisten werden den Lohn für diese Entbehrungen nicht auf’s Spiel setzen, aber es soll ja Menschen geben, die nicht so hart im Nehmen sind. Wer weiß, ob dann nicht ein entscheidender Durchbruch kurzzeitige Erleichterung verschaffen kann? Natürlich ist die bewusste Entscheidung, Daten zu fälschen, einfach dumm. Wissenschaft ist langfristig selbstkorrigierend, und früher oder später kommt alles ans Licht (sofern sich jemand dafür interessiert).
Diese Situation hat sich durch eine immens gesteigerte Konkurrenz weiter verschärft. Schwellenländer wie China, Indien und Brasilien haben ihre Forschungssektoren ausgebaut und global gesehen hat sich der wissenschaftliche Output massiv gesteigert – wie man auch an der obigen Grafik ablesen kann. Davon unabhängig gibt es eine regelrechte Doktorandenschwemme. Immer mehr Leute promovieren. Als wenn das nicht alles schon schlimm genug wäre, werden in den Zeiten der Finanzkrise auch Forschungsbudgets immer knapper, und damit auch die verfügbaren Stellen.
Wie stark sich diese Prozesse im Detail auswirken, kann ich nicht sagen, aber die Konkurrenz um Fördergelder und Stellen ist über die letzten Jahre fraglos stärker geworden, ebenso wie um die Plätze in den begehrten Zeitschriften, die als „Türöffner“ für die eigene Karriere dienen. Und da liegt ein nicht zu kleiner Hase im Pfeffer.
„I want good data, a paper in CELL, but I got a project straight from Hell“ – sangen die Alzheimer-ForscherInnen des Zheng Labs vor mehr als zwei Jahren. (Youtube)
Bestimmte Publikationen dienen als Türöffner
Wenn es nämlich darum geht, andere ForscherInnen einzustellen, Förderanträge zu bewerten oder wissenschaftliche Leistungsfähigkeit einzuschätzen, stützen sich viele auf den Journal-Impact-Factor. Diese ungelenk als „Zeitschriften-Durchschlagskraft-Faktor“ übersetzbare Zahl spiegelt eine gewisse Hierarchie unter den Zeitschriften wieder – Cell, Nature und Science mit ihren hohen zweistelligen Faktoren gehören zu den begehrtesten Zeitschriften, in denen auch die ProtagonistInnen des obigen Videos gerne Ergebnisse unterbringen wollen. Tausende andere Journals mit einstelligen JIFs sind weit weniger begehrt. Die Bewertungslogik anhand des JIF folgt einem „je höher die Durchschlagskraft der Zeitschrift, in der die Publikation erschien, desto besser die Publikation, die ForscherIn und damit auch deren Arbeit“. Und je besser das Journal ist, in dem man publiziert, desto besser ist die ForscherIn – logisch, oder?
Der Haken ist jedoch, dass die Journal-Hierarchie eher kollektiv „gefühlt“ wird und für die Bewertung von Einzelarbeiten und Personen nicht taugt. Der JIF war seit seiner Erfindung in den siebziger Jahren lediglich ein grobes Werkzeug der Bibliotheken, und wurde nie für die Bewertung von Einzelpublikationen oder sogar Personen konzipiert. Wie Prof. Björn Brembs hier detalliert erklärt, kann der JIF nicht die Zahl der Zitierungen für ein bestimmtes Paper vorhersagen, er ist kein gutes Maß für die „Wichtigkeit“ oder den „Neuigkeitswert“. Die Qualität der Daten ist in Zeitschriften mit hohem JIF nicht besser, als anderswo. Nach allem, was man heute weiß, korreliert der JIF nur mit der Rate der Retraktionen nennenswert, und zwar ganz hervorragend.

