

Von Wortlängen und Wortfrequenzen
BLOG: Bierologie

Nach Zipf soll dies ein Resultat davon sein, dass Kommunikation möglichst effizient ausgelegt sein soll, als Biologe würde man vermutlich einfach von einem Selektionsdruck der auf möglichst hohe Effizienz hin wirkt reden. Auf jeden Fall ist es relativ einleuchtend, dass Sprache effizient wird, wenn die am meisten benutzen Worte möglichst kurz sind. Darüber wie Sprache, ebenfalls durch die Häufigkeit der Verwendung, evolviert hatten wir ja schon mal gesprochen. In einem in PNAS veröffentlichten Artikel wurde jetzt ein etwas anderer Mechanismus zur Vorhersage von Wortlängen veröffentlicht.
Anstatt rein auf die Häufigkeit eines Wortes zu achten, haben sie sich den Informationsgehalt der Worte angeschaut. Die Idee dabei ist, dass es vorteilhaft ist längere Wörter zu benutzen, wenn dafür die Informationsdichte ebenfalls mit ansteigt. Das führt dann – wenn Länge und Informationsdichte regelmässig ansteigen – dazu, dass die Rate mit der Informationen übertragen werden konstant bleibt. „Aufmerksamkeitsdefizitsyndrom“ (noch da?) benötigt zwar mehr Zeit zur Aussprache, sollte aber – im Idealfall – auch mehr Informationen übertragen als ein einfaches „Ja“. Und dazu, dass die Informationsrate relativ konstant ist, gibt es wohl bereits Hinweise.
Um jetzt zu überprüfen ob der Informationsgehalt mit der Länge zusammenhängt, hat man in der PNAS-Veröffentlichung ein mathematisches Modell gebastelt, in dem der Informationsgehalt eines Worts aus dem Kontext in dem er steht berechnet wird (In wie weit das Modell aussagekräftig und vernünftig ist kann ich leider nicht beurteilen, aber vielleicht kann ein eventuell mitlesender Linguist dabei helfen, hier gibt es mehr Details dazu). Dieses Modell haben sie dann mit einem Korpus von Google getestet. So weit ich das sehen kann allerdings nicht mit dem riesigen Korpus den die Culturomics-Leute verwendet haben.
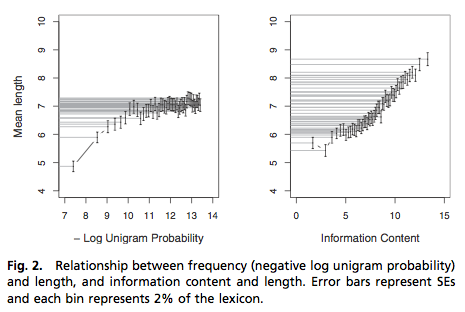
Aber kommen wir zum spannenden Teil: Wie man in der linken Grafik sehen kann, funktioniert Zipfs Methode, der Vergleich von Frequenz mit Länge, gerade für geringere Frequenzen und steigende Länge nicht mehr. Schaut man sich hingegen die Länge in Abhängigkeit von dem berechneten Informationsgehalt im rechten Teil an, dann klappt das mit der Korrelation schon viel besser. Getestet haben sie ihr Modell dann neben Englisch auch noch für eine handvoll anderer Sprachen und die Ergebnisse sind, mal mehr mal weniger, vergleichbar.
Wenn ihr euch also mal wieder über viel zu lange Wörter, bei denen man sich verhaspelt, ärgert: Denkt dran, sie sind vermutlich schon auf den Datendurchsatz optimiert. Es könnte also viel schlimmer sein.
Grafik: Aus der Veröffentlichung
Piantadosi ST, Tily H, & Gibson E (2011). From the Cover: Word lengths are optimized for efficient communication. Proceedings of the National Academy of Sciences of the United States of America, 108 (9), 3526-9 PMID: 21278332
![]()
Mir fällt grade noch was auf…
…das muss sich doch signifikant unterscheiden zwischen unterschiedlichen Sprachen: Nehmen wir Deutsch und Englisch.
Die Funktionalität der Sprachen in puncto Wortlänge ist einfach sehr verschieden: Im Englischen neigt man dazu, die Wörter (nöglicherweise durch ein “of” getrennt) auseinanderzuschreiben, im Deutschen klebt man die Substantive einfach aneinander an.
Obwohl der Satz also insgesamt durchaus gleich lang sein kann, sind die Wörter im Englischen kürzer aber dafür auch mehr.
Lange Rede kurzer Sinn: Statt Wortlänge scheint mir eher Wortlänge * Anzahl der Wörter sinnvoll zu sein.
Da hast du nicht ganz unrecht, glaube ich. Die Korrelation ist ja sowohl von Sprache zu Sprache als auch von den betrachteten ngrams (also Länge der betrachteten Wörter) unterschiedlich stark ausgeprägt.
Im Englischen ist die Korrelation von Informationsgehalt mit Länge bei 2grams gering, bei 4grams bereits viel stärker.
Im deutschen ist die Korrelation sowohl bei 2grams als auch bei 4grams fast gleichstark ausgeprägt. Leider sind in der Publikation für längere ngrams keine Werte angegeben.
Aber spricht das nicht nur auch dafür, dass die Länge und Frequenz nicht zwingend direkt verbunden sind? Wenn man jetzt Kombinationen im englischen über Bindestriche oder ” of ” herstellt, dann ist der Informationsgehalt ja vom Kontext abhängig (also auch von der Umgebung in der sie stehen).
Stimmt
Stimmt.
Ist halt auch nur ein relativ simples Modell; in der Praxis sieht das wohl komplexer aus, und ist es vorallem stark abhängig von der Sprache und auch der Sprachbenutzung (Militärsprache, Umgangssprache, Literatur, …)
Im Englischen klebt man die Wörter auch aneinander, nur werden die Komposita inzwischen nicht mehr so eifrig mit Bindestrichen durchgekoppelt (prime time statt prime-time), was dann zu dem Eindruck führt, es handelte sich um mehrer Wörter. Der Unterschied liegt aber nur im Orthografischen.
‘Attention deficit hyperactivity disorder’ ist ein einziges Determinativkompositum, genau wie ‘Aufmerksamkeitsdefizitsyndrom’. Das gilt eigentlich auch für ‘freedom of speech’ vs. ‘Meinungsfreiheit’. Da sollte man besser von Ausdruck als von Wort sprechen.