Der Impact Factor sagt vor allem eines voraus: Wie hoch die Rate der zurückgezogenen Artikel ist, in denen sie erschienen sind. (Grafik aus diesem Paper)
Das ist eigentlich nicht überraschend, denn die begehrten Journals publizieren in erster Linie das, was die EditorInnen als besonders spektakulär und revolutionär ansehen. Leider haben spektakuläre und revolutionäre Ergebnisse die Angewohnheit, öfters falsch-positiv zu sein. Das heißt, man hat durch Zufall einen Effekt dokumentiert, der bei genauerem Hinsehen verschwindet. Weil er ein Artefakt ist, oder eine statistische Anomalie. Nicht ohne Grund lehnte einer meiner Ex-Chefs das Publizieren und Lesen von Nature und Science kategorisch ab und verglich sie mit der Bild-Zeitung.
Dazu kommt natürlich, dass niemand genau weiß, wie der JIF überhaupt errechnet wird. Das Prinzip ist natürlich bekannt – die Zahl der Zitierungen, geteilt durch die Zahl der zitierbaren Artikel über einen Zeitraum von zwei Jahren – aber die Privatfirma Thomson Reuters rechnet ihn völlig intransparent basierend auf einer unklaren Datenbasis aus, und man kann sogar über die Höhe des JIF verhandeln. Was nämlich einen „zitierbarer Artikel“ darstellt, ist alles andere, als vorbestimmt.
Wenn man das als Außernstehender liest, wird man vermutlich angesichts der Defizite und der gleichzeitigen Popularität des JIF die Hände über dem Kopf zusammenschlagen. Die meisten dieser Probleme sind vermutlich in den Wissenschaftlerkreisen hinreichend lange bekannt. Das hält aber WissenschafterInnen nicht davon ab, ihn genauso dafür zu benutzen – und das auch ganz offen zuzugeben. So wäre eben das System, und wie könnte man schon etwas daran ändern? Diese Praxis ist immens weit verbreitet, bis in die höheren Ränge des Wissenschaftsbetriebs.
Fakt ist: die Zahl der High-Impact-Papers auf dem Lebenslauf einer WissenschaftlerIn spiegelt vor allem deren sozialen Status wider. Eine oder mehrere spektakuläre Nature-Publikationen ist für die Bewerbung um Stellen oder Gelder oft ausschlaggebend, und zwar auf allen Hierarchieebenen.
Fazit
Das zunehmende Fehlverhalten ist natürlich kein ausschließliches Phänomen unter jungen WissenschaftlerInnen, und auch der zunehmende Missbrauch des Journal Impact Factor ist wahrscheinlich keine ausschließliche Erklärung dafür. Allerdings stehen junge ForscherInnen unter zunehmendem Druck, möglichst positives und spektakuläres Material zu produzieren. Die Zeiten haben sich geändert, man bekommt heute nicht mehr so schnell ein Paper in Cell unter, wie vielleicht Anfang der neunziger Jahre. Das taugt immerhin als Teilerklärung für die „unzulässigen Abkürzungen“.
Ein Weg, wie man dieser Entwicklung entgegentreten kann, ist Chefs und Vorgesetzte auf das Thema anzusprechen, und anzuregen, die San Francisco DORA Declaration on Research Assessment zu unterzeichnen, die sich genau gegen diese Bewertungs-Praxis ausspricht. Denn auch wenn wir das System nicht von heute auf morgen revolutionieren werden, ist es wichtig, gerade die entscheidenden Leute, die von JIF-Publikationen profitieren, über dessen Defizite in Kenntnis zu setzen. Auf zu viel positives Feedback sollte man sich allerdings nicht einstellen.
![]()
Hinweis (hinzugefügt am 25.06.): An einer Genderdebatte habe ich kein Interesse, aber ich finde es nicht schlimm, wenn man die unterrepräsentierten weiblichen Forscher explizit mit in die Betrachtung einbezieht.
AnregerInnen
Martin Ballaschk schrieb (24. Juni 2013, 18:00):
> Wer hat nicht schon mal den Drang verspürt „Ausreißer“ einfach so aus der Datenreihe zu werfen?
Wer hätte nicht schon einmal daran gedacht, “AusreißerInnen” mit der (guten?) Begründung aus einer Datenreihe zu werfen, dass ihnen der Rest der Datenreihe “kollektiv „gefühlt”” entgegentritt ?
p.s.
In der ersten Abbildung (“In grün: Zeitverlauf des globalen Publikationsvolumens, in blau: die Zahl der zurückgezogenen Artikel, normiert auf je 100.000 publizierte Artikel. […]“) missfällt mir der Ausreißer “grün 2013”; besonders, weil sich “blau 2013” deshalb auch “nach Ausreißer anfühlt”, auch wenn das bei sorgfältiger Betrachtung wohl keiner ist. Könnte jemand das grüne Histogramm bitte zumindest vergleichsweise schön(er)rechnen (d.h. die “Publikationen 2013” auf die Erwartung für ein volles Jahr normalisieren)?
@Frank
Du kannst natürlich nicht wissen, was ich in Hinsicht auf “Kurvenverläufe begradigen” schon gesehen habe. Wenn man Ausreißer als solche identifiziert und erklären kann, ist das sicher kein Problem. Die Betonung liegt auf „einfach so“.
Wegen der Grafik: ich hatte einfach keine Zeit, die hübscher zu machen.
Begründung
Gibt es denn eine gute Begründung, Ausreißer aus einer Datenreihe zu entfernen. Wohlgemerkt: Die Frage ist nicht, ob während der Datennahme ein Fehler passieren kann, der den einen Wert, der gerade gemessen wird, unbrauchbar macht. Dieses Ereignis kann man dann markieren und den entsprechenden Wert aus der Datenreihe entfernen oder besonders markieren. Aber einen Wert herauszunehmen, weil es ein Ausreißer ist, geht unter keinen Umständen. Schon weil es modellabhängig ist, ob ein Wert aus Susreißer zu betrachten ist.
@Joachim
Danke für die Klarstellung des Unterschied zwischen Fehlern und Ausreißern. Ich finde auch, “echte Ausreißer” dürfen nicht entfernt werden, erklärbare Messfehler schon.
Beispielsweise nahm ich kürzlich Messreihen auf (NMR / Spinrelaxation) und der erste Punkt wich immer von dem erwarteten monoexponentiellen Verlauf ab. Jetzt stellte sich heraus, dass die Messungen sich gegenseitig über die Temperatur beeinflussen und der erste Wert bei einer viel niedrigeren Tempereratur aufgenommen wurde, als alle anderen. Den Wert könnte man dann sicher ruhigen Gewissens verwerfen, allerdings nehme ich die Messreihen jetzt nochmal auf, mit hoffentlich konstanter Temperatur.
Sind nicht auch Messfehler wichtiger Bestandteil von wissenschaftlicher Erkenntnis und Gewinn aus der Arbeit?
Müssten diese nicht sinnvollerweise also erhalten bleiben? Damit … wie es derzeit so schön üblich ist, die Fehlerkultur; das lernen aus Fehlern erst ermöglicht wird? Fehler (anderer) haben auch so ein perfektes Imaginationspotential, das zur Visoalisierung enorm beitragen kann.
Das Entfernen von Fehlwerten eine scheinheilige und unfaire Angelegenheit sei, weil der Fehler machende durchaus seinen Vorteil daran hatte, aber niemand weiteres…
Auch Fehlwerte sind Daten im Zusammenhang mit der Erklärung des Wertes im Kontrast zur erwarteten “Kurve”.
Im Regen nass zu werden ist ein Beweis (mehr) dafür, dass man auch tatsächlich im Regen stand.
Beweis:
Wenn ich Visoalisierung mit “o” schreibe, stehe ich da, wie ein Depp im Regen. In diesem Sinne wird demnächst niemand mehr dieses Wort falsch schreiben, der sich diesem Fehler bewusst wurde und sich fremdschämte und, Spaß muß sein: Den Verursacher des Fehlers ein wenig verhöhnte.
@chris: Auf den Fehler kommt es an
Es kommt meines Erachtens ein bisschen darauf an, was der Fehler ist. Wenn ich eine Reihe von Messwerten aufnehme und bei einem von ihnen fällt mittendrin ein Netzgerät aus, dann kann ich die Aufnahme dieses Wertes wiederholen oder ihn in der Datenreihe einfach weglassen. Aus dem Hinweis, dass Netzteile ausfallen können und das dadurch ein verzehrter Messwert herauskommt, lernt niemand etwas.
Bei Martins Beispiel würde ich dagegen den Messwert mit der falschen Temperatur drinlassen und nur beim Anfitten der Kurve nicht berücksichtigen. Das wirft natürlich gleich die Frage auf, ob die Temperatur denn auch die anderen Werte, vielleicht im geringeren Maße beeinflusst hat. Hier gibt es also einen echten Mehrwert, weil eine Einflussgröße sichtbar wird, die systematisch mit der Messung zusammenhängt. Nicht einfach ein Gerätefehler.
@Chris
Vielleicht, wenn es etwas neues gewesen wäre. Aber wenn man einfach zu dämlich war, eine Standardmethode korrekt durchzuführen, muss man das nicht extra öffentlich machen.
Aber natürlich sehe ich das auch als Problem: Über die ganzen Fallstricke und Fehlerquellen, die einem die Zeit rauben , schreibt natürlich keiner. Wenn man etwas für das eigene Labor aus der Literatur heraus neu etablieren muss, lernt man diese auf die harte Tour kennen. Produktiver ist es, wenn man sich die Methode von einer erfahrenen Person beibringen lässt – und das geschieht dann völlig außerhalb des öffentlichen Diskurses.
@Joachim
Die Diskussion über die Temperaturen hat vielleicht wirklich einen echten Mehrwert. Die anderen Messwerte beeinflussen sich nämlich wirklich gegenseitig und es gibt verschiedene Strategien, damit umzugehen. Dazu kommt, dass niemand die “Wahrheit” kennt und die konkurrierenden Strategien leicht unterschiedliche Ergebnisse liefern.
Für meine Analysen ist es erst einmal ohne Bedeutung, ob ich den Punkt einfach rauslasse oder ihn einfach nicht anfitte. Ich finde es aber besser, das Experiment “korrekt” zu wiederholen.
Lasst alle Hoffnung fahren …
Martin B. schrieb (25.06.2013, 13:41):
> […] Die anderen Messwerte beeinflussen sich nämlich wirklich gegenseitig
Heißt das (etwa, eher):
über verschiedene Messreihen (jede jeweils eine Serie von verschiedenen, wiedererkennbaren Einzelversuchen) sind die entsprechend erhaltenen Messwerte z.B. mit der Reihenfolge der Einzelversuche korreliert, und/oder mit der Dauer vom Ende des einen Einzelversuchs bis zum Anfang des nächsten?
> Dazu kommt, dass niemand die “Wahrheit” kennt
Immerhin sollten die Beobachtungsdaten (einschl. Indentifizierung der verschiedenen/unterscheidbaren Einzelversuche bzw. der ganzen Messreihen) bekannt sein, die Operation(en), wie daraus jeweils ein (reeller, kommensurabler) Messwert zu gewinnen wäre, sowie diese entsprechenden Messwerte an sich.
Noch mehr “Wahrheit” zu unterstellen, grenzt sicher an Fehlverhalten.
> Ich finde es aber besser, das Experiment “korrekt” zu wiederholen.
Ja, immer schön die Anführungszeichen um indefinite (aber formal unterscheidbare) Begriffe drumherum schreiben — soviel Zeit muss sein!
seufz
@Frank Wappler
Ja.
Auch.
Bevor es noch mehr Verwirrung gibt, beschreibe ich kurz das Experiment: Es sollen Spinrelaxationsdaten von den Amid-Stickstoffen des Proteinbackbones gewonnen werden, bei denen man Magnetisierung auf den 15N-Spin überträgt, sie während einer Wartezeit eine Weile relaxieren lässt und dann die Restmagnetisierung bestimmt. Man inkrementiert die Wartezeit und erhält dabei einen exponentiellen Abfall der Restmagnetisierung. Dabei tauchen zwei Probleme auf: erstens heizt die Pulssequenz selbst die Probe auf, was die Relaxation beeinflusst und die unterschiedlichen Wartezeiten lassen die Probe unterschiedlich viel Zeit zum Wiederabkühlen. Zweitens, ist NMR inhärent insensitiv, man wiederholt also und hat Messzeiten von einigen Stunden oder Tagen. Um Tagesschwankungen und Veränderungen innerhalb der Probe (Veränderung des Redoxstatus, pH, Aggregation) auszumitteln, nimmt man die Einzelmessungen verschachtelt auf. Dabei hat man grundsätzlich die Wahl zwischen einfachem „interleaved“ (alle Scans eines Datenpunkts werden mit einem Mal durchgeführt) und „single-scan interleaved“ (alle Delays werden mit einem Scans durchgeführt), die sich nur in der Reihenfolge der Aufnahme der Einzeldatenpunkte unterscheiden. Zusätzlich kann man eine Temperaturkompensation einbauen, die sicherstellen soll, dass für jede Messung exakt die gleiche Menge Energie in die Probe eingetragen wird.
Leider habe ich keine Möglichkeit, die Wartezeiten untereinander zu randomisieren. So schlägt sich der Wärmeverlust der vorhergehenden Messung stets in der nachfolgenden Messung nieder. Das bemerkt man aber ausschließlich in den single-scan interleaved Experimenten (weil hier stets die gleiche Reihenfolge der Delays abgeschritten wird), weshalb ich jetzt einfach-interleaved mit einer Temperaturkompensierung nutze. Damit habe ich zwar eine höhere, aber besser definierte Temperatur in der Probe.
Ich meinte, dass es schwierig ist, die Temperatur innerhalb eines NMR-Röhrchens zu bestimmen. Temperatursensoren außerhalb der Probe können den Energieeintrag durch die Pulssequenz selbst nicht wahrnehmen, da sie unterhalb der Probe im Heiz/Kühl-Gasstrom sitzen. Da wir Feldhomogenität innerhalb der Probe brauchen, können wir auch nicht eben einen Messfühler in die Lösung hängen. Allerdings kann man den Wärmeeintrag mit externen chemischen Standards recht gut bestimmen, allerdings muss man diese auf die wahre Temperatur kalibrieren. Für die Temperaturkontrolle via interner chemischer Standards gibt es seit kurzem die Technik, allerdings besitzt unser Institut diese nicht.
Schlechte Laune? Kann ich irgendetwas tun, dass es dir besser geht?
Ich befürchte, das sich das Gehampel um hochrangige Journals nicht verbessern wird, solange solche Artikel im Lebenslauf die Chancen erheblich verbessern.
Bezüglich der Meßwerte: Man kann schon Meßwerte rausnehmen, aber das sollte man mit “Outlier-Tests” überprüfen. Wir machen das regelmässig mit qPCR und anderen Meßwerten. Da führen wir einzelne Messungen mindestens in dreifacher (häufig sogar sechsfacher) Wiederholung aus und machen über die Ergebnisse Statistik. Wenn da das Ergebnis ist, das das ein “Ausreißer” ist, fliegt der Wert raus. Wenn nicht, bleibt er drin, auch wenn er noch so unschön ist. Häufig ist es dann so, das bei relativ homogenen Werten der Ausreißer der Wert ist, bei dem man einen Fehler beim pipettieren gemacht hat.
Don’t know much about Stat_Mech …
Martin B. schrieb (25.06.2013, 16:06):
> […] erstens heizt die Pulssequenz selbst die Probe auf
> […] Zweitens […] man wiederholt also und […] nimmt man die Einzelmessungen verschachtelt auf.
Super! — das finde ich doch erheblich einleuchtender, als die beanstandete Kurzfassung (25.06.2013, 13:41):
“Messwerte beeinflussen sich nämlich wirklich gegenseitig“.
Ob sich, wenn manche (kurz) sagen, dass “eine Messung das Gemessene beeinflusst”, dahinter wohl ebenfalls etwas Nachvollziehbares verbirgt? …
> Ich meinte, dass es schwierig ist, die Temperatur innerhalb eines NMR-Röhrchens zu bestimmen.
Lässt sich das nicht vielleicht aus einer statistischen Bearbeitung der Messwert-Fits (natürlich einschl. aller “Ausreißenden”) ermitteln?
p.s.
> Schlechte Laune? Kann ich irgendetwas tun, dass es dir besser geht?
Danke; gleichfalls; das oben (25.06.2013, 09:00) erwähnte Histogramm (d.h. die erste Abbildung des Beitrags) wäre bestimmt besser/schneller/arbeitsteiliger editierbar, wenn es mit sowas wie “wp:fit” erstellt würde …
Yo, go for it, JIF!
Weil alle dagegen sind will ich doch noch etwas zur Verteidigung des JIF sagen, auch wenn Du mE weitgehend recht hast (hingegen nichts zur Begradigung bzw. Begnadigung von Kurven, meine statistischen Unkenntnisse sind ja bekannt…).
Nun denn, ausgehend von den Grafiken: Zurückgezogene 40 von 100000 Publikationen sind mE sehr wenig – man müsste eher mal reflektieren ob diese Nummer zu Recht so tief ist. Was die retraction index/JIF-Kurve anbelangt: Wir wissen ja dass Korrelation nichts mit Kausalität zu tun hat. Es ist wohl eher so dass Artikel mit hohen JIFs viel stärker beachtet werden. Nichts gegen FEMS Microbiology Letters, aber Publikationen da drin werden einfach viel weniger beachtet, und vor allem viel weniger kritisch – wenn ich irgendwo was lese und daran zweifle denke ich, naja, ist interessant, wirkt nicht so krassometer plausibel, aber ist ja FEBS Letters, gut dass ich das gesehen habe.
Und nun zum eigentlichen Punkt: Viele NatureScienceCell-Publikationen sind nicht über jeden Zweifel erhaben. Aber wenn da ein Paper drin ist, dann weiß ich, es hat eine gewisse Relevanz für das Forschungsfeld, und es ist sehr wahrscheinlich relativ wichtig und interessant. Der JIF erlaubt mir also eine gewisse Vorselektion basierend auf einem – natürlich zweifelhaften – Algorithmus. Es gibt mittlerweile soviele Journals, ich bin froh wenn ich beim durchscrollen meiner wöchentlichen “What’s new”-mails von NCBI gleich mal abchecken kann was mehr und was weniger relevant ist.
Daher, so wie es jetzt läuft mit dem JIF ist es nicht das gelbe vom Ei. Aber eine Klassierung von mehr oder weniger relevanten Journals ist nicht unsinnig.
Thema und Alternative?
Ich bin etwas verwundert, daß in den Kommentaren nur ueber Statistik diskutiert wird. War das Thema nicht ein anderes?
Zum Thema:
Ich stimme prinzipiell zu, daß die Verwendung des JIF als Bewertungssytem fuer die wissenschaftliche Leistungsfaehigkeit fehl am Platze ist.
Denn PhDs und Postdocs, die nach professoraler Anleitung aufwendige experimentelle Aufbauten entwickelt haben, welche aber nicht die erwuenschten Ergebnisse gebracht haben, stehen ploetzlich (fast) ohne Paper da. Sind sie deswegen automatisch schlechte Wissenschafter?
Mir selbst erging es so, daß eine “Konkurenzgruppe” etwas schneller war und die ihre Daten etwa 6 Wochen vor unserer -selbstgesetzten- Deadline rausbrachten.
Unsere Ergebnisse waren die gleichen. Danach wollte mein Chef die Sachen nicht mal mehr in einem “minderwertigen” Journal rausbringen. “Das saehe nicht so gut aus”, so sein Kommentar. Alles fuer die Katz, kein Paper. Danke.
Nun, genug geklagt.
Eine Frage haette ich aber dennoch: Was waere denn die Alternative, um eine große Menge an Bewerbern (fuer Jobs, Gelder, …) in einer vernuenftigen Zeit zu selektieren?
“Schicken Sie uns ihre 5 besten Paper”, waere eine Moeglichkeit. Aber bei 50 Bewerbern sind das ne Menge Paper, die zu lesen und -nach der Leistungsfaehigkeit des Autors- zu bewerten waeren